ArcFace 论文大颗粒粗读笔记(四)
最后一节,附录
平行加速
我们可以将ArcFace应用于大型身份吗?是的,数百万个身份不是问题。中心(W)的概念在ArcFace中是必不可少的,但是中心(W)的参数大小与类的数量成正比。当训练数据中有数百万个身份时,建议的ArcFace面临巨大的训练困难,例如即使在过高的水平上,GPU内存消耗过多,计算成本也很高。
在我们的实现3中,我们采用了并行加速策略[44]来缓解此问题。我们优化了训练代码,以通过在特征x(称为通用数据并行策略)和中心W(我们将其称为中心并行策略)上并行加速,轻松而有效地在一台机器上支持百万个级别身份。

如图10所示,我们在特征x和中心W上的并行加速可以显着减少GPU内存消耗并加快训练速度。即使对于使用8 * 1080ti(11GB)训练的一百万个身份,我们的实现(ResNet 50,批处理大小8 * 64,特征尺寸512和浮点32)仍然可以每秒800个样本的速度运行。与[47]中提出的近似加速方法相比,我们的实现没有性能下降。
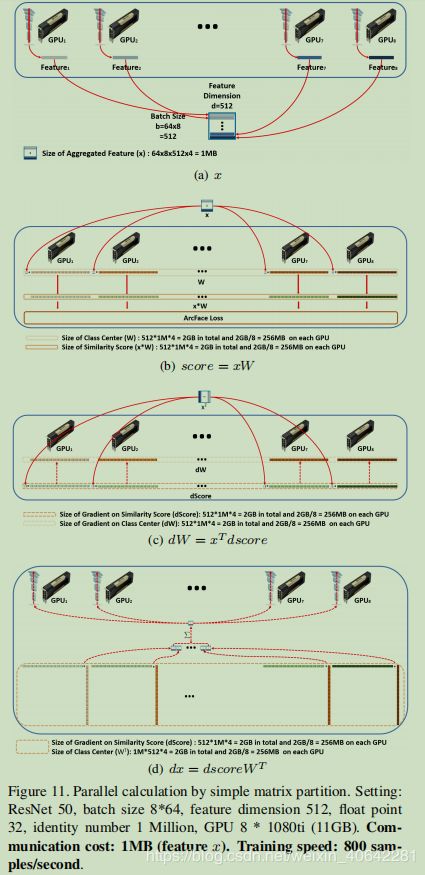
在图11中,我们通过简单的矩阵划分说明了并行加速度的主要计算步骤,初学者可以很容易地掌握和复制它们[3]。
(1)获取特征(x)。面部嵌入特征从8个GPU卡聚集到一个特征矩阵(批大小8 * 64×特征尺寸512)中。汇总后的特征矩阵的大小仅为1MB,传输特征矩阵时的通信成本可以忽略不计。
(2)获得相似性得分矩阵(得分= xW)。我们将特征矩阵复制到每个GPU中,并同时将特征矩阵乘以中心子矩阵(特征尺寸512×标识号1M / 8),以获得相似度得分子矩阵(批处理大小512×标识号1M / 8) )在每个GPU上。相似度得分矩阵继续计算ArcFace损耗和梯度。在这里,我们沿着身份维度对中心矩阵和相似性得分矩阵进行简单的矩阵划分,并且在中心和相似性得分矩阵上没有通信成本。每个GPU上的中心子矩阵和相似性分数子矩阵都只有256MB。
(3)获得中心的梯度(dW)。我们将特征矩阵转置到每个GPU上,并同时将转置后的特征矩阵乘以相似度分数的梯度子矩阵。
(4)获取特征(x)的梯度。我们同时将相似度分数的梯度子矩阵乘以转置的中心子矩阵,并对8个GPU卡的输出求和,以得到特征x的梯度。
考虑到通信成本(MB级),我们的集群可以轻松,高效地对数百万个身份进行ArcFace实施培训。
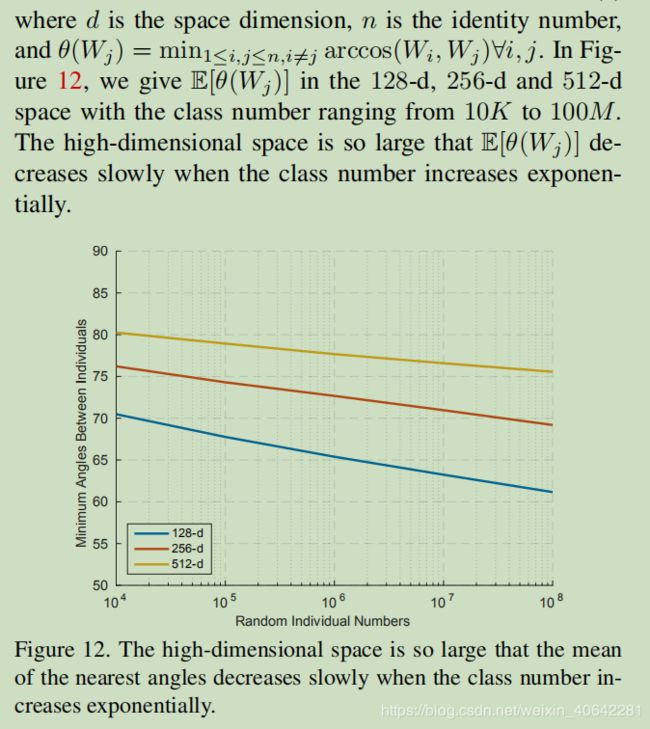
特征空间分析
512维超球面空间是否足以容纳
大规模的身份? 从理论上讲,是的。
我们假设身份中心Wj遵循现实的球形均匀分布,对最近邻居的期望为[5]为