以下想说一说:
1.Flume是什么,还有他的历史
2.Flume的应用场景,能解决我们什么问题
3.我在使用flume的过程中,走过的坑
我不想谈的是:
1.Flume如何使用
2.Flume的定制开发
把不想谈的东西变作思路,盈盈绕绕,只回过头谈谈对它的理解和走过的坑吧。

No.1 是什么,哪儿来的
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、HBase等)的能力 。
Flume在Cloudera 2011年发布的CDH3中首次被引入。在2011年6月,Cloudera将Flume项目控制权移交给了Apache基金会。一年后它以孵化项目的形式出现。在孵化的时间里,重构Flume的工作开始展开,即FlumeNG(Flume的下一代),最终发展为Flume 1.X开发的主分支。
来看一看flume官方的版本情况:
可以看出曾经的0.9x版本已经不复存在,所以这里只谈谈1.x版本的Flume吧,也就是说,请忘记Cloudera Flume,记住Apache Flume。
No.2 什么时候开始知道它,想起它,并且使用它
我一直觉得,对一种技术解决方案,在业务需求没逼迫到一定程度之前,可能就无法透彻理解。
各位大数据攻城狮在攀爬大数据技术栈的过程中,首先翻过的应该是hadoop这个基石。那么在上古洪荒时期,攻城狮如何通过Hadoop(HDFS)放入数据?很简单:
hadoop fs --put xxx
当你的数据都整齐的清洗好、打包好并准备上传时,这种方式是ok的。
但现实往往事与愿违,工作中接触到的数据业务,通常在不断的产生,那么我一定会想在第一时间拿到数据并清洗完成。
可喜可贺Flume提供了一套数据流式作业采集端的解决方案。

在看到上面这张图后,请牢记这几个关键词语:
Agent、Source、Channel、Sink、Event
可以说它们组成了Flume最基本的处理单元,值得欣慰的是,apache与cloudera并没有把Flume的数据处理模式变得抽象化,一条流水线就足以表达数据的处理走向。
当然Flume的处理流程是可以总结成文字的,请静静地默念以下绕口令:
一个source传输多个event到一或多个channel中;
一个channel是event从source传输到sink的缓冲区;
一个sink只可以从一个channel中接收多个event;
一个agent可以有多个source、channel和sink。
耐心解释一下:
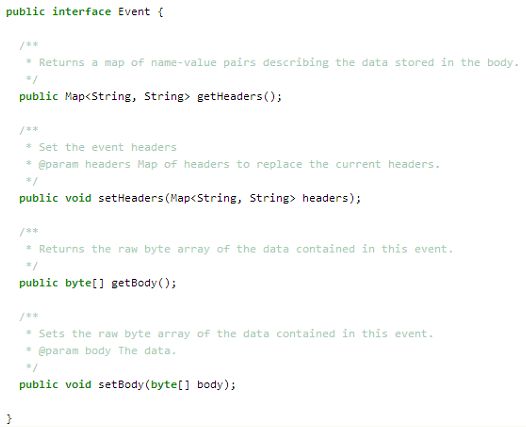
Event:Flume的数据基本单元,由body和header组成。body是我们实际使用中真正传输的数据,header所携带的数据,一般是不会sink到存储系统中的。在理解event方面,只要记住它的数据结构即可,其他解释都显得多余而苍白。

Source:从数据发生端接收数据,并将接收的数据以event形式传递给一个或者多个管道(channel)。Flume本身可支持的接收方式种类很可观:

Flume1.7版本官方文档所表明支持的数据接收种类
这里想说的是,Flume的各项配置离不开官方文档,Flume的文档大概是各种大数据工具中,最容易读懂并应用的说明了,结合我实际工作中的体会,翻查Flume文档的频率完全可以让你背下来其中的user guide大半内容。
Channel:承上启下的作用,上面source接收的数据都被缓冲在了这里,你甚至可以把它理解为一个消息队列。当然,它并不十分可靠、稳定,在玩转Flume过程中踩过的坑中,channel的问题是让我最头痛的。这个坑儿后面说。
Sink:从channel中获得数据,数据流向终点,有些时候,也可能是个起点。
Agent:上面的source、channel、sink共同组成了一个agent。
No.3 走过的坑
其实写了这么多,真正想记录的是下面的坑。
如果看过我之前的《数据架构设计浅谈》一文,应该知道在搭建大数据平台之前,我们业务数据的接收方式各种各样五花八门,这其中存在一个很沉重的数据接收形式就是采集实体文件。
当你看过Flume的文档,大概很容易想到Flume提供的一种source:Spooling Directory Source
如果你想把Spooling Directory Source用到生产环境,我劝你一定要打住,它一定会带来生产灾难。只列出两个致命问题:
1.休想通过一个非iso8859-1编码的字符
2.绝不用正确姿势读取正在写入的文件,分分钟阻塞给你看
给出两个解决思路:
1.祭出强大的exec source,写上一句for i in /path/*.txt; do cat $i; done
2.写一个避免上面两点的读文件自定义sink(要感谢Flume对开发人员友好的自定义特性)
Spooling Directory Source说完,说说Kafka Source,说到这里,要谈谈Kafka的里程碑式版本变化,kafka 0.8x与kafka 0.9x,还有目前最新的kafka 0.10X,无论从文档、api、还是shell命令等方面看,都是前一版本的大跃进,这就导致Flume的kafka source对kafka消息队列的适配工作不甚理想。从走过的坑总结来看,得出一下结论:
1.Flume的Kafka Source、Kafka Channel、Kafka Sink,在其1.6版本中,支持Kafka 0.8x版本与其之前版本的数据对接,不支持其后的版本。
2.在其1.7版本中,支持Kafka 0.9x、0.10x版本的数据对接,不支持之前的版本。
Channel方面,我们配置的memory channel在最初的日均百万级数据下,并没有出现什么明显问题,在提升数据量级的过程中,发现在日均千万的量级下,存在严重丢失数据的问题,在尝试调节memory capacity等参数均失败的结果下,转而采用了file channel,效果喜人,千万级数据没发现问题,并且性能没有想象的那么差。然而没多久我们的数据量级上升到了日均1亿左右,在反复实验调试file channel后,确认file channe也出现了当初严重丢失数据的情况。走投无路之下,想到了Flume1.7版本支持kafka channel。
kafka channel的本质其实就是file channel,只不过借助了kafka独特的顺序存储特性,使其性能暴涨。在试验了kafka channel后,结果喜人,在目前日均2亿以上的数据量级中,经受住了考验。
这里可能有人想说一下Spillable Memory Channel,我想说的是,虽然它的思路很好,在memory灌满的情况下使用file缓冲,但它也同时保留了memory channel和file channel的缺点,我个人不建议在海量级数据的生产环境使用。
Sink方面,说说HDFS sink,多数情况下可能你会想以数据块大小来分割文件,如果你想要你的rollSize参数生效,请把minBlockReplicas值调为1,这个文档中也没有说明,实在是让人迷惑。
在1.6的版本中,还有一个让人头疼的bug,就是parseAsFlumeEvent与useFlumeEventFormat两个参数设置无效的问题。如果你有第三方消费kafka channel和kafka sink的需求,这个小bug会让你的工作量上升不少,所以这里十分推荐使用1.7版本。
如果你想初步清洗数据,请尽量在拦截器端完成,而不是自定义source、sink,甚至是自定义channel。无论是调试、更改,这都是明智的。
在自定义开发与修改配置均解决无望的情况下,随手cat一下flume-env.properties文件,看看里面的jdk版本,也许会有惊喜。
Flume也是可以做分布式高可用部署的,在0.9x的版本时代,这是必选配置,以至于现在我们经常忘记它的这一特性。
No.4 写在最后
以上生产环境以《数据架构设计浅谈》一文中为背景。
上面虽然提及了很多在使用Flume产生的很多问题,但基于Flume强大又友好开放的自定义开发特性,绝大多数问题都可以通过自定义开发而避免。最后希望此文给啃食大数据技术栈的人们一点启发和帮助。