Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,
Selenium可以根据我们的指令,让浏览器自动加载页面,获取需要的页面,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所有我们而已用一个叫PhantomJS的工具代替真实的浏览器。
PhantomJS是一个基于Webkit的"无界面"(headless)浏览器,它会把网站加载到内存并执行页面上的JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器更高效。
如果我们把Selenium和PhantomJS结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理JavaScript、Cookie、headers,以及任何我们真实用户需要做的事情。
注意:PhantomJS只能从它的网站(http://phantomjs.org/download.html)下载。因为PhantomJS是一个功能完善(虽然无界面)的浏览器而非一个Python库,所以它不需要像Python的其它库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用
PhantomsJS官方才考文档:http://phantomjs.org/documention
Selenium和PhantomJS 拓展详解


导入webdriver---->from selenium import webdriver
调用环境变量指定的phantomjs浏览器创建浏览器对象
driver=webdriver.PhantomJs()
如果没有在坏境变量指定phantomjs位置则:driver=webdriver.PhantomJs(executable_path='./phantomJs'))
get方法会一直等到页面完全加载完,才会继续执行程序,通常测试会在这里选择time.sleep()
driver.get('http://www.baidu.com/')
Selenium详解
安装:pip3 install selenium
http://phantomjs.org/download.html
selenium用法详解
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行
(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core
基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候
一、声明浏览器对象
注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入
from selenium import webdriver
#webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例
browser = webdriver.Chrome()
二、访问页面并获取网页html
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)#browser.page_source是获取网页的全部html
browser.close()
三、查找元素
单个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first,input_second,input_third)
browser.close()
常用的查找方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
也可以使用通用的方法
from selenium import webdriver
from selenium.webdriver.common.by import By ---这里需要记住By模块所以需要导入
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(BY.ID,'q')#第一个参数传入名称,第二个传入具体的参数
print(input_first)
browser.close()
多个元素,elements多个s
input_first = browser.find_elements_by_id('q')
四、元素交互操作-搜索框传入关键词进行自动搜索
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')#找到搜索框
input.send_keys('iPhone')#传送入关键词
time.sleep(5)
input.clear()#清空搜索框
input.send_keys('男士内裤')
button = browser.find_element_by_class_name('btn-search')#找到搜索按钮
button.click()
更多操作: http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement#可以有属性、截图等等
五、交互动作,驱动浏览器进行动作,模拟拖拽动作,将动作附加到动作链中串行执行
from selenium import webdriver
from selenium.webdriver import ActionChains#引入动作链
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')#切换到iframeResult框架
source = browser.find_element_by_css_selector('#draggable')#找到被拖拽对象
target = browser.find_element_by_css_selector('#droppable')#找到目标
actions = ActionChains(browser)#声明actions对象
actions.drag_and_drop(source, target)
actions.perform()#执行动作
更多操作: http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
六、执行JavaScript
有些动作可能没有提供api,比如进度条下拉,这时,我们可以通过代码执行JavaScript
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
七、获取元素信息
获取属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')#获取网站logo
print(logo)
print(logo.get_attribute('class'))
browser.close()
获取文本值
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)#input.text文本值
browser.close()
# 获取Id,位置,标签名,大小
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)#获取id
print(input.location)#获取位置
print(input.tag_name)#获取标签名
print(input.size)#获取大小
browser.close()
八、Frame操作
frame相当于独立的网页,如果在父类网frame查找子类的,则必须切换到子类的frame,子类如果查找父类也需要先切换
这里常用的是switch_to.from()和switch_to.parent_frame()
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
print(source)
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
九、等待
隐式等待
当使用了隐式等待执行测试的时候,如果 WebDriver没有在 DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常,
换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是0
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)#等待十秒加载不出来就会抛出异常,10秒内加载出来正常返回
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
显式等待
指定一个等待条件,和一个最长等待时间,程序会判断在等待时间内条件是否满足,如果满足则返回,如果不满足会继续等待,超过时间就会抛出异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert
详细内容:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
十一、前进后退-实现浏览器的前进后退以浏览不同的网页back()和forward()
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
十二、Cookies操作
get_cookies()
delete_all_cookes()
add_cookie()
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
选项卡管理 增加浏览器窗口
通过执行js命令实现新开选项卡window.open()
不同的选项卡是存在列表里browser.window_handles
通过browser.window_handles[0]就可以操作第一个选项卡
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('http://www.fishc.com')
十三、异常处理
这里的异常比较复杂,官网的参考地址:
http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
这里只进行简单的演示,查找一个不存在的元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.find_element_by_id('hello')
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
# 详细文档:http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
这里我们运用PhantomJS爬取全国高校查询计算机科学与技术专业前50的学校,并且存入到数据库。
如下图所示
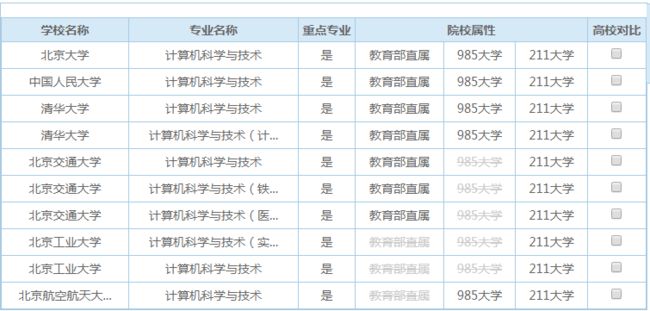
对重点专业:是、否进行处理
教育部直属、985大学、211大学标签使用beautiful soup 进行处理
代码如下
1 # -*- coding:utf-8 -*- 2 # author:zxy 3 # date:2019-2-5 4 5 from bs4 import BeautifulSoup 6 from selenium import webdriver 7 import re 8 from c_Study import conn 9 10 11 def main(): 12 driver_path = r'C:\Program Files\phantomjs-2.1.1-windows\bin\phantomjs.exe' 13 driver = webdriver.PhantomJS(executable_path=driver_path) 14 for i in range(1, 6, 1): 15 url = 'https://gkcx.eol.cn/soudaxue/querySchoolSpecialty.html?&argspecialtyname=%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6%E4%B8%8E%E6%8A%80%E6%9C%AF&argzycengci=%E6%9C%AC%E7%A7%91&page=' \ 16 + str(i) 17 driver.get(url) 18 data = driver.page_source 19 dfcontent = BeautifulSoup(data, 'lxml') 20 trs = dfcontent.find_all('tr')[1:] 21 for tr in trs: 22 college_name = tr.find_all('td')[0].string # 大学名称 23 college_major = tr.find_all('td')[1].string # 专业名称 24 major_isKey = tr.find_all('td')[2].string # 是否重点专业 25 if major_isKey == "是": 26 major_isKey = 1 27 elif major_isKey == '否': 28 major_isKey = 0 29 is_direct = tr.find_all('td')[3] # 是否教育部直属 30 if is_direct.find(attrs={'style': re.compile('.*?#CCCCCC;.*?')}): 31 is_direct = 0 32 else: 33 is_direct = 1 34 is_985 = tr.find_all('td')[4] # 是否985大学 35 if is_985.find(attrs={'style': re.compile('.*?#CCCCCC;.*?')}): 36 is_985 = 0 37 else: 38 is_985 = 1 39 is_211 = tr.find_all('td')[5] # 是否211大学 40 if is_211.find(attrs={'style': re.compile('.*?#CCCCCC;.*?')}): 41 is_211 = 0 42 else: 43 is_211 = 1 44 45 conn.insert_into_db('colleges', college_name, college_major, major_isKey, is_direct, is_direct, is_211) 46 if __name__ == '__main__': 47 main()
1 # -*- coding:utf-8 -*- 2 # author:zxy 3 # Date:2019-2-5 4 # Update: 5 import pymysql 6 7 8 9 def insert_into_db(dbname,*args): 10 db = pymysql.Connect("localhost", 'root', 'pwd', "dbname") 11 sql = "insert into "+dbname+"(name, major, major_isKey, is_direct,is_985,is_211) values (%s, %s, %s, %s, %s, %s);" 12 cur = db.cursor() 13 try: 14 cur.execute(sql, args) 15 db.commit() 16 except: 17 db.rollback()
结果如下所示:
