【大数据】——HDFS运行原理及使用
一、简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
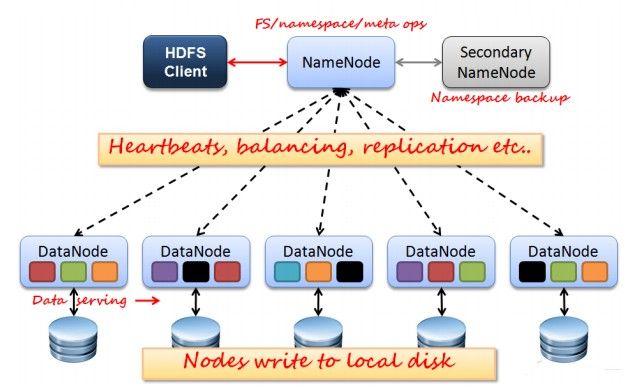
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
二、工作原理
写操作:
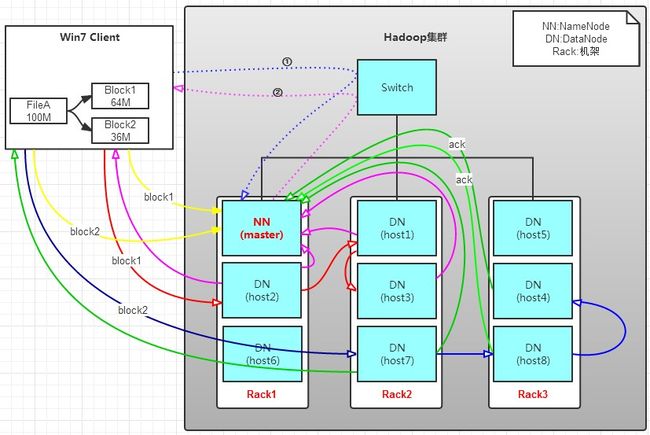
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
读操作:
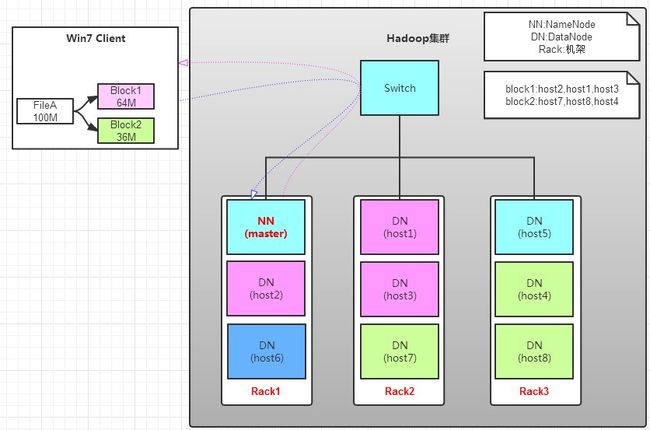
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优选读取本机架上的数据。
三.HDFS读数据分析
1.概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
2.读数据步骤详解
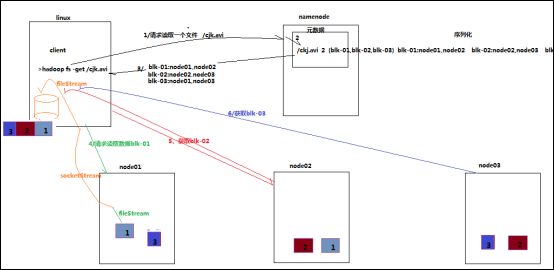
(图片来源于网络,仅供参考)
1)客户端向namenode发起RPC调用,请求读取文件数据。
2)namenode检查文件是否存在,如果存在则获取文件的元信息(blockid以及对应的datanode列表)。
3)客户端收到元信息后选取一个网络距离最近的datanode,依次请求读取每个数据块。客户端首先要校检文件是否损坏,如果损坏,客户端会选取另外的datanode请求。
4)datanode与客户端简历socket连接,传输对应的数据块,客户端收到数据缓存到本地,之后写入文件。
5)依次传输剩下的数据块,直到整个文件合并完成。
从某个Datanode获取的数据块有可能是损坏的,损坏可能是由Datanode的存储设备错误、网络错误或者软件bug造成的。HDFS客户端软件实现了对HDFS文件内容的校验和(checksum)检查。当客户端创建一个新的HDFS文件,会计算这个文件每个数据块的校验和,并将校验和作为一个单独的隐藏文件保存在同一个HDFS名字空间下。当客户端获取文件内容后,它会检验从Datanode获取的数据跟相应的校验和文件中的校验和是否匹配,如果不匹配,客户端可以选择从其他Datanode获取该数据块的副本。
四.HDFS删除数据分析
HDFS删除数据比较流程相对简单,只列出详细步骤:
1)客户端向namenode发起RPC调用,请求删除文件。namenode检查合法性。
2)namenode查询文件相关元信息,向存储文件数据块的datanode发出删除请求。
3)datanode删除相关数据块。返回结果。
4)namenode返回结果给客户端。
当用户或应用程序删除某个文件时,这个文件并没有立刻从HDFS中删除。实际上,HDFS会将这个文件重命名转移到/trash目录。只要文件还在/trash目录中,该文件就可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间时,Namenode就会将该文件从名字空间中删除。删除文件会使得该文件相关的数据块被释放。注意,从用户删除文件到HDFS空闲空间的增加之间会有一定时间的延迟。只要被删除的文件还在/trash目录中,用户就可以恢复这个文件。如果用户想恢复被删除的文件,他/她可以浏览/trash目录找回该文件。/trash目录仅仅保存被删除文件的最后副本。/trash目录与其他的目录没有什么区别,除了一点:在该目录上HDFS会应用一个特殊策略来自动删除文件。目前的默认策略是删除/trash中保留时间超过6小时的文件。将来,这个策略可以通过一个被良好定义的接口配置。
当一个文件的副本系数被减小后,Namenode会选择过剩的副本删除。下次心跳检测时会将该信息传递给Datanode。Datanode遂即移除相应的数据块,集群中的空闲空间加大。同样,在调用setReplication API结束和集群中空闲空间增加间会有一定的延迟。
五.NameNode元数据管理原理分析
1.概述
首先明确namenode的职责:响应客户端请求、管理元数据。
namenode对元数据有三种存储方式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
细节:HDFS不适合存储小文件的原因,每个文件都会产生元信息,当小文件多了之后元信息也就多了,对namenode会造成压力。
2.对三种存储机制的进一步解释
内存元数据就是当前namenode正在使用的元数据,是存储在内存中的。
磁盘元数据镜像文件是内存元数据的镜像,保存在namenode工作目录中,它是一个准元数据,作用是在namenode宕机时能够快速较准确的恢复元数据。称为fsimage。
数据操作日志文件是用来记录元数据操作的,在每次改动元数据时都会追加日志记录,如果有完整的日志就可以还原完整的元数据。主要作用是用来完善fsimage,减少fsimage和内存元数据的差距。称为editslog。
3.checkpoint机制分析
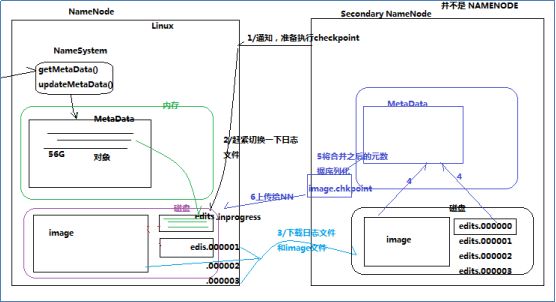
因为namenode本身的任务就非常重要,为了不再给namenode压力,日志合并到fsimage就引入了另一个角色secondarynamenode。secondarynamenode负责定期把editslog合并到fsimage,“定期”是namenode向secondarynamenode发送RPC请求的,是按时间或者日志记录条数为“间隔”的,这样即不会浪费合并操作又不会造成fsimage和内存元数据有很大的差距。因为元数据的改变频率是不固定的。
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)。
(图片来源于网络,仅供参考)
1)namenode向secondarynamenode发送RPC请求,请求合并editslog到fsimage。
2)secondarynamenode收到请求后从namenode上读取(通过http服务)editslog(多个,滚动日志文件)和fsimage文件。
3)secondarynamenode会根据拿到的editslog合并到fsimage。形成最新的fsimage文件。(中间有很多步骤,把文件加载到内存,还原成元数据结构,合并,再生成文件,新生成的文件名为fsimage.checkpoint)。
4)secondarynamenode通过http服务把fsimage.checkpoint文件上传到namenode,并且通过RPC调用把文件改名为fsimage。
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据。
关于checkpoint操作的配置:
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
editslog和fsimage文件存储在$dfs.namenode.name.dir/current目录下,这个目录可以在hdfs-site.xml中配置的。这个目录下的文件结构如下:
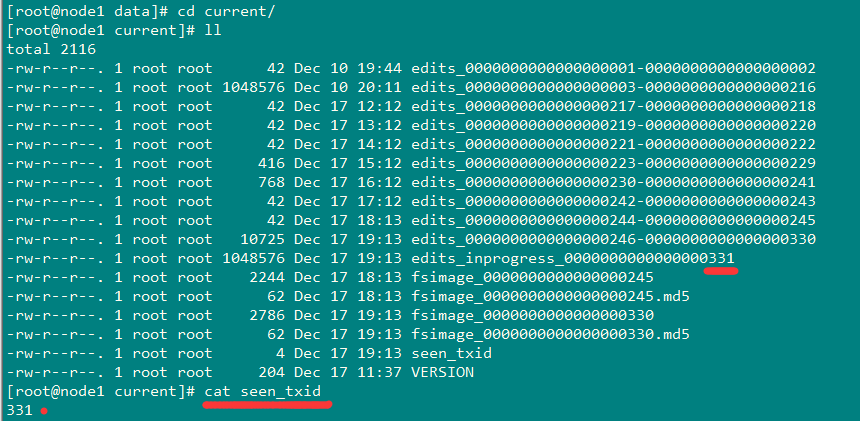
包括edits日志文件(滚动的多个文件),有一个是edits_inprogress_*是当前正在写的日志。fsimage文件以及md5校检文件。seen_txid是记录当前滚动序号,代表seen_txid之前的日志都已经合并完成。
$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字恢复。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生重启namenode时metaData的资料有缺少,导致误删Datanode上多余Block的信息。
六、HDFS中常用到的命令
1、hadoop fs
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。2、hadoop fsadmin
hadoop dfsadmin -report
hadoop dfsadmin -safemode enter | leave | get | wait
hadoop dfsadmin -setBalancerBandwidth 10003、hadoop fsck
4、start-balancer.sh
七、java接口
最简单的从Hadoop URL读取数据 (这里在Eclipse上连接HDFS编译运行)
package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws MalformedURLException, IOException {
InputStream in = null;
String input = "hdfs://192.168.92.138:9000/user/test.txt";
try {
in = new URL(input).openStream();
IOUtils.copyBytes(in, System.out, 4096,false);
}finally {
IOUtils.closeStream(in);
}
}
}
这里调用Hadoop的IOUtils类,在输入流和输出流之间复制数据(in和System.out)最后两个参数用于第一个设置复制的缓冲区大小,第二个设置结束后是否关闭数据流。
还可以通过FileSystem API读取数据
代码如下:
package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws IOException {
String uri = "hdfs://192.168.92.136:9000/user/test.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 1024,false);
}finally {
IOUtils.closeStream(in);
}
}
}这里调用open()函数来获取文件的输入流,FileSystem的get()方法获取FileSystem实例。
使用FileSystem API写入数据
代码如下:
package filesystem;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = "E:\\share\\input\\2007_12_1.txt";
String dst = "hdfs://192.168.92.136:9000/user/logs/2008_10_2.txt";
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst),conf);
OutputStream out = fs.create(new Path(dst),new Progressable() {
public void progress() {
System.out.print("*");
}
});
IOUtils.copyBytes(in, out, 1024,true);
}
}FileSystem的create()方法用于新建文件,返回FSDataOutputStream对象。 Progressable()用于传递回掉窗口,可以用来把数据写入datanode的进度通知给应用。
使用FileSystem API删除数据
代码如下:
package filesystem;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDelete {
public static void main(String[] args) throws Exception{
String uri = "hdfs://192.168.92.136:9000/user/1400.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
fs.delete(new Path(uri));
}
}使用delete()方法来永久性删除文件或目录。
FileSystem的其它一些方法:
- public boolean mkdirs(Path f) throws IOException 用来创建目录,创建成功返回true。
- public FileStatus getFileStates(Path f) throws FIleNotFoundException 用来获取文件或目录的FileStatus对象。
- public FileStatus[ ] listStatus(Path f)throws IOException 列出目录中的内容
- public FileStatus[ ] globStatu(Path pathPattern) throws IOException 返回与其路径匹配于指定模式的所有文件的FileStatus对象数组,并按路径排序
参考文章:
1、https://www.cnblogs.com/laov/p/3434917.html
2、https://www.cnblogs.com/caiyisen/p/7395843.html
3、www.cnblogs.com/wxisme/p/6270860.html