Action Recognition:iDT论文解读(Improved Dense Trajectories)
主要参考博文 行为识别笔记:improved dense trajectories算法(iDT算法)
一.DT介绍
先简单介绍DT(Dense Trajectories)方法:利用光流场来获得视频序列中的轨迹,在沿着轨迹提取轨迹形状特征和HOF,HOG,MBH特征,然后利用BoF(Bag of Features)方法对特征进行编码,最后基于编码结果训练SVM分类器。
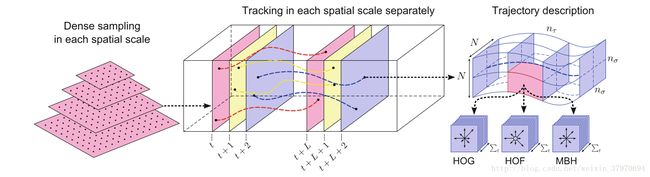
1.1 Dense Sampling 密集采样
在多个空间尺度上通过网格划分的方式密集采样特征点,多个空间尺度上的采样能够保证采样的特征点覆盖了所有空间位置和尺度。我们的目的是能够通过视频在时间序列上跟踪这些特征点。空间尺度的设置比例为 1/2–√ 1 / 2 。在跟踪前需要先去除一些特征点,文中采用的方法是计算每个像素点自相关矩阵的特征值,并设置阈值去除低于阈值的特征点。阈值T定义如下:
T=0.001×maxiϵImin(λ1i,λ2i) T = 0.001 × m a x i ϵ I m i n ( λ i 1 , λ i 2 )
其中
(λ1i,λ2i) ( λ i 1 , λ i 2 ) 是图像
I I 中的像素点
i i 的特征值。
1.2 Trajectory Shape Descriptor 轨迹形状描述子
特征点的跟踪是在每个空间尺度上独立进行的。对于每一帧 It I t ,我们根据下一帧 It+1 I t + 1 计算它的密集光流场 ωt=(μt,υt) ω t = ( μ t , υ t ) ,其中 μt μ t 和 υt υ t 代表光流的水平和垂直分量。设第 It I t 帧的一个特征点为 Pt=(xt,yt) P t = ( x t , y t ) ,则在下一帧 It+1 I t + 1 帧图像中该特征点的位置表示如下:
Pt+1=(xt+1,yt+1)=(xt,yt)+(M∗ωt)∣(xt,yt) P t + 1 = ( x t + 1 , y t + 1 ) = ( x t , y t ) + ( M ∗ ω t ) ∣ ( x t , y t )
其中
M M 代表中值滤波器,尺寸大小为
3×3 3 × 3 ,所以该式子是通过计算特征点邻域内的光流中值来得到特征点的运动方向的。
某个特征点在连续 L L 帧图像上的位置构成了一段轨迹 (Pt,Pt+1,...,Pt+L) ( P t , P t + 1 , . . . , P t + L ) ,后面的特征提取沿着各个轨迹进行,但是轨迹跟踪在跟踪过程中存在漂移现象,因此长时间的跟踪是不可靠的,所以每 L L 帧就要重新进行密集特征点采样,重新进行跟踪。论文中选 L=15 L = 15 。
轨迹的形状由于编码了局部运动信息,因此本身也可作为一种特征描述子。给定一段 L L 帧长的轨迹,我们通过序列 ΔPt=(Pt+1−Pt)=(xt+1−xt,yt+1−yt) Δ P t = ( P t + 1 − P t ) = ( x t + 1 − x t , y t + 1 − y t ) 来描述轨迹形状。
1.3 Motion and Structure Descriptors运动和结构描述子
除了轨迹形状特征,论文中使用 HOF H O F , HOG H O G 和 MBH M B H 来描述表观(Appearence)和运动(Motion)信息。我们在一个时间-空间体(space-timevolume)上进行特征描述子的计算,该结构体为 N×N N × N 大小, L L 帧长。将该结构体进行 nσ×nσ×nτ n σ × n σ × n τ 大小的网格划分,空间上每个方向均分 nσ n σ 份,时间方向上均分 nτ n τ 份。在每个 cell c e l l 内计算 HOG H O G , HOF H O F , MBH M B H 描述子,将这些描述子进行 concat c o n c a t 构成最终的描述子。论文中参数设定: N=32,nσ=2,nτ=3 N = 32 , n σ = 2 , n τ = 3 。下面对每个特征描述子进行简单介绍:参考博文 链接1 链接2
HOG特征:计算的是灰度图像梯度直方图,直方图的 bin b i n 数目为8。所以 HOG H O G 特征长度为2*2*3*8=96。
HOF特征:计算的是光流的直方图,直方图的 bin b i n 数目取8+1,前8个 bin b i n 与 HOG H O G 都相同,额外的一个用于统计光流幅度小于某个阈值的像素。故 HOF H O F 特征的长度为2*2*3*9=108。
MBH特征:计算的是光溜图像梯度的直方图,可以理解为在光流图像上计算的 HOG H O G 特征。由于光流图像包含 X X 方向和 Y Y 方向,因此需要分别计算 MBHX M B H X 和 MBHY M B H Y 。 MBH M B H 总的特征长度为2*96=192。
最后对提取到的特征进行归一化, DT D T 算法中,对以上三种特征均使用 L2 L 2 范数进行归一化。
1.4 Bag of Features 特征编码
对于每一段轨迹,都有一组特征描述子(trajectory,HOG,HOF,MBH),我们需要对所有的特征描述子进行编码,得到最终一定长度大小的编码特征来进行最后的视频分类。
Bag of Feature算法大概分为四步:
(1) 提取图像特征
(2)对特征进行聚类( k-means k - m e a n s ),得到一部字典
(3)根据字典将图片表示成向量(直方图)
(4)训练分类器
在训练过程中, DT D T 算法将所有训练特征聚类到100000类,每个类别下有4000个词袋( visualwords v i s u a l w o r d s )。训练完成后,对每个视频的特征进行编码,就可以得到视频对应的特征。在得到视频对应的编码特征后, DT D T 算法采用 SVM(RBF-χ2核) S V M ( R B F - χ 2 核 ) 分类器进行分类,采用 one-against-rest o n e - a g a i n s t - r e s t 策略训练多分类器。
论文中还有一些细节的设置:如对于静态轨迹以及有较大位移的轨迹,通过一些后处理将它们移除;对于轨迹形状描述子的归一化处理操作;对于运动和结构描述子,同样要进行归一化操作处理,均采用 L2 L 2 范数进行归一化。
二. iDT介绍
主要思想:(1)提升的密集轨迹算法主要考虑到相机运动,在帧与帧之间使用 SURF S U R F 关键点描述子和密集光流进行特征点匹配,从而消除或者减轻相机运动带来的影响。在求得匹配点对之后,就可以利用RANSAC算法估计投影变换矩阵。(2)人在视频帧中占主导地位,由于人的运动和相机运动不同,人身上的匹配点对使得投影矩阵的估计不准确,因此iDT算法采用human detector 检测人的位置框,进一步消除内部的匹配点对,从而使得人的运动不影响投影矩阵的估计。
2.1 Trajectory features
HOG:灰度图像直方图捕捉了图像的静态表观信息。 HOF和 MBH捕捉了图像的运动信息,均是基于光流的,能够更加准确地描述动作。
不同于DT算法,iDT采用 L1 L 1 正则化对获取到特征进行归一化操作。
2.2 Feature encoding
不同于 DT D T 算法采用的 BoF(BagofFeatures) B o F ( B a g o f F e a t u r e s ) 编码方式,iDT算法采用FV(Fisher vector)编码,各参数设置如下:
(1) 用于训练的特征长度: Trajectory+HOG+HOF+MBH=30+108+96+192=426 T r a j e c t o r y + H O G + H O F + M B H = 30 + 108 + 96 + 192 = 426 维
(2)用于训练的特征个数:从训练集中随机采样256000个特征
(3) PCA P C A 降维比例:2,即维度除以2,降维后特征长度为 213 213
(4) GMM G M M 高斯聚类的个数 K=256 K = 256
编码后得到的特征维度为 2DK 2 D K ,即 109056维 109056 维 ,在编码后 iDT i D T 同样使用了 SVM S V M 进行分类。