小白也能玩转Kubernetes 你与大神只差这几步
随着Kubernetes技术热度的不断提升,大容器时代的序幕已经开启。容器技术日新月异,在企业应用实践中得到了不断的发展,高效的运维、管理和部署都成为云服务的重头戏。而与此同时,Kubernetes虽然降低了容器的使用门槛,但其本身的技术门槛却并不低,这种矛盾引起了开发者的关注,也成功在2018年将Kubernetes推到了顶峰。
\\6月30日,腾讯云联合InfoQ举办的云+社区技术沙龙,以Kubernetes 上云一键部署、云上大规模计算平台构建、CIS底层技术实现、Tencent Hub技术架构与DevOps落地实践等五大主题内容,分享容器与k8s技术的部署优化与应用实践。本文整理了讲师演讲精彩内容,感兴趣的读者可以点击【阅读原文】下载讲师演讲资料。
\\Kubernetes 上云一键部署实践
\\在2016年底,腾讯云开始提供全托管Kubernetes服务,主要提供了四个方面的功能,第一,一键部署完全隔离的Kubernetes服务,用户独享所有结算节点和控制节点,并提供集群的全生命周期管理;第二,为方便Kubernetes使用,在控制台进行了界面包装,通过可视化的方式创建负载,避免手工编写代码;第三,提供周边监控能力,与腾讯云监控产品打通,直接在产品界面上使用;第四,在Kubernetes集群外还提供了Docker镜像仓库、Tencent Hub、CI/CD等功能,提供一站式应用上云解决方案。
\\腾讯云容器服务 Kubernetes 组件一览
\\Kubernetes的运行需要进行Master组件和Node组件的初始化。
\\Master组件最简单的部署要包括Kube-apiserver、Kube-contioller-mannager和kube-scheduler。Kube-apiserver是整个集群的集中存储器,其功能包括了所有组件与Kubernetes的交互、部分工作负载的存储、部分用户对存储的需求。Kube-controller-manager主要负工作负载在集群里的运行;Kube-scheduler主要负责pod的调度,如所在的运行机器、调度到集群含GPU的节点等调度工作。
\\集群的Master组件部署好后就需要部署一些 Node,主要包括两个组件, 第一个是负责在Node上创建Pod的kubelet;第二个则是负责程序在集群配置规则使其能够被自动发现和访问的kube-proxy。
\\此外,腾讯云还提供了一些自研组件。第一个组件是hpa-metrics-server,为了让用户能够使用Kubernetes提供的Pod横向扩展控制器而研发,其优点在于,除了基于CPU和内存扩展之外,还能扩展pod出入带宽的指标,方便用户适应更多扩缩容场景。第二个组件是则是cbs-provisioner,提供了pod使用腾讯云cbs块存储服务的能力;第三是ccs-log-collector,主要是负责收集容器里pod运行日志。
\\容器网络
\\当Kubernetes把控制组件搭建起来后,它要求网络提供三点,在pod不使用NAT的情况下,第一,集群内所有容器之间可以进行通讯;第二,所有的节点和容器之间可以进行通信;第三,为了应对服务发现的需求,降低网络复杂度,要求不能使用NAT,并实现Node和pod之间的扁平化网络。
\\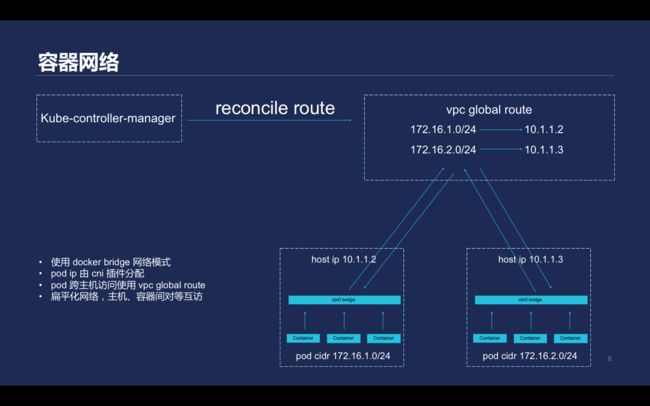
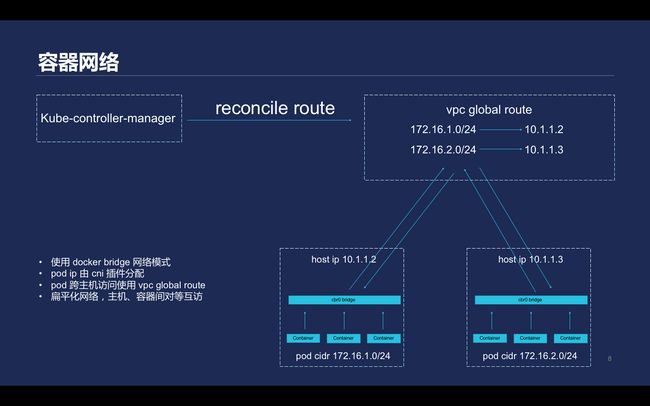
腾讯云Kubernetes使用的方案如上,这一方案方案直接使用了VPC提供的路由能力global route。使用 docker bridge 网络模式;pod ip 由 cni 插件分配;pod可以跨主机访问使用 vpc global route;采用了扁平化网络,主机、容器间实现对等互访。Kubernetes结点加入到一个集群中触发网络的过程如上图所示,这套过程中Docker采用了bridge的网络模式,pod IP直接由cni插件分配。
\\容器存储
\\这套Kubernetes集群中主要集成了腾讯云的块存储服务的CBS和CFS两个能力。
\\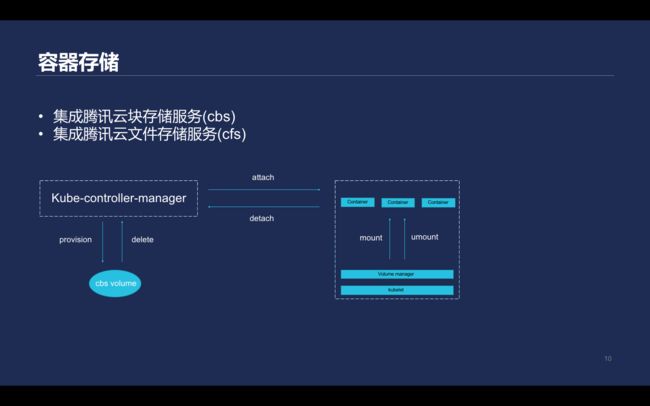
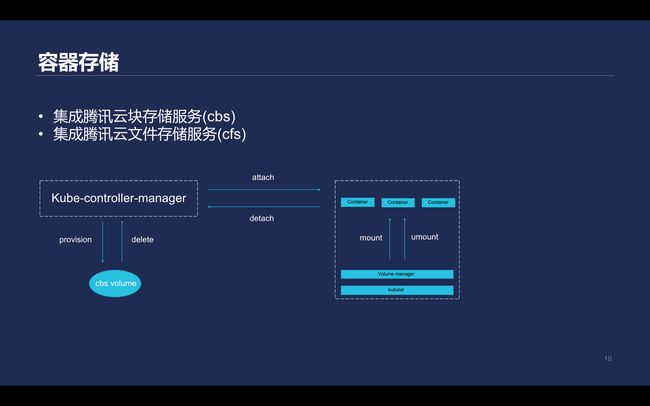
Kubernetes将volume挂载到pod里面时包含的过程如下:首先,Kube-controller-manager会为CBS提供volume进行准备。即会先创建一个云盘,然后将创云盘插到对应的主机上,主机上的Kubelet会做一个mount动作,将设备mount到一个Kubernetes指定的文件夹,Kubelet在创建这个pod时,会通过mount的形式把mount到的目录实际挂载到容器的namespace里。当pod销毁后, volume不再被需要,就会反向执行,先从主机上把对应的块设备先umount掉,再把detach掉,然后由Kube-controller-manager根据对应的plugin设置销毁或保留。
\\Kubernetes volume的插件机制主要包括了三种,第一种是早期使用的In tree volume plugin,需要将代码写在的代码仓库中,会影响正常存储功能的使用和集群稳定性;第二种是Flex Volume在扩展性和稳定性上有所增加,能够通过特定接口的二进制文件,实现mount和umount动作。这种方式的缺陷在于自动性不足且对环境有要求;第三种基于社区CSI接口实现的插件,也就是将Flex volume的二进制文件工作全部放到了容器里面,让Kubelet与对应功能的插件通信,最终实现mount和umount的动作。
\\容器日志与监控
\\在Kubernetes里面并没有提供默认的日志方案,资源消耗较大且步骤复杂。腾讯云容器服务的日志收集控制器主要基于Fluentd + kubernetes CRD(custom resource definition)实现,能够提供可视化配置。
\\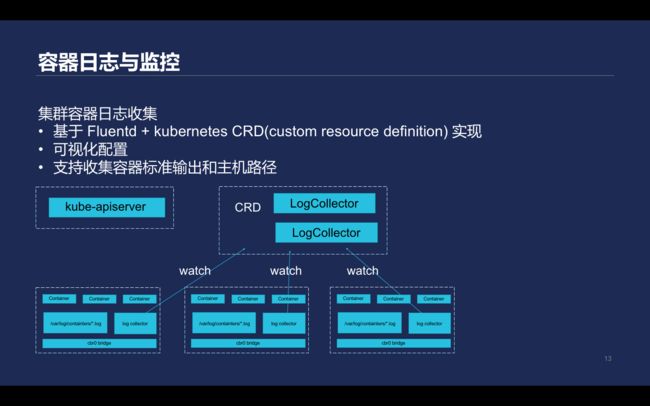
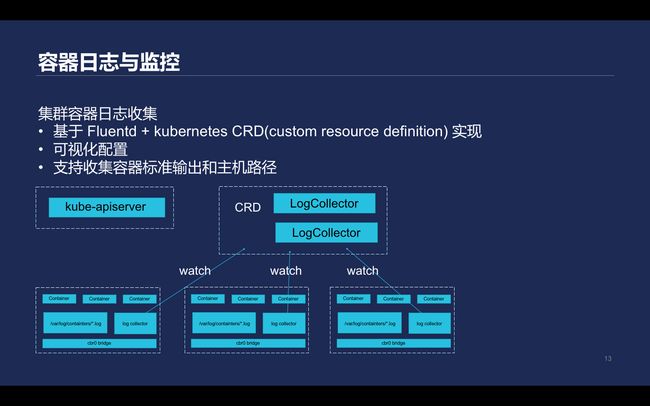
该控制器支持收集容器的标准输出,也支持收集pod所在的Node上主机文件路径的内容。另外可以通过LogCollector监听Kubernetes-apiserver资源,生成对应的Fluentd的配置文件,触Fluentd重载收集日志文件。直接配置Fluentd收集pod对应的路径规则,根据需求做日志路径,将不同的日志发往不同后端,这样就实现了日志收集。
\\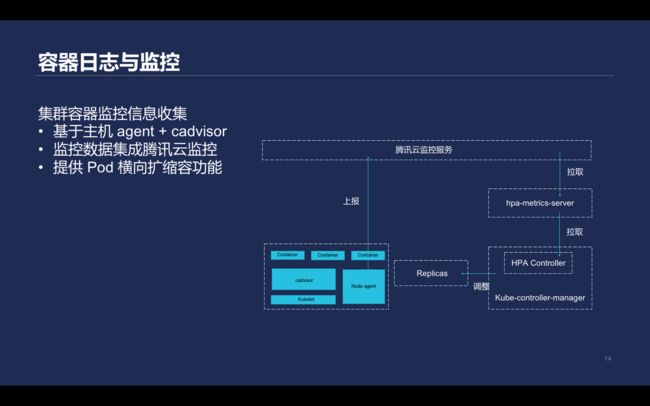
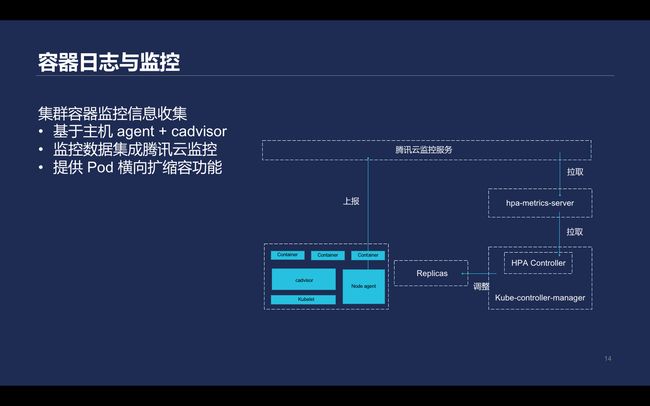
在监控方面,Kubernetes里的pod性能信息和云监控进行对接,在用户的Kubernetes节点上运行agent,在kubelet里内置的cadvisor收集pod运行性能信息,再去apiserver获取pod对应的元数据并进行打标签,然后上传到腾讯云监控服务。
\\另外基于腾讯云存储的监控指标实现hpa-metrics-server, 再利用Kubernetes提供的HPA能力会定期获取pod当前的入带宽、出带宽等指标熟练,并且根据定义进行扩容和缩容。
\\CVM上部署Kubernetes
\\在早期,为了实现产品快速上线,同时满足完全隔离的全托管Kubernetes服务,Master组件部署在一台CVM并放到用户VPC里,用户的Node节点直接在CVM的机器上,在此基础上做Kubelte等参数初始化工作、集群证书配置、默认拉取镜像凭证初始化等工作。
\\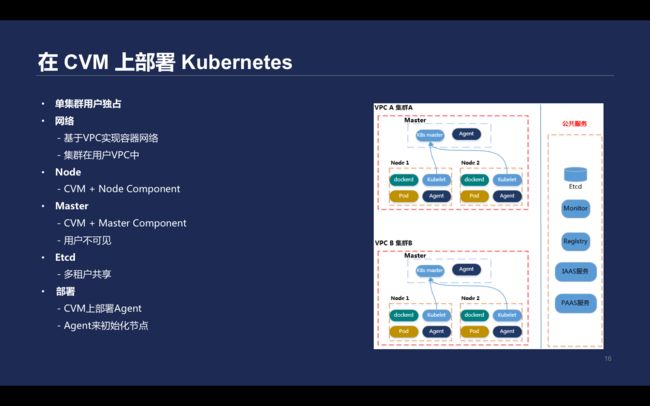
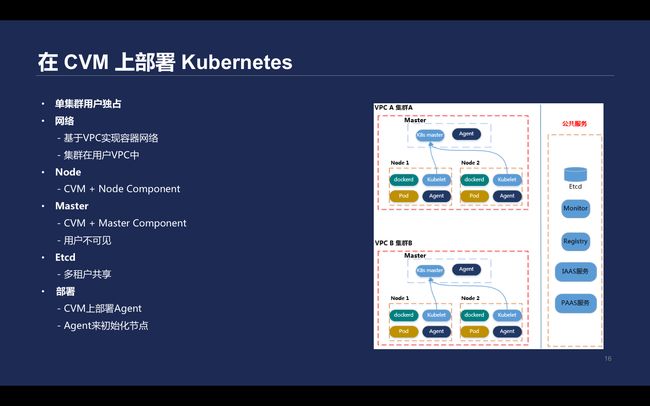
该方案节点均处于用户VPC中,通过Agent初始化部署整个集群,缺点就算管理困难。通过SSH直接登录到客户的Master节点进行运维操作,无法编程化,而且容器运维与Kubernetes关系离散。
\\Kubernetes in kubernetes
\\在此前,每个集群都在ETCD里面各自目录,相当于软隔离的措施。但ETCD并不是为海量数据存储服务的,因此在线上运行了数万个集群后, ETCD问题越发密集。因此最终决定了把Kubernetes部署在Kubernetes里面,通过Kubernetes API去管理Master组件,包括的apiserver、kube-controller-manager和自研组件。这样做就不需要通过SSH方式,到每台机器上进行操作,而是直接通过deployment提供的滚动升级能力来完成。
\\这样做的话可以充分利用Kubernetes的健康检查和就绪检查等机制实现故障自愈。基于hpa-metrics-server,可以实现apiserver的动态扩容,满足Kubernetes集群节点对于apiserver性能的需求。
\\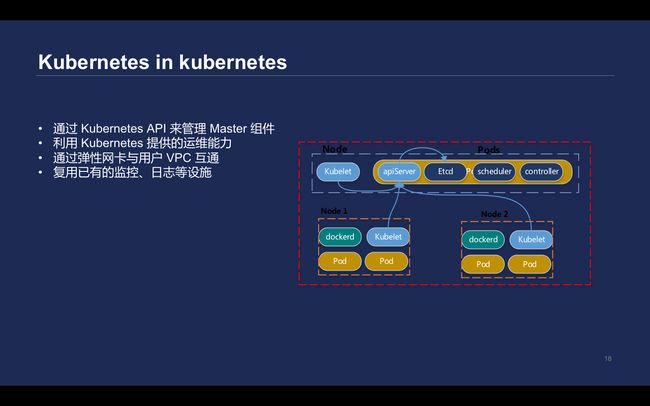
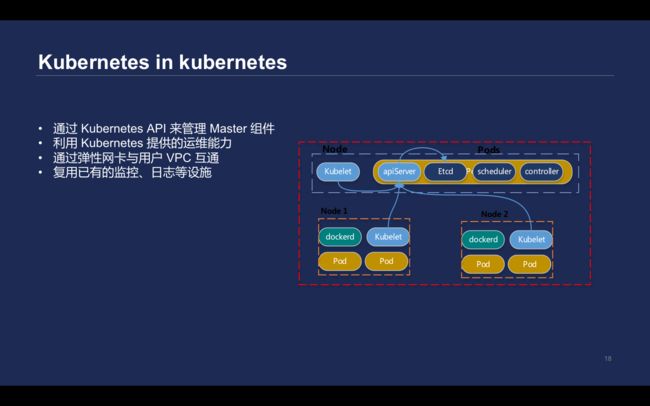
但是基于CVM的部署方案,所有的组件都部署在用户的VPC里面,如果我们把所有组件部署在Kubernetes Master里面,而且不能给每个用户部署一个Kubernetes集群。所以腾讯云提供了一个专门的Kubernetes集群,运行所有集群的Master。VPC提供的弹性网卡能力,直接绑定到运行apiserver的pod里,去实现和用户Node相关的互通。
\\通过在Kubernetes集群里面部署Kubernetes Master组件,成功降低了运维成本和Master组件的资源消耗。
\\CIS底层技术实现
\\Kubernetes上云部署实现了运维简化的基础,各种优质工具的开发则进一步丢下了开发者的包袱。对于开发者而言,Docker应该是非常常见的一种技术。通过Dockerfile或者Docker build 命令打包镜像,通过Docker pull、Docker push命令和容器仓库进行对接,最终实现跨平台的运行,Docker Wrong命令直接把Docker镜像运行了起来。
\\但Docker的问题在于管理复杂,需要Kubernetes简化编排。可是Kubernetes本身却比较复杂,一是安装复杂,组件颇多,需要master节点、Node节点等,还需要诸多软件,如apiserver、controller-manager、scheduler、Kubelet等;另外资源也复杂,入门需要一定时间。
\\腾讯云原来有TKE集群,能够帮助用户快速建立Kubernetes集群,master节点和node节点都是由腾讯工程师维护,给用户使用带来诸多便利。但是问题在于,当集群节点突发性不够用时,资源受节点限制,扩展需要手动添加节点,至少要几十秒延迟才能完成创建。
\\

其他方法还有,如用Kubernetes开源的CA与腾讯云弹性伸缩组进行对接,当节点不够用时,可以通过CA来扩容一个节点。或者采用HPA,可以进行pod横向伸缩容,但这样做虽然可以解决部分灵活问题,但依然不够。
\\在这些原因的驱使下,腾讯云CIS(Container Instance Service)服务就有了需求动力,其本质就是Serverless Kubemetes服务,将Kubernetes集群交给云厂商管理,而用户只需要关注Docker本身即可。
\\容器实例服务
\\容器实例服务(Container Instance Service,CIS)是一种使用容器为用户承载工作负载,不需要用户管理、维护服务器的全托管容器服务。它具有便捷、安全、便宜、灵活等四个特性。
\\便捷意味着用户无须购买底层资源,通过简单的配置,就可以用docker image生成容器实例,而容器结束实例即会结束,无须手工释放,也可以配置重启策略使实例长久存在。
\\安全是因为CIS由腾讯云自己进行集群维护,Kata containers提供了docker级别的生产速度和vm级别的资源隔离,在实例运行在用户的vpc网络中,支持配置安全组和ACL策略进行访问控制。
\\在成本方面,CIS根据购买的cpu、内存量,按实例实际运行的时间按秒计费;需要多少用多少,从启动开始,实例无论出于什么原因一旦结束即停止计费,价格合适。
\\而灵活性方面,容器实例支持购买超小资源,在一个pod里可以跑多个容器;一个实例可以是一个容器,亦可以包含多个相关容器;
\\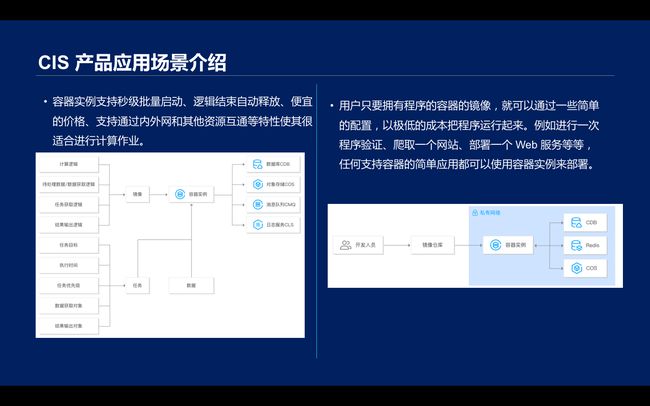
在应用场景方面,容器实例支持秒级批量启动、逻辑结束自动释放、便宜的价格、支持通过内外网和其他资源互通等特性使其很适合进行计算作业。
\\其次也可以有有镜像的快速验证产品,用户只要拥有程序的容器的镜像,就可以通过一些简单的配置,以极低的成本把程序运行起来。例如进行一次程序验证、爬取一个网站、部署一个 Web 服务等等,任何支持容器的简单应用都可以使用容器实例来部署。
\\CIS技术方案
\\CIS可以让用户只需要关注容器实例本身,将运维CIS所属的落地K8s集群的工作交给腾讯云。用户在启动一个CIS时,腾讯云会对应在K8s集群中提供CVM资源,在这个资源给出pod和对应的容器,用户就可访问该容器。CIS资源有VPC属性,用户可以直接通过网络访问所购买的CIS实例。当然,它还会和我们的Tencent Hub和image registry去进行对接。
\\

CIS底层由多地域多套Kubernetes集群组成,而每个CIS实例生成时会配置用户VPC的弹性网卡的功能。VPC弹性网卡本质上是,弹性网卡可以达到VPC网络的相连,弹性网卡是挂在容器里面。当有了VPC属性之后,它就可以访问VPC内的其他CIS、CVM、CDB和COS等网上的其他资源打通。
\\一般来讲,容器中的日志真实文件会随着k8s pod的消失而消失。但要支持秒级计费能力,就需要通过日志判断实例,因此日志是不允许消失。所以腾讯云采用的是时序型数据库,通过开源软件Filebeat来收集CIS日志,转到ES数据库中。在每个实例节点上部署DaemonSet后,日志转到CIS集群中,用户查询日志时,就会通过ES集群中的相关API进行查询。
\\CIS 与 Serverless Kubernetes 集群
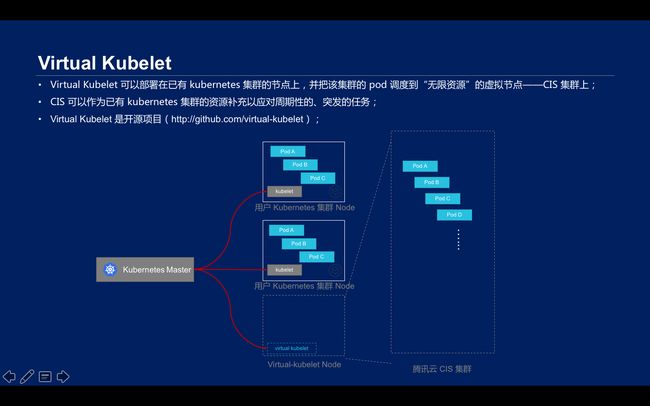
\\开源项目Virtual Kubelet是一个可以部署在已有Kubernetes集群节点上,并把该集群的pod调度到“无限资源”的虚拟节点CIS集群上。pod节点可以部署在virtual Kubelet上,其可以通过CIS集群落地,pod上的弹性网卡属于Kubernetes的VPC网络,这样做就可以直接在CIS上运行大批量、周期性的、突发的任务,作为已有 kubernetes 集群的资源补充。
\\
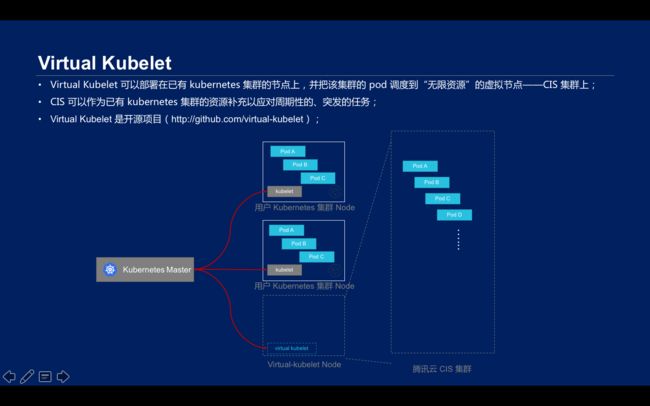
Virtual Kubelet可以与腾讯云容器服务( Cloud Container Service,CCS)共同构建Severless服务。CCS 支持用户使用CVM、VPC、LB、CBS等基础产品搭建具备完全操作权限的 Kubernetes 集群,通过在 CCS 集群 node 上部署 virtual kubelet 可以把 CIS 实例作为集群 pod 调度。
\\具体操作时,需要在 CCS 上任一节点上部署 virtual-kubelet pod,该操作会为该 CCS 集群添加一个虚拟节点“virtual-kubelet node”;然后新建 Deployment\\Job\\CronJob 时通过将目标节点指向 virtual-kubelet node,则这些服务的 pod 不会占用 CCS 集群的 CVM 资源;
\\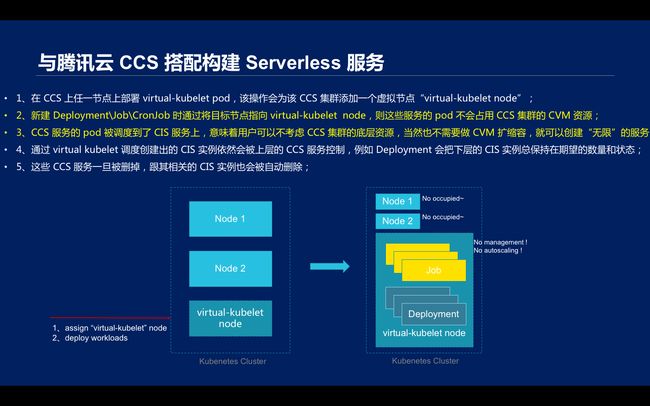
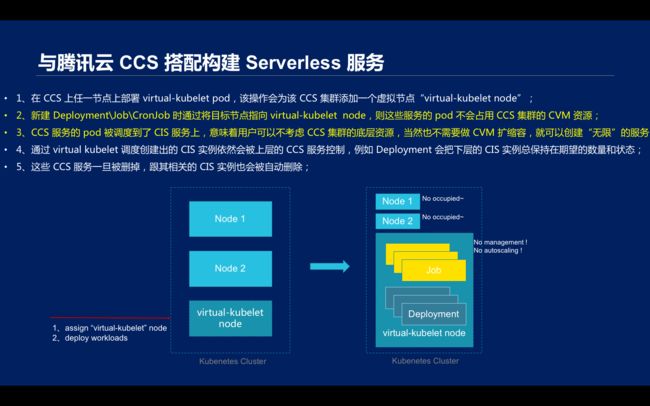 CCS 服务的 pod 被调度到了 CIS 服务上,意味着用户可以不考虑 CCS 集群的底层资源,当然也不需要做 CVM 扩缩容,就可以创建“无限”的服务;通过 virtual kubelet 调度创建出的 CIS 实例依然会被上层的 CCS 服务控制,例如 Deployment 会把下层的 CIS 实例总保持在期望的数量和状态;这些 CCS 服务一旦被删掉,跟其相关的 CIS 实例也会被自动删除;
CCS 服务的 pod 被调度到了 CIS 服务上,意味着用户可以不考虑 CCS 集群的底层资源,当然也不需要做 CVM 扩缩容,就可以创建“无限”的服务;通过 virtual kubelet 调度创建出的 CIS 实例依然会被上层的 CCS 服务控制,例如 Deployment 会把下层的 CIS 实例总保持在期望的数量和状态;这些 CCS 服务一旦被删掉,跟其相关的 CIS 实例也会被自动删除;
容器实例与Clear Containers
\\总结来看,Docker是一个轻量级的虚拟化项目,同时Docker是K8s pod的runtime;目前用户面临的问题是。将用户容器运行在单独的虚拟机上可以保障租户间的隔离安全,但是用户只需要一个容器,虚拟机的其他是多余的;而Clear Containers和Docker的区别在于,前者不共用内核,基于KVM隔离更安全;
\\Clear Container与原来的物理机启动厚重的虚拟机相比,虚拟机上再启动docker提供服务,现在直接在物理机上启动轻量的clear container,直接给用户提供服务,虚拟化层级变小,更节约资源,也更提高性能。
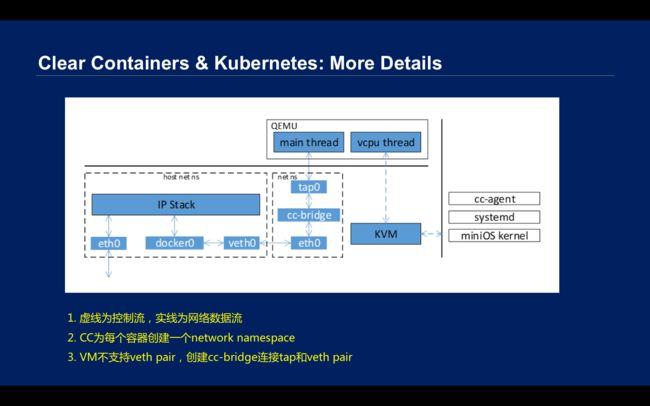
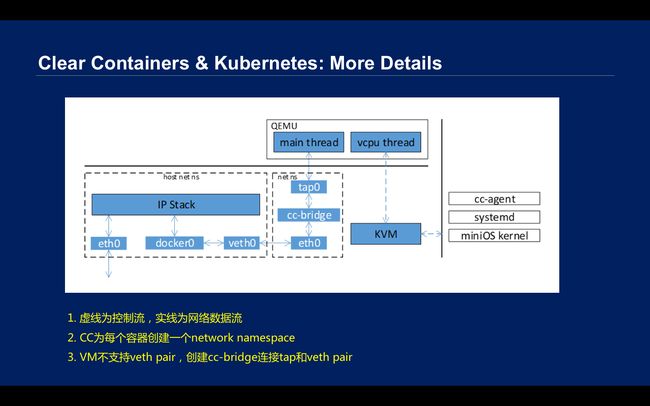
\\在网络方面,Docker的网络有一个VETH设备,如果你访问外面,会有一个Docker0网桥,如果你访问外网,会有Snat。但是是基于KVM的虚拟机,很多厂家都是用QEMU把虚拟机启动,虚拟机里面有一个虚拟网络设备,host上更多是一个tap设备,也就是说虚拟机不支持VETH设备。如果要复用Docker生态,所以又有一个VETH设备,这里就有一个cc-bridge网桥,网络就通过到host的tap0—cc-bridge—eth0—veth0—Docker0,再进协议栈,这样出去。
\\
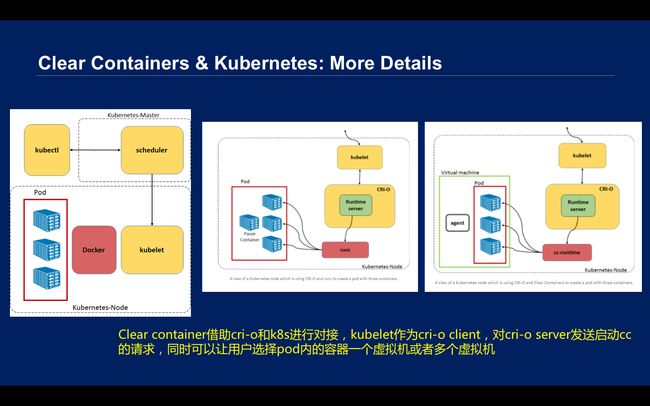
Clear container比Kubernetes更注重技术细节,其技术实现包含cc-runtime、cc-shim、cc-proxy、cc-agent、miniOS(kernel和rootfs);并且只实现runtime,把原来runc拆分成cc-runtime和cc-agent,再加上VM带来的额外通信机制。
\\
Clear Containers原来是每个容器都会起一个虚拟机, pod有多个容器的概念,难道每个pod里面每个容器都要起一个虚拟机,一个pod有若干个虚拟机吗?
\\事实上并不需要如此。Clear Containers可以借助CRI-O和K8s进行对接。在过去,如果要创建pod,直接是Kubelet和Docker进行访问,然后把这个容器创出来。加了CRI-O这个组件之后,Kubelet作为cri-o client,对cri-o server控制一个run client,基于Docker的pod就起来了。当然,如果是Clound Containers或者Clear Containers,就要调用cc-runtime,需要根据应用编排安全的需要选择
\\Tencent Hub技术架构与DevOps实践
\\DevOps的概念从2009年至今已经过去了近十年的时间。DevOps应当以业务敏捷为中心,构造适应快速发布软件的工具和文化。那么Tencent Hub是什么?Tencent Hub核心是两部分,第一部分,是一个多功能的存储仓库,包含了Docker镜像存储功能以及helmcharts等存储;第二部分,Tencent Hub是一个DevOps引擎,通过workflow工作流的编排,去帮助大家建立自己的DevOps流程。
\\Tencent Hub技术架构
\\Tencent Hub的总体架构, Tencent Hub在镜像仓库的存储是基于COS存储,因为COS可靠性非常高,能达到11个9的可靠性;Tencent Hub有一个自研workflow引擎,使用YAML定义DevOps流程,让DevOps本身达到Program的方式;基于容器的插件机制(Component),最大限度复用已有DevOps任务;Tencent Hub使用容器去实现插件机制,来封装用户自定义的DevOps任务。使用Kubernetes作为job执行引擎,具有良好的可扩展性;在Docker存储方面,加入了Docker镜像漏洞扫描等。
\\在Tencent Hub,最核心的存储还是Docker镜像。Tencent Hub除了公共的镜像存储之外,还支持私有的镜像存储。在私有镜像存储里面,需要通过登录才能获取或者上传自己的Docker镜像。
\\首先,客户端发起push/pull操作,client连接Registry检查权限;Registry返回401,并且返回了获取Token的服务地址;client请求授权服务获取Token(OAuth2或Basic Authentication);client返回一个Token表示客户端的访问授权列表;client携带Token重新请求Registry获取资源;Registry校验Token以及其中的权限列表通过后, 与client\u2028建立pull/push会话,开始上传/下载数据。
\\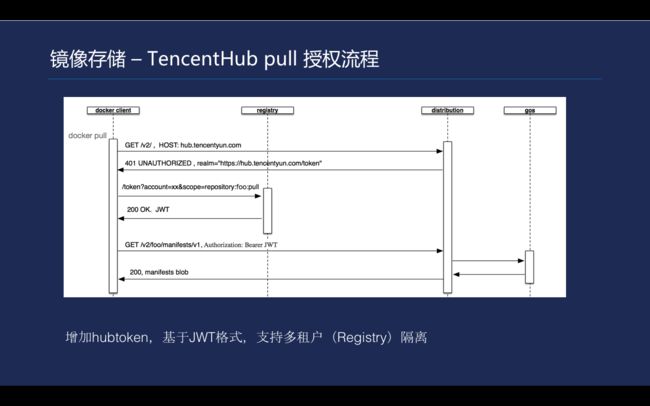
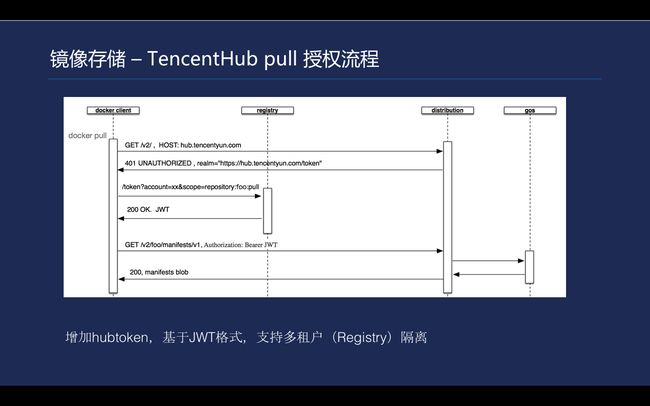
Tencent Hub pull 的授权流程大体如下, Docker服务端首先会去访问webhook,客户端会根据当前是否有Token来返回一个授权的地址,即hub.tencentyun.com/token这个地址。然后客户端就会自动访问/Token的URL,带上当前的状况以及申请的权限范围,最后生成阶段再返回。最后,当前面都申请完成之后,就会进入Docker镜像拉取流程。
\\Docker镜像是分层组织形式,每个Docker镜像包含多个Layer和一个Config文件,每个Layer构建一个Docker镜像文件系统里面出现的差异,Config文件包含当前Docker镜像能运行的一些环境要求。这些文件被一个Manifest文件引用起来,形成可以一直拉取Manifest,通过它可以找到所有的Docker镜像内容。
\\这样的设计好处主要有三点。首先,由于所有数据可以被校验,安全性高;第二,相同内容的layer只需存储一份,所以冗余少;第三,整个Docker镜像里无论哪个Layer有改变,都会最终影响到Manifest的改变,所以Docker镜像并不是重新修改一个Layer,而是重新生成,因此做缓存的时候就可以在不同环境下部署缓存。
\\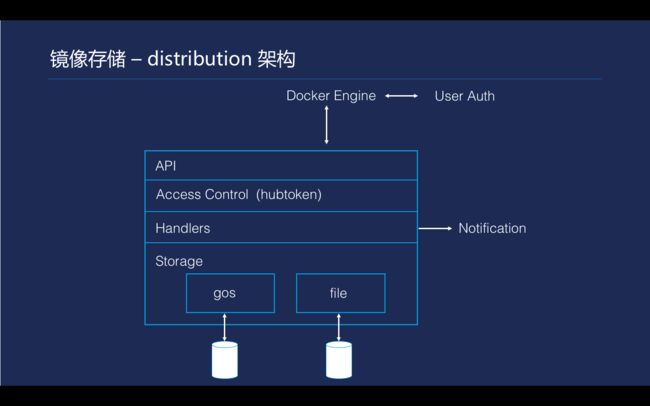
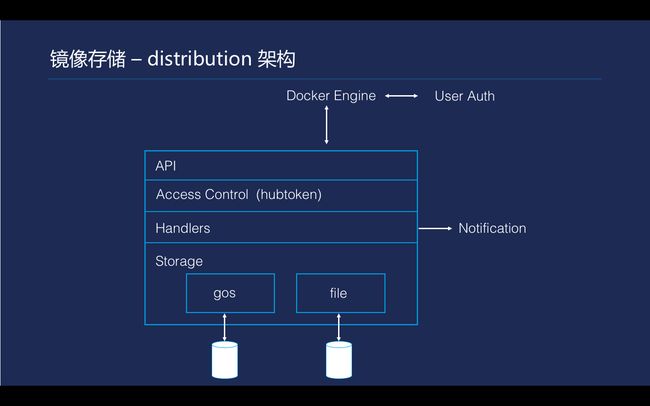
Tencent Hub镜像的存储核心是利用了Docker官方实现的distribution。distribution的实现在这个图里面描述得比较清楚,代码层次结构也几乎相同。最上面有API root层分发,第二层会有一个权限控制的一层。在权限控制下面有实现API协议的函数处理,提供主要的业务逻辑实现。最终是distribution的实现,提供了一套存储的插件机制,有一个标准的存储接口,规定了文件上传、文件移动。
\\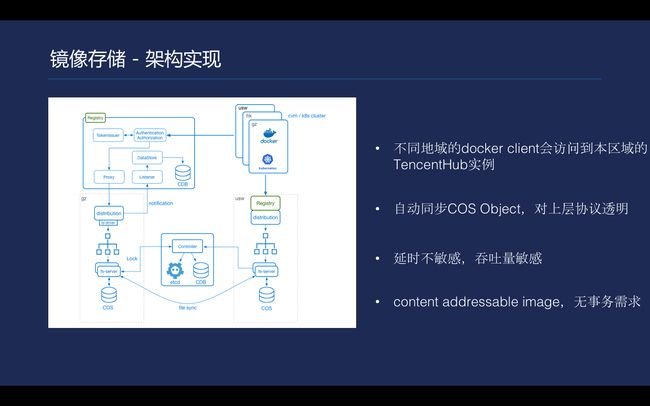
目前腾讯云容器服务的仓库是CCR,而并不是Tencent Hub。CCR有两个问题,第一是不同地域的镜像是不通的,直接依赖了COS提供的分发能力,COS是无法跨区域的,所以会存在问题。第二是拉取多个镜像时,对延时不敏感,但是对吞吐量很敏感。
\\在Docker镜像的存储完成之后,还是提供了一个Docker镜像的静态扫描。通过对比包管理(apt, yum)记录的软件版本与本地漏洞数据库中的软件版本得出漏洞列表。Scanner 周期性地与漏洞数据库进行同步获取最新的漏洞信息;镜像上传完成后发送到扫描中心进行异步漏洞扫描;而当新漏洞被发现时,Registry也会受到通知,同时可以通过webhook将信息投递给开发者
\\workflow引擎设计与实现
\\为什么要去做Tencent Hub的DevOps引擎呢?因为很多客户在上云的时候遇到了操作重复性的问题。而且DevOps的自动化要求还很高,再照顾到一些客户的需求,因此要做一个DevOps的工具,去帮用户来建立自己的DevOps流程。
\\这就需要考虑很多事情,第一,把DevOps任务编排起来,需要做到一个能尽量覆盖到尽多客户DevOps需求的编排逻辑,比如Workflow;第二,DevOps任务是差别较大,需要把这些任务交给客户自己去完成,需要设计一个插件机制Component;第三,用户的DevOps流程运行在Tencent Hub里面,需要做很简单的任务调度,最终还是选择Kubernetes来省去很多运维工作,监控都可以去复用。
\\按业界通用的方法把workflow设计成三级结构,每个workflow包含多个stage来完成,每个stage里面会有很多job。job这里会有并行和串行的执行方式。stage有一个类型叫past+prst。在DevOps流程当中,在合适的时候是需要人工介入的,设计可以暂停的stage就能适应这样的场景。
\\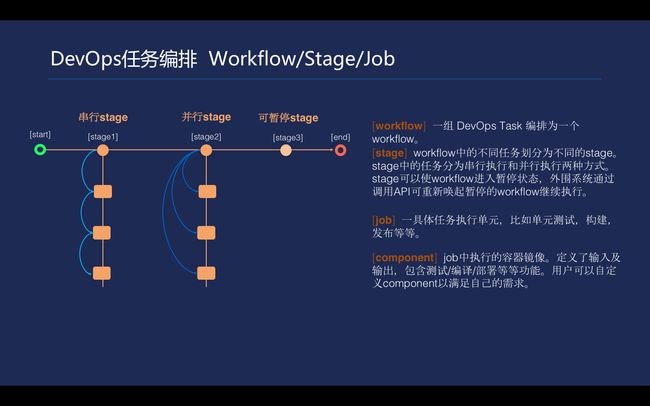
workflow的设计生命周期对流程推动十分重要。workflow可以被触发执行,有三种方式。一,把某一条workflow和代码关联起来,当提交代码的时候,可以触发这条workflow的执行;二,可以和Tencent Hub的镜像存储关联起来,不需要代码去触发,可以通过push一个镜像去触发;三,通过调API直接触发某一条workflow。
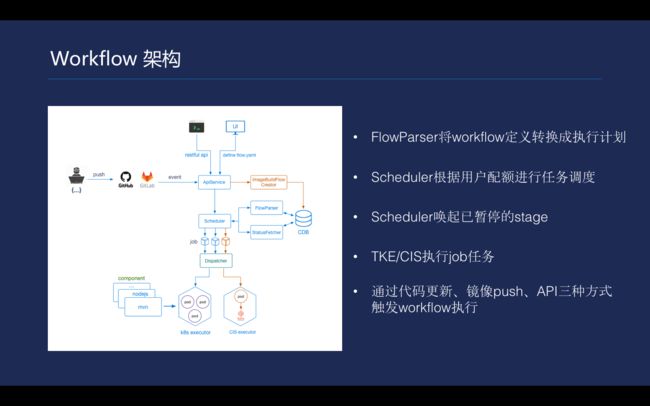
\\被触发后,就可以系统把它置成一个pending状态。Workflow被触发执行,一个新建的workflow实例被\u2028置于pending状态,经过配额检查,scheduler调用k8s API执行第一个job,\u2028workflow实例进入scheduling状态;StatusFetcher检测job在k8s中的状态,如果不是pending,\u2028workflow实例进入running状态;
\\Scheduler遇到可暂停的stage(type=break),待stage中\u2028任务执行成功后,workflow实例中的job被暂停调度,workflow\u2028进入paused状态,等待外部API调用唤醒workflow的执行;end是一组状态的描述,实际上包括timeout、failure、success、\u2028canceled四种状态。处于paused状态的workflow可以被终止。
\\workflow上job在设计时需要考虑四点。第一,job可以都考虑成一个函数去处理输入,在内部做一些业务逻辑,通过定义的标准输出处理完的信息;第二,job可以从workflow全局环境变量中去读取,传进来做一些逻辑。第三,每个component都需要和外界接触,因此workflow里会去提供cache和artifact指令。第四,workflow没有办法去循环执行,只是一个DAG构成的关系去一条一条向前执行。
\\关于artifact和cache的实现和作用是不同的,设计Cache是用来在不同的job之间共享和传递数据;Artifacts则可以保存在提供的仓库里面。Cache的具体实现如保存文件夹,它会把指定的文件目录进行压缩,上传到Tencent Hub的图形存储里面。当下面有一个Job依赖它的时候,会在Component内部下载下来。
\\为什么要选择用容器来做DevOps呢?第一,面对的所有用户是公共服务,隔离性是第一要务。用容器可以非常方便的帮我们实现不同用户的任务隔离,有些用户可能对自己任务的安全性要求非常好,后期还会考虑和CIS做结合,直接用Clear Container来提供更高的隔离性。第二是复用,在不同的部门之外,它们的技术段可能会有相似的,后台有一些公共的DevOps任务需要去使用,通过容器Docker镜像可以共享这样的逻辑;第三则是标准,组件的开发维护可用本地Docker进行测试;第四是平滑,从而能让已有的DevOps任务可通过容器快速进行封装。
\\Component函数一样会有涉及到Input和Output。Input方面,输入值以环境变量的方式传入到Component中,包括workflow全局变量和上游Job的输出变量;而output方面,输出值写入到stdout,workflow通过分析日志进行提取;输出值格式为: [JOB_OUT] key=value ,可以通过输出多行Log来输出多个值;Component进程执行成功后以状态码0退出。
\\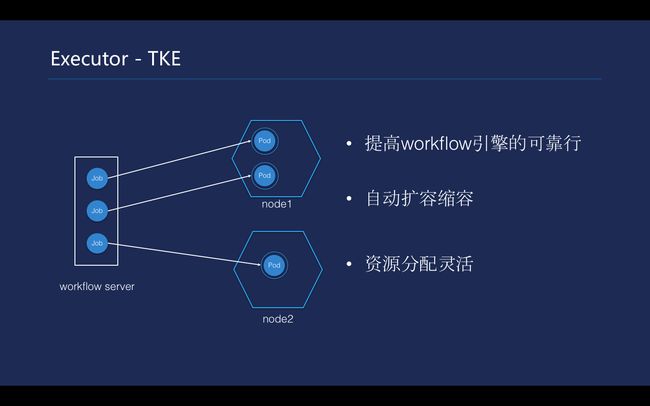
Workflow是采用了TKE去执行的,选择用DevOps做workflow引擎的执行集群是基于以下三大特性考虑的。首先,Kubernetes的可靠性使得TKE非常可靠,从而不必去担心运维难题;第二,workflow跑的很多任务可能会占用不同的资源,而TKE可以做到自动扩缩容,能为客户提供构建的能力,不需要人工介入;第三的资源分配更灵活,客户的workflow资源占用大小不同,这对Kubernetes来讲解决并不难。
\\关于job的两个hook,在实现的时候需要注意到这些事情。Flow引擎通过分析Component的config,保存Component定义的Entrypoint和Command;实现CommandWrapper程序,Job运行指定该程序为Pod的Command;CommandWrapper启动后处理PreStart动作,如下载依赖的Cache;CommandWrapper fork子进程运行Component定义的Entrypoint和command;子进程退出后,CommandWrapper处理PostStop动作,如上传Artifact、Cache等;最后,CommandWrapper以子进程的返回码作为返回码退出。
\\每一个构建的workflow的job需要去关心它的Log。Job是一次性任务,利用k8s api读取日志,比独立的日志收集通道更简单;dispatcher读取日志之后,使用multi writer将日志交给StatusFetcher保存,同时可以通过websocket将日志推送给web页面。
\\
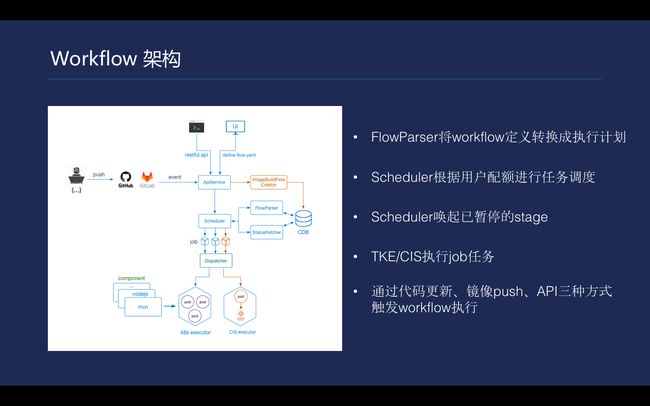
到此,workflow引擎实现和设计就基本完成。通过Tencent Hub,经过思考,如何搭建自己的DevOps流程是千差万别的,以上方法站在公有服务的提供商角度,考虑给用户最大的便利而建立的一套工具。
\\云上构建容器化的大规模计算平台
\\看了这么多的技术解析后,那么究竟腾讯云的容器技术在其用户的手中是怎样的状态呢?晶泰科技是腾讯云在药物工业领域的合作伙伴,他们在云端部署大规模科学计算平台与腾讯云有着紧密的合作。
\\晶泰科技是一家以计算驱动的创新药物研发科技公司,在药物工业中,一款药的上市需要经过复杂的研发工序以及10年以上的漫长研发周期,而且越是重磅的药物,经历的周期就越长;因此腾讯云的合作伙伴晶泰科技致力于通过分子模拟平台、药物动力学等技术,借助云端大规模HPC、AI驱动、量子算法等预测技术,提升药物工业中临床前期的研发效率,为患者带来更优质的药物。
\\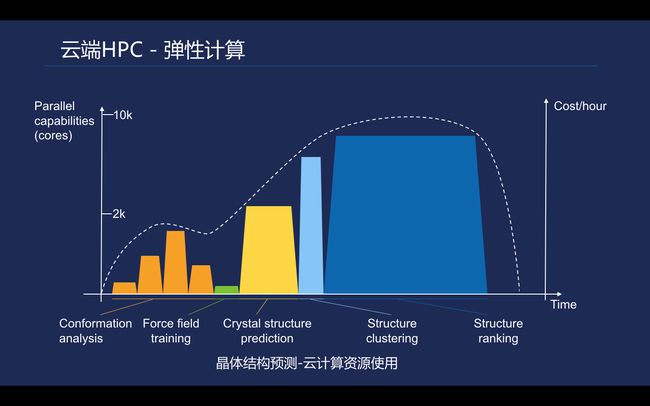
科学计算平台通常是跑在像天河这样的超算上, 但超算上大规模资源的申请需要排队, 对任务的调度管理, 数据存储都不太灵活, 而且在计算性价比上优势也不明显,综上我们提出, 能否把传统的科学计算搬到云端?目前一些批量计算、高性能计算已经迁移到云端。在把两部分技术结合之后,借助云端去构建一个大规模的HPC集群,可能会达到百万核实量级,可能会用到上万级的机器集群。
\\晶泰科技的小分子药物晶型预测流程中,需要用到构像分析、力场训练、晶体结构预测、结构聚类及排位算法等,每个流程都需要大量计算支持,而且越靠后计算需求越高这就需要借助云计算,甚至需要多个云融合在一起以便构建一个比较大规模的计算资源池,在里面执行大批量科学计算任务。
\\计算平台演变
\\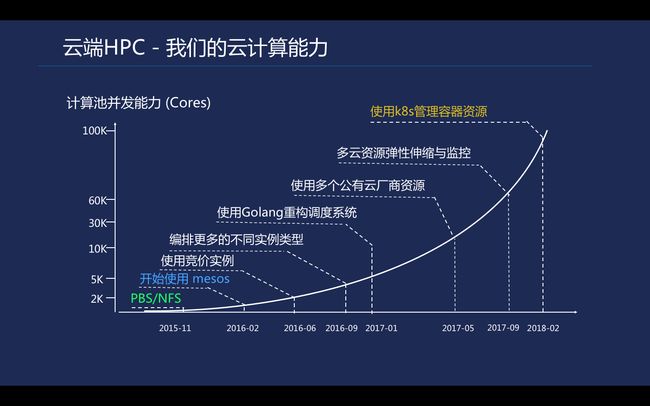
计算平台在这几年发生了较大的变化。从2015年晶泰成立的时候推出了第一代计算平台,基于PBS调度系统以及NFS文件共享存储,架构上类似于超算的PBS/LSF+SAN。系统都是使用开源组件搭建,命令行方式对任务进行提交及管理, 基本满足了前期使用需求。但是随着业务的发展,计算量需求越来越大,而第一代平台的计算资源利用率不足、PBS动态管理能力有限, 以及NFS的IOPS压力等问题开始出现。
\\从第二代平台的迭代更新开始,我们使用Mesos对资源进行管理,自研Mesos的Framework, 使用Docker打包科学计算的软件以及算法, 从此开始了云上科学计算的容器化之路。通过添加不同的计算资源, 计算池得到了进一步扩大。当我们单个资源池突破1000台机器时, 我们使用Golang重构了调度系统,以便支持更高性能的任务分发。接着我们通过接入多个公有云厂商,实现多公云资源弹性伸缩与监控。18年开始, 随着k8s的高速发展, 调度平台也正式开始使用K8s去管理云上的超算集群。
\\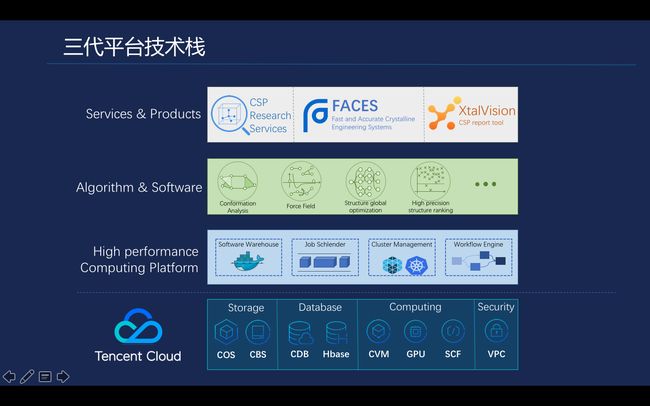
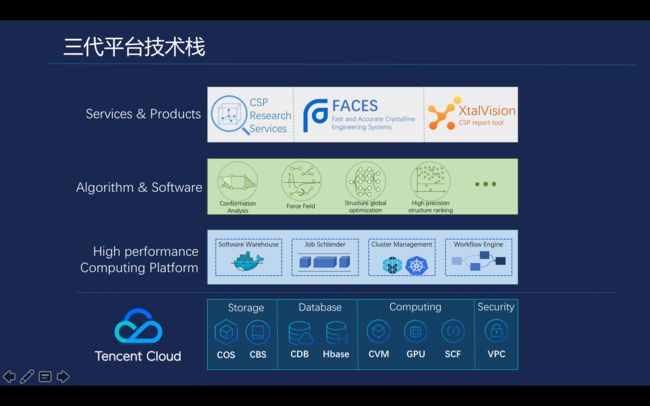
第三代平台技术产品上主要是CSP, Faces晶型预测系统服务,以及最终产出计算报告的全自动工具XtalVision。第二层主要是是预测流程中使用到的各种核心算法,融合了现有的科学计算算法进行二次开发、封装,打包成一个Docker镜像,业务人员只需要去使用这个Docker镜像,就可以在平台上提交对应的预测计算任务, 如一些能量计算以及一些通用力场的计算。然后是我们支撑大规模科学计算的高性能计算平台,最下面就是公有云的基础资源。
\\腾讯云容器服务实践
\\
需要注意的是,超算和信息服务的计算有较大的差异。科学计算的特点是计算密集型,计算时间长,通常是异步计算,追求算法的执行效率并行化,主要以工作站或超算为主;信息服务的特点则是IO 密集型,低延时高可用,利用架构提高系统容量及服务质量,大量使用云计算。
\\在开始之前我们简单介绍一下在云上构建科学计算的镜像, 科学计算使用的镜像跟服务化的镜像会有一些不太一样的地方, 一般科学计算的镜像大小会达到GB级别,因此需要对镜像进行剪裁和分层优化,以便加速镜像拉取速度。
\\下面的参数会涉及到镜像拉取的性能以及并发率。如:kubelet --serialize-image-pulls=false是串行镜像拉取,通常情况下是false,如果设置为true,需要更高版本的Docker支持, 同时docker storage需要使用overlay作为镜像存储。kubelet --image-pull-progress-deadline=10mins是镜像拉取超时, Docker本身也会有并发拉取的参数在里面(如:dockerd --max-concurrent-download=5),以便在任务分发时减少镜像拉取时间。对于kubelet来说, 目前最新版的K8s已经支持动态修改Kubulet参数。
\\腾讯云的TKE容器服务,基本实现了一键就可以构建出一个带有Master的K8s集群。同时腾讯云打通了TKE和腾讯云其他云服务交互通道, 更易于系统的快速集成。TKE会提供一个容器服务API出来,但是它主要还是针对一些信息服务编排, 对于高性能计算批量提交任务还不是特别适用, 因此我们使用了k8s原生API进行平台构建。
\\现在K8s已经发布到1.11版本,支持不超过五千个节点,在集群里面不超过1.5万个pod,以及不超过30万个容器,单个节点不超过100个pod。K8s官方也提供了一些构建大集群的辅助文档在里面,但实际上在构建的时候还是会有形形色色的问题。
\\K8s主节点集成已经由腾讯云构建出来,接下来需要要向集群中添加计算节点,TKE提供了弹性伸缩组对集群资源进行动态扩缩容。但出于节约成本的考虑,伸缩组需要是高度弹性, 可以快速扩容大批量资源, 同时也能在任务计算完成时快速回收资源。比如晶泰就会有如下业务场景:
\\平台一次性提交10万个任务,每个任务需要8核的cpu去计算, 同时由于案例时间上的要求, 要求几天之内要把这些任务算完,所以此时需要让资源池从0扩容到1000/2000个节点一起跑。任务的计算复杂度很多时候都是有相似性的,因此计算的周期也比较相似,某个时间点就会有大批任务同时跑完, 大批量资源被释放出来, 这个时候又需要快速回收资源。经过与腾讯TKE团队一起排查, 目前基本在快速扩缩容这块满足了计算的需求.
\\到目前为此利用TKE构建了K8s集群并通过其快速弹性扩缩容组件实现资源的管控, 接下来我们看看计算平台上所支持的HPC任务.
\\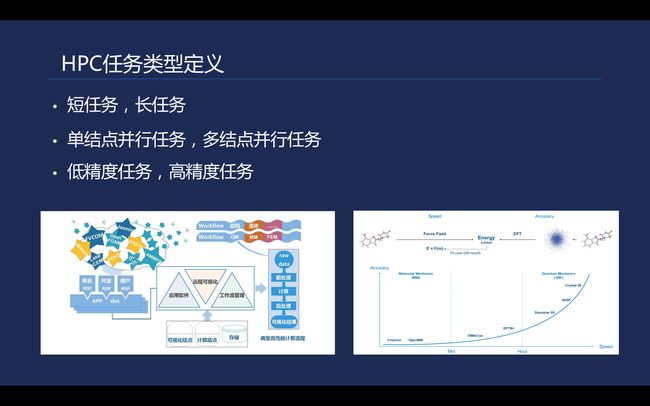
简单地从时间维度来看,可以分为短时间任务和长时间任务。从精度来看可以分为低精度和高精度任务。在药物分子预测中的能力/排位等流程中都会对精度要求有,从右边图来说,不同的科学计算算法在不同的流程中都会有一个精度及时间的差别,通常精度越高需要的计算周期越长。
\\在支持的HPC多节点并行任务中,一些公有云的普通网络是没有办法满足像MPI这种多节点并行任务的。通常MPI任务多节点需要有一个高性能的网络, 如IB网络,需要一些专有的网卡去支持远程的直接内存访问(RDMA)。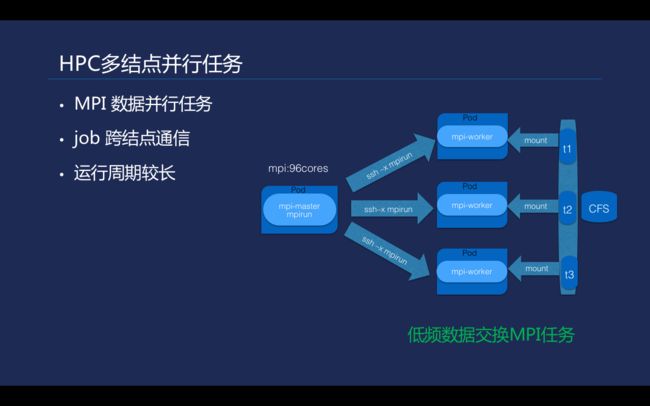
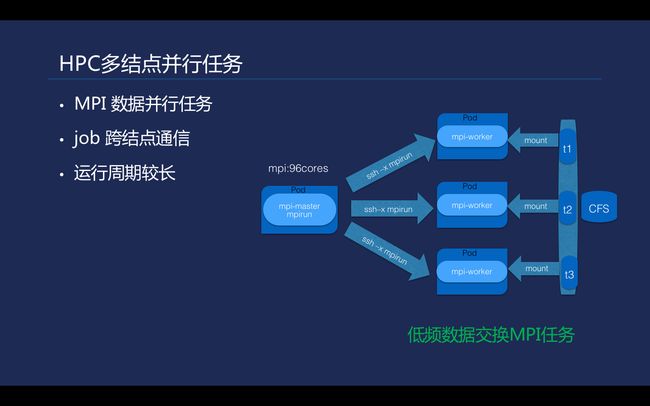
MPI任务的运行周期会相对长一些,右图是在晶泰基于K8s实现的MPI任务。刚才提及现有的TKE提供的网络没有达到通用的MPI的网络要求,但是一些数据并行化的MPI任务还是可以在一般性能的容器网络上面进行运算。它们特点是节点之间的数据交互通常是比较少的,这样网络数据传输也比较少,能避免高性能网络的带宽限制。其实k8s对构建高性能容器网络也提供了插件支持, 通过k8s Device Plugins可实现NVIDIA/AMD GPU及RDMA/Solarflare等外部组件接入。
\\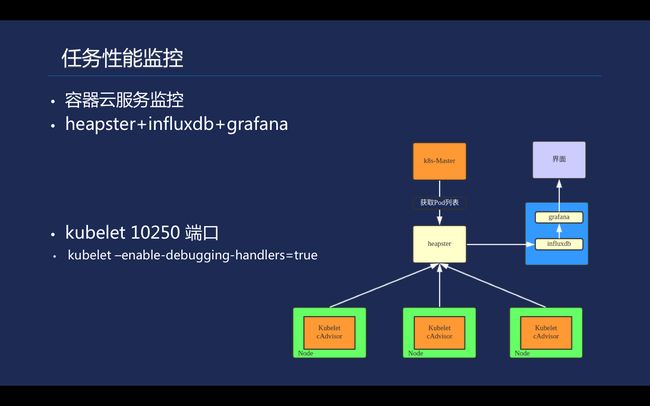
容器云TKE提供了健全的服务监控,能够实时监控pod CPU以及内存。同时也提供了定制化的接入的方案,通过heapster+influxdb+grafana架构可以收集计算任务的cpu/memory信息,对于高性能计算关注的核心算法效率问题来说, 这些监控数据对我们平台算法的不断改进提供了很好的指导方向 。
\\值得一提的是, kubelet 10250端口的参数,在安全组方面不能大意,如果没有把计算节点10250端口封掉,容易导致入侵,因为在开启了enable-debugging-handlers=true 的情况下,外部可以直接通过这个端口,到pod里面进行集群调试。
\\综合来看,Kubernetes的出现降低了容器服务的入门门槛和复杂性,解放了企业的技术精力,使之能够完全投入到行业所处的技术领域之中。而如CIS、Tencent Hub等技术工具的发展,容器服务的部署、监控、运维和管理都在变得更加高效,无论是医药交通,还是科算超算,都已开始享受技术发展的红利。可以看到的是,2018年的Kubernetes技术,就如繁星之上的皓月,望眼可见,普照各地。