Hadoop文件存储系统-HDFS详解以及java编程实现
前言
这是关于Hadoop的系列文章。
Hadoop基本概念指南
Eclipse搭建Hadoop开发环境二三事
IntelliJ IDEA搭建Hadoop开发环境
Hadoop文件存储系统-HDFS详解以及java编程实现
背景
我们在本系列的第一篇文章的时候就谈到过,面对海量数据,我们最为缺乏的就是对大数据量的存储能力以及处理能力。而这两种能力在Hadoop的体现分别就是HDFS以及map-reduce。今天,我们就来看看Hadoop为我们带来的这个分布式文件系统。
猜想
实际上,我们在未能接触HDFS之前可以猜测一些它会是什么样子的?现有的linux文件系统也很好用,所以我们猜想,它也将会保留一部分的当前文件系统的特性,比如说采取目录的方式、linux的一些命令的保留、甚至于说一些常用的指令的完全兼容,当然,我觉得一定也会有新的东西的加入。比如说对于分布式的支持,我们在第一篇文章其实有谈到过HDFS在存储的时候的几个角色。NameNode负责文佳信息的索引,而DataNode则负责处理数据的实际存储。当然,这里的模型只是简化的处理模型,但其实我们如果只是使用HDFS的话,我们不care这样的细节。
HDFS为我们带来了什么?
HDFS为我们的实际业务应用带来的最强大的能力应该就是对于大数据量的存储能力,而且这种能力的获得并没有让我们的业务的复杂性提高,也就是说分布式的存储对于我们而言是透明的,这是我们所希望看到的。正因为如此,它才显得非常的简单易用。因为我们可以把我们的注意力一致的集中在我们的存储上,而不是该怎么去协调节点间的数据,该怎么去防止数据丢失。可以说,HDFS为我们带来了简单易用的分布式存储。而且他和普通的文件系统在别的方面并无二致。
编程实现
我们知道,任何程序同文件系统之间的操作都离不开IO,而这些交互的主要无非就集中在如下的几点,那么我们就可以来看到我们需要做的事情:
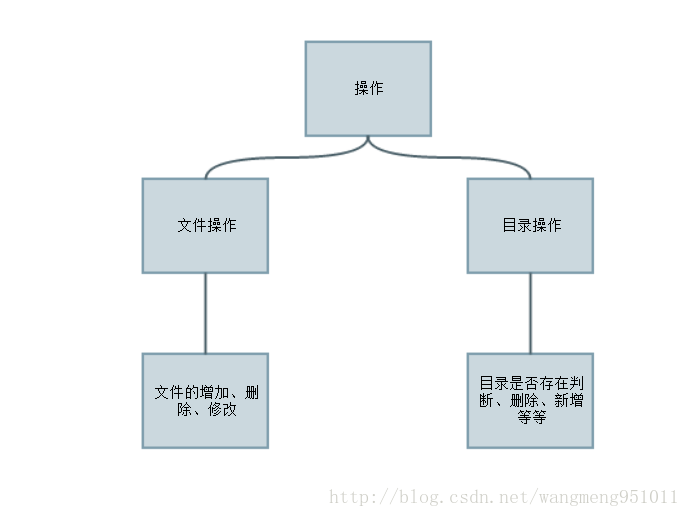
好了,那下面就让我们愉快的开始写代码吧?我们首先需要搞清楚的是我们需要依赖的jar,如下所示:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.6.1version>
dependency>好了,看完了依赖,我们接下来就是要开始我们的代码编写了。我们查找到FileSystem这个类是最为最重要的一个类。我们点进去看看注释:
/****************************************************************
* An abstract base class for a fairly generic filesystem. It
* may be implemented as a distributed filesystem, or as a "local"
* one that reflects the locally-connected disk. The local version
* exists for small Hadoop instances and for testing.
*
*
*
* All user code that may potentially use the Hadoop Distributed
* File System should be written to use a FileSystem object. The
* Hadoop DFS is a multi-machine system that appears as a single
* disk. It's useful because of its fault tolerance and potentially
* very large capacity.
*
*
* The local implementation is {@link LocalFileSystem} and distributed
* implementation is DistributedFileSystem.
*****************************************************************/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class FileSystem extends Configured implements Closeable {这是一个抽象类,无法实例化。上面的注释的大意是Hadoop的HDFS是一个分布式文件系统,想要在这个文件系统上用java做点事情,就必须使用这个类。然后我们继续往下看。
/**
* Get a filesystem instance based on the uri, the passed
* configuration and the user
* @param uri of the filesystem
* @param conf the configuration to use
* @param user to perform the get as
* @return the filesystem instance
* @throws IOException
* @throws InterruptedException
*/
public static FileSystem get(final URI uri, final Configuration conf,
final String user) throws IOException, InterruptedException {
String ticketCachePath =
conf.get(CommonConfigurationKeys.KERBEROS_TICKET_CACHE_PATH);
UserGroupInformation ugi =
UserGroupInformation.getBestUGI(ticketCachePath, user);
return ugi.doAs(new PrivilegedExceptionAction() {
@Override
public FileSystem run() throws IOException {
return get(uri, conf);
}
});
}
/**
* Returns the configured filesystem implementation.
* @param conf the configuration to use
*/
public static FileSystem get(Configuration conf) throws IOException {
return get(getDefaultUri(conf), conf);
}
/** Get the default filesystem URI from a configuration.
* @param conf the configuration to use
* @return the uri of the default filesystem
*/
public static URI getDefaultUri(Configuration conf) {
return URI.create(fixName(conf.get(FS_DEFAULT_NAME_KEY, DEFAULT_FS)));
}
/** Set the default filesystem URI in a configuration.
* @param conf the configuration to alter
* @param uri the new default filesystem uri
*/
public static void setDefaultUri(Configuration conf, URI uri) {
conf.set(FS_DEFAULT_NAME_KEY, uri.toString());
}
/** Set the default filesystem URI in a configuration.
* @param conf the configuration to alter
* @param uri the new default filesystem uri
*/
public static void setDefaultUri(Configuration conf, String uri) {
setDefaultUri(conf, URI.create(fixName(uri)));
} 我们可以看的很清楚的是其提供了多个静态方法供我们使用,然后我们就可以采取其中的某一个方法得到一个这个抽象类的实例。当然,我们要选就选择最简单的。只需要一个conf的那个方法。于是,我们现在就可以开始写程序了!最后完成的成果如下:
package com.weomob.hadoop.com.henry.hadoop.hdfs;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.output.ByteArrayOutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
/**
* hdfs util 接口
* 用户:hadoop
* 日期:6/6/2017
* 时间:9:32 PM
*/
@Slf4j
public class HDFSUtil {
/**
* 新建文件
*
* @param configuration
* @param filePath
* @param data
* @throws IOException
*/
public static void createFile(Configuration configuration, String filePath, byte[] data) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(filePath));
fsDataOutputStream.write(data);
fsDataOutputStream.close();
fileSystem.close();
}
/**
* 创建文件夹
*/
public static void mkDirs(Configuration configuration, String filePath) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.mkdirs(new Path(filePath));
fileSystem.close();
}
/**
* 删除文佳 true 为递归删除 否则为非递归
*/
public static void deleteFile(Configuration configuration, String filePath, boolean isReturn) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
boolean delete = fileSystem.delete(new Path(filePath), isReturn);
if (!delete) {
throw new RuntimeException("删除失败");
}
log.error("wocao");
fileSystem.close();
}
/**
* 读取文件内容
*
* @author fulei.yang
*/
public static String readFile(Configuration conf, String filePath)
throws IOException {
String res = null;
FileSystem fs = null;
FSDataInputStream inputStream = null;
ByteArrayOutputStream outputStream = null;
try {
fs = FileSystem.get(conf);
inputStream = fs.open(new Path(filePath));
outputStream = new ByteArrayOutputStream(inputStream.available());
IOUtils.copyBytes(inputStream, outputStream, conf);
res = outputStream.toString();
} finally {
if (inputStream != null)
IOUtils.closeStream(inputStream);
if (outputStream != null)
IOUtils.closeStream(outputStream);
}
return res;
}
/**
* 从本地上传文件到HDFS
*
* @param configuration
* @throws IOException
*/
public static void uploadFile(Configuration configuration, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.copyFromLocalFile(new Path(localFilePath), new Path(remoteFilePath));
fileSystem.close();
}
/**
* 判断目录是否存在
*/
public static boolean fileExists(Configuration configuration, String filePath) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
return fileSystem.exists(new Path(filePath));
}
}
欧漏,这和我们上面说画的图几乎别无二致,当然,还有更多的可用方法大家可以去探寻。这是非常有意思的一个过程。
总结
通过这篇文章我们主要是想传达HDFS是一个分布式的文件系统,但是他的分布式的特性被Hadoop的开发者巧妙的隐藏了。也就是对于我们而言几乎是透明的,我们只需要拿到我们想要的东西,按照一个使用普通文件系统的方式去使用它即可。
当然,我们还重点的写了一个简单的client,这样的话,我们就可以写入东西到集群和从集群读取文件了。