Java8 Stream API介绍
Stream API是Java8中处理集合的关键组件,提供了各种丰富的函数式操作。
Stream的创建
任何集合都可以转换为Stream:
//数组
String[] strArr = new String[]{"aa","bb","cc"};
Stream<String> streamArr = Stream.of(strArr);
Stream<String> streamArr2 = Arrays.stream(strArr);
//集合
List<String> list = new ArrayList<>();
Stream<String> streamList = list.stream();
Stream<String> streamList2 = list.parallelStream();//并行执行
...
//generator 生成无限长度的stream
Stream.generate(Math::random);
// iterate 也是生成无限长度的Stream,其元素的生成是重复对给定的种子值调用函数来生成的
Stream.iterate(1, item -> item + 1)
Stream的简单使用
Stream的使用分为两种类型:
Intermediate,一个Stream可以调用0到多个Intermediate类型操作,每次调用会对Stream做一定的处理,返回一个新的Stream,这类操作都是惰性化的(lazy),就是说,并没有真正开始流的遍历。
常用操作:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallelTerminal,一个Stream只能执行一次terminal 操作,而且只能是最后一个操作,执行terminal操作之后,Stream就被消费掉了,并且产生一个结果。
常用操作:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny
使用示例:
/********** Intermediate **********/
//filter 过滤操作
streamArr.filter(str -> str.startsWith("a"));
//map 遍历和转换操作
streamArr.map(String::toLowerCase);
//flatMap 将流展开
List<String> list1 = new ArrayList<>();
list1.add("aa");list1.add("bb");
List<String> list2 = new ArrayList<>();
list2.add("cc");list2.add("dd");
Stream.of(list1,list2).flatMap(str -> str.stream()).collect(Collectors.toList());
//limit 提取子流
streamArr.limit(1);
//skip 跳过
streamArr.skip(1);
//peek 产生相同的流,支持每个元素调用一个函数
streamArr.peek(str - > System.out.println("item:"+str));
//distinct 去重
Stream.of("aa","bb","aa").distinct();
//sorted 排序
Stream.of("aaa","bb","c").sorted(Comparator.comparing(String::length).reversed());
//parallel 转为并行流,谨慎使用
streamArr.parallel();
/********** Terminal **********/
//forEach
streamArr.forEach(System.out::println);
//forEachOrdered 如果希望顺序执行并行流,请使用该方法
streamArr.parallel().forEachOrdered(System.out::println);
//toArray 收集到数组中
streamArr.filter(str -> str.startsWith("a")).toArray(String[]::new);
//reduce 聚合操作
streamArr.reduce((str1,str2) -> str1+str2);
//collect 收集到List中
streamArr.collect(Collectors.toList());
//collect 收集到Set中
streamArr.collect(Collectors.toSet());
//min 取最小值?
IntStream.of(1,2,3,4).min();
Stream.of(arr).min(String::compareTo);
//max 取最大值?
IntStream.of(1,2,3,4).max();
Stream.of(arr).max(String::compareTo);
//count 计算总量?
streamArr.count();
//anyMatch 判断流中是否含有匹配元素
boolean hasMatch = streamArr.anyMatch(str -> str.startsWith("a"));
//allMatch 判断流中是否全部匹配
boolean hasMatch = streamArr.allMatch(str -> str.startsWith("a"));
//noneMatch 判断流中是否全部不匹配
boolean hasMatch = streamArr.noneMatch(str -> str.startsWith("a"));
//findFirst 找到第一个就返回
streamArr.filter(str -> str.startsWith("a")).findFirst();
//findAny 找到任意一个就返回
streamArr.filter(str -> str.startsWith("a")).findAny();收集结果
collect操作主要用于将stream中的元素收集到一个集合容器中,collect函数的定义如下:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);第一个参数Supplier用于生成一个目标集合容器类型的实例;
函数BiConsumer
Set result = Stream.of("aa", "bb", "cc", "aa").collect(
() -> new HashSet(),
(set, item) -> set.add(item),
(set, subSet) -> set.addAll(subSet)); 以上写法可以使用操作符“::”简化,语法如下:
- 对象::实例方法
- 类::静态方法
- 类::实例方法
Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(
HashSet::new,
HashSet::add,
HashSet::addAll);java.util.stream.Collectors类中已经预定义好了toList,toSet,toMap,toCollection等方便使用的方法,所以以上代码还可以简化如下:
Set result2 = Stream.of("aa", "bb", "cc", "aa").collect(Collectors.toSet()); 将结果收集到Map中,Collectors.toMap方法的两个重载定义如下:
- keyMapper函数用于从实例T中得到一个K类型的Map key;
- valueMapper函数用于从实例T中得到一个U类型的Map value;
- mergeFunction函数用于处理key冲突的情况,默认为throwingMerger(),抛出IllegalStateException异常;
- mapSupplier函数用于生成一个Map实例;
public static
Collector> toMap(Functionsuper T, ? extends K> keyMapper,
Functionsuper T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static extends Map>
Collector toMap(Functionsuper T, ? extends K> keyMapper,
Functionsuper T, ? extends U> valueMapper,
BinaryOperator mergeFunction,
Supplier mapSupplier) {
BiConsumer accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
} 假设有一个User实体类,有方法getId(),getName(),getAge()等方法,现在想要将User类型的流收集到一个Map中,示例如下:
Stream<User> userStream = Stream.of(new User(0, "张三", 18), new User(1, "张四", 19), new User(2, "张五", 19), new User(3, "老张", 50));
Map<Integer, User> userMap = userSteam.collect(Collectors.toMap(User::getId, item -> item));假设要得到按年龄分组的Map>,可以按这样写:
Map<Integer, List<User>> ageMap = userStream.collect(Collectors.toMap(User::getAge, Collections::singletonList, (a, b) -> {
List<User> resultList = new ArrayList<>(a);
resultList.addAll(b);
return resultList;
}));这种写法虽然可以实现分组功能,但是太过繁琐,好在Collectors中提供了groupingBy方法,可以用来实现该功能,简化后写法如下:
Map<Integer, List<User>> ageMap2 = userStream.collect(Collectors.groupingBy(User::getAge));类似的,Collectors中还提供了partitioningBy方法,接受一个Predicate函数,该函数返回boolean值,用于将内容分为两组。假设User实体中包含性别信息getSex(),可以按如下写法将userStream按性别分组:
Map> sexMap = userStream.collect(Collectors.partitioningBy(item -> item.getSex() > 0)); Collectors中还提供了一些对分组后的元素进行downStream处理的方法:
- counting方法返回所收集元素的总数;
- summing方法会对元素求和;
- maxBy和minBy会接受一个比较器,求最大值,最小值;
- mapping函数会应用到downstream结果上,并需要和其他函数配合使用;
Map<Integer, Long> sexCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.counting()));
Map<Integer, Integer> ageCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.summingInt(User::getAge)));
Map<Integer, Optional<User>> ageMax = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.maxBy(Comparator.comparing(User::getAge))));
Map<Integer, List<String>> nameMap = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.mapping(User::getName,Collectors.toList())));以上为各种collectors操作的使用案例。
Optional类型
Optional 是对T类型对象的封装,它不会返回null,因而使用起来更加安全。
ifPresent方法接受一个函数作为形参,如果存在当前Optinal存在值则使用当前值调用函数,否则不做任何操作,示例如下:
Optional<T> optional = ...
optional.ifPresent(v -> results.add(v));orElse方法,orElseGet方法,当值不存在时产生一个替代值,示例如下:
String result = optional.orElse("defaultValue");
String result = optional.orElseGet(() -> getDefalutValue());可以使用Optional.of()方法和Optional.empty()方法来创建一个Optional类型对象,示例如下:
a - b > 0 ? Optional.of(a - b) : Optional.empty();函数式接口
Steam.filter方法接受一个Predicate函数作为入参,该函数返回一个boolean类型,下图为Stream和COllectors方法参数的函数式接口:
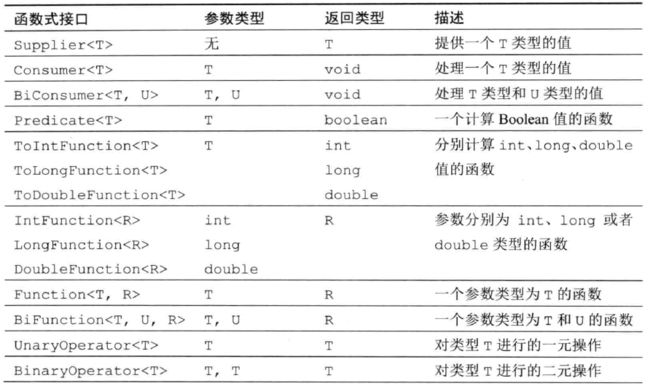
总结
- Stream的处理总会在最后的Terminal操作才会真正执行;
- 没有内部存储,也不能改变使用到的数据源,每次操作都会生成一个新的流;
- 并行流使用fork/join 池来实现,对于非CPU密集型任务,需要谨慎使用;
- 相对于循环遍历操作代码可读性更高;