Java 值传递 & 引用传递 引发的思考
前言
最近(其实已经好几天前了)看到一个“Java到底是值传递还是引用传递?”的问题。感觉挺有思考价值,在一顿基础知识狂补之后,终于是盘明白了。特此总结。
前面讲 Java基础 - Java变量总结 的时候,没有涉及到一种分类,基本类型和引用类型;这里顺便也补充一下。
那么直接进入问题:Java到底是值传递还是引用传递?
前戏稍微有点长…急性子的可以直接跳到 值传递引用传递 部分。
有些坑你不注意,永远不知道何时会掉下去 : )
值传递 & 引用传递
上一篇文章说到,搞清楚概念很重要!
那么,这次我们探究的值传递和引用传递的概念是什么呢?
随处可见的定义,如下:
值传递(pass by value)是指在调用方法时将实参复制一份传递到方法中,这样当方法对形参进行修改时不会影响到实参 1。
//举个C语言的例子
void add(int x,int b){
return a+b;
}
引用传递(pass by reference)是指在调用方法时将实参的地址直接传递到方法中,那么在方法中对形参所进行的修改,将影响到实参 1。
//这里同样举个C的例子
void change(char* str){
*str = "Change Success.";
}
实参&形参
关于形参、实参的概念,这里先简单介绍一下:
函数的参数即为形参,例如add( )方法中的a,b;change( )方法中的str;
而我们调用时传入的参数即为实参。
有机会我会把它放在递归里面讲(毕竟真正理解递归需要先理解函数调用流程)
那么Java中的变量传递呢?嘿,这得…
从变量类型说起
话说计算机,从电子管代表实现01逻辑开始,逐渐演化为…
不好意思,扯远了。我们分而治之。
基本类型&引用类型
在Java中,数据类型被分为基本类型和引用类型。
基本类型:编程语言中内置的最小粒度的数据类型;Java基本类型包括四大类八种类型:
- 整数类型
- byte
- short
- int
- long
- 浮点数类型
- float
- double
- 字符类型
- char
- 布尔类型
- boolean
引用类型:引用也叫句柄,是编程语言中定义的在句柄中存放着实际内容所在地址的地址值的一种数据形式。它主要包括 2:
- 类
- 接口
- 数组
- 字符串
ps:注意不要把这种分类和 Java基础 - Java变量总结 的划分混为一谈,划分标准不同!
划分完了,要不存储了解下?
Java内存结构
我们知道Java与C不同,Java给我们屏蔽了指针的概念,其语言本身是不能操作内存的。那么Java是怎么操作内存的呢?在回答这个问题之前,我们先看一下,Java程序的内存结构。Java程序启动后,会初始化这些内存的数据 3。

这里插播一下:关于内存结构和内存模型的纠纷…这里就不展开了。
可自行点击本文参考 (。・∀・)ノ 4
简单来说,内存模型解决的是以下问题 5:
Java 虚拟机规范定义了Java 内存模型来屏蔽掉各种硬件和操作系统的内存差异,达到跨平台的内存访问效果。- 为了获得更好的执行性能,
Java 内存模型没有限制执行引擎使用处理器的特定缓存器或缓存来和主内存(可以和 RAM 类比,但是是虚拟机内存的一部分) 交互,工作内存(可类比高速缓存,也是虚拟机内存的一部分)为线程私有。 工作内存和主内存的划分和Java 堆,栈,方法区的划分不同,两者基本没有关系,如果勉强对应,则主内存可理解为堆中实例数据部分,工作内存则对应栈中部分区域。
此外,我们还可以查阅官方文档以论证其差别 17.4. Memory Model
所以我们经常讲的内存模型,准确而言应称为内存结构。 ( ̄_ ̄|||)
内存划分 2
根据上图Java内存结构,我们再次分而治之。
-
程序计数器及其他隐含寄存器
线程私有。记录着当前线程所执行的字节码的行号指示器,在程序运行过程中,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。 -
堆
堆是用来存储对象本身和数组的,在JVM中只有一个堆,因此,堆是被所有 线程共享的。 -
Java栈
准确来说,应该叫虚拟机栈,栈中存放着栈帧。栈是
线程私有的,也就是线程之间的栈是隔离的;每个方法被执行的时候都会创建一个栈帧用于存储局部变量表,操作数栈,方法出口地址等信息。每一个方法被调用的过程就对应一个栈帧在虚拟机栈中从入栈到出栈的过程 6。下图表示了一个
Java栈的模型以及栈帧的组成:
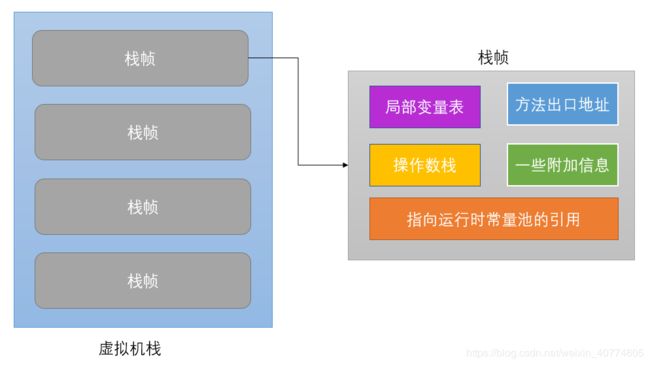
栈帧:是用于支持虚拟机进行方法调用和方法执行的数据结构,它是虚拟机运行时数据区中的虚拟机栈的栈元素。
每个栈帧中包括:局部变量表:用来存储方法中的局部变量(非静态变量、函数形参)。当变量为基本数据类型时,直接存储值,当变量为引用类型时,存储的是指向具体对象的引用。操作数栈:Java虚拟机的解释执行引擎被称为"基于栈的执行引擎",其中所指的栈就是指操作数栈。指向运行时常量池的引用:存储程序执行时可能用到常量的引用。方法返回地址:存储方法执行完成后的返回地址。
-
方法区
方法区是一块所有线程共享的内存逻辑区域,在JVM中只有一个方法区,用来存储一些线程可共享的内容,它是线程安全的,多个线程同时访问方法区中同一个内容时,只能有一个线程装载该数据,其它线程只能等待。方法区可存储的内容有:
- 类的全路径名
- 类的直接超类的权全限定名
- 类的访问修饰符
- 类的类型(类或接口)
- 类的直接接口全限定名的有序列表
- 常量池(字段,方法信息,静态变量,类型引用(class))等。
-
本地方法区
本地方法栈的功能和虚拟机栈是基本一致的,并且也是线程私有的,它们的区别在于虚拟机栈是为执行Java方法服务的,而本地方法栈是为执行本地方法服务的。
存储地址
扯完了内存结构,那我们上面提及的那些变量又是存到哪的呢?
我们分为以下几种讨论:
-
基本数据类型的存储
- 局部变量
基本数据类型的局部变量存储到的是虚拟机栈的栈帧中,数据本身的值就是存储在栈空间里面。
public method(){ int x = 502; int y = 502; int z = 520 }其实
int x = 502;在解释时会被拆为两条指令:int x; x = 502;首先
JVM会创建名为x的变量,存在于局部变量表中(int x;),然后在栈中查找,是否有字面值为“502”的内容,如果有则将该x指向这个地址;如果没有,则JVM将开辟一块空间,用于存储“502”,并将x指向该地址(x = 502)。因此,我们
声明并初始化基本数据类型的局部变量时,变量名及其字面值都是保持在栈中。那我们再来看看
y变量的执行过程:
JVM会先创建了一个变量y并在栈中找到了“502”的内容,这时y直接指向该内容。因而,栈中的数据在当前线程下是共享的。
- 局部变量

本例中,x和y共享字面值“502”,如果如果我们修改y的值会发生什么呢?
y = 222;
JVM会去栈中寻找字面量为“222”的内容,发现没有,就会开辟一块内存空间存储这个内容,并且把y指向这个地址。
由此可见:基本数据类型的数据本身是不会改变的,当局部变量重新赋值时,并不是在内存中改变局部变量所指向的字面量内容,而是重新在栈中寻找已存在的相同的数据,若栈中不存在,则重新开辟内存存新数据,并且把要重新赋值的局部变量的引用指向新数据所在地址 2。
- 成员变量
假设我们创建了以下这么一个类:
当我们调用以下代码时//People public class People{ String name; int age; //... }
其变量存储如下:People pp = new People();

这里我们需要记住的是:基本数据类型的成员变量名和值都存储于堆中,其生命周期和对象的是一致的。
-
类变量
类变量即类内静态变量,它储存在方法区常量池,类装载时就分配存储空间,随类消失而消失。注意,这个区域是线程共享的。public class Timer{ int static num = 0; int static status = TIMER_STOP; //... }上述变量的存储应为:

-
引用数据类型的存储
我算想明白了,其实它存储在哪里,和它是不是引用数据类型没有关系,而是看它属于局部变量还是实例变量还是类变量!那它为啥叫引用类型啊?那是因为它…字面值存储的是
对象的地址,并不是对象的实际内容。那么实际的内容存储在哪里?目前查阅的资料显示是在堆上。总结一下就是:
- 如果这个引用变量是一个
局部变量,那么变量名存储在栈中,而其指向的地址是在堆中的。 - 如果这个引用变量是一个
实例变量,那么变量名和其指向的地址是都是在堆中。 - 如果这个引用变量是一个
类变量,那么变量名是存储在方法区,而其指向的地址是在堆中。
- 如果这个引用变量是一个
值传递?引用传递?
结束了漫长的前戏,终于迎来了…正经的实验阶段了。
看完前面扯的这些,你肯定会说,哎呀,基本数据类型就是值传递嘛,引用数据类型就是引用传递嘛。别着急下结论嘛,长夜漫漫,我们坐下来喝杯茶,逐个论证。
第一回合:基本数据类型是值传递?
Demo
俺说了也不算,那写个小demo吧。
private static void setage(int age) {
System.out.println("setage()传入的年龄为:" + age);
age = 99;
System.out.println("setage()修改后的年龄为:" + age);
}
// TEST
public static void main(final String[] args) {
int Age = 22;
setage(Age);
System.out.println("调用setage()后的年龄:" + Age);
}
结局

剖析
main方法定义了一个基本数据类型的变量Age并赋予初值22,随后调用setage()方法,这时setage()方法压栈,实参赋值给形参int age = Age;。
这时处于栈顶的是setage(),它将执行一系列骚操作:
先将age值打印出来,22,后生仔哦。
然后将年龄调整为老爷爷级别:age = 99;
然后再打印一次年龄:99,真的变老爷爷了。
这时函数执行完了,setage()栈帧出栈。于是那个老爷爷age也消失了…
剩下的是main()中那个后生仔Age,不过南柯一梦,它起身笑笑,我还年轻!
结论
基本数据类型是值传递。(✔)
第二回合:引用数据类型是引用传递?
Demo
这里先定义一个People类
public class People {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void supper(People people) {
System.out.println("supper() 初始名 " + people.getName());
people.setName("Root");
System.out.println("supper() 改名后 " + people.getName());
}
}
测试如下:
People people = new People();
people.setName("Tourists");
people.supper(people);
System.out.println("main() Name: " + people.getName());
结局

结论
那么从效果上看,引用数据类型是引用传递咯。
这里俺不同意了,因为俺手里还有另一个Demo,为此要求加时赛,反正真金不怕火炼,来吧。
加时赛:引用数据类型是引用传递?
Demo
private static void setname(String name) {
System.out.println("setname()传入的名字为:" + name);
name = "Tourists";
System.out.println("setname()修改后的名字为:" + name);
}
// TEST
public static void main(final String[] args) {
String Name = "Root";
setname(Name);
System.out.println("调用setname()后的名字:" + Name);
}
结局

哎呀,咋又像值传递了呢,这 咋整 啊?
加时赛剖析
是不是有点出乎意料?下面分析一下吧。
首先main()执行:String Name = "Root";
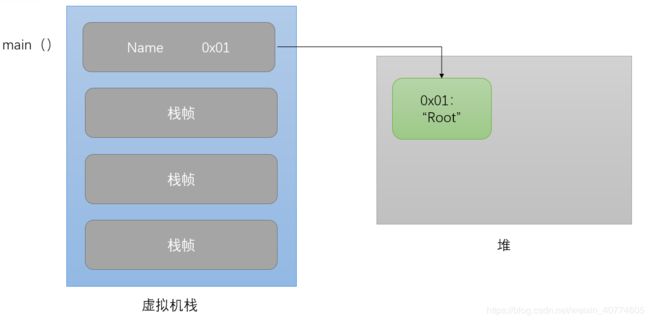
接着调用setname(Name);
这时setname()入栈,实参赋值给形参:

然后就被打印:传入的名字为:Root
接下来执行,name = "Tourists";由于堆内存中没有字面值“Tourists”的内容,因而JVM会创建,并让setname()的name指向它。
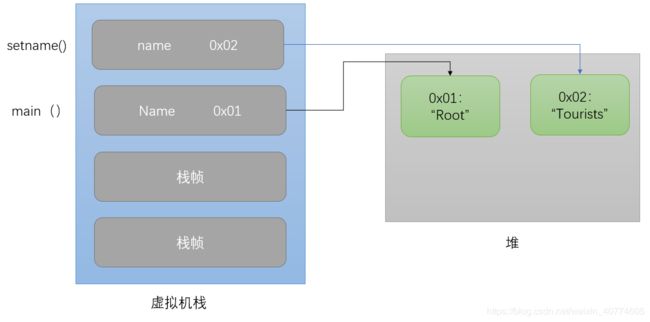
然后打印,修改后的名字为:Tourists
嗯,没毛病!接着,setname()就出栈了
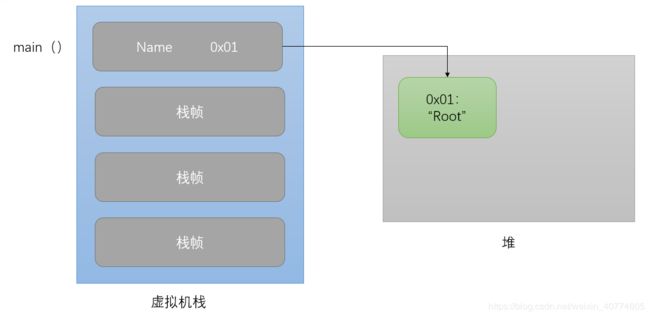
回到main()函数后,输出 调用setname()后的名字:Root
哎呀,那上面那个第二回合又是咋回事??
第二回合剖析
还是从main()中开始,创建了一个People实例people
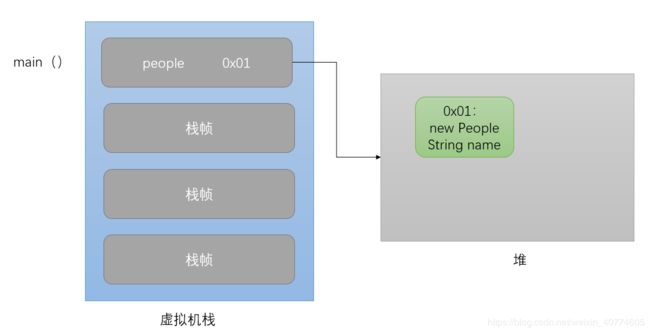
接着调用people.setName("Tourists");
这时,setName()方法入栈,实参赋值给形参数,由于未找到面值为“Tourists”的内容,于是JVM将创建它,并将name指向该值。随后执行this.name = name;于是就发生了下图所示变化。

再接着,setName()方法出栈。main()方法继续往下执行,执行到了people.supper(people);
supper()方法入栈,实参赋值给形参。

输出初始名,Tourists 没问题,Over~
随后是 people.setName("Root");
这个执行过程前面分析过了,执行后效果如下:
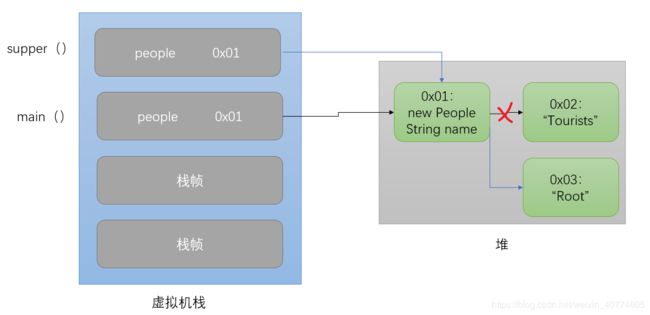
这时再输出改名后的值,输出改名后:Root 也没问题,Over~
再接下来,这个函数就执行完了,supper()方法出栈;main()回到栈顶。

这时我们再输出people的name属性,你说它是什么来着?
毫无意外,Root。Over~
结语

真相只有一个!
Java其实还是值传递的,只不过对于引用对象,值的内容是对象的引用4。
如果是对基本数据类型的数据进行操作,由于原始内容和副本都是存储实际值,并且是在不同的栈区,因此形参的操作,不影响原始内容。
如果是对引用类型的数据进行操作,分两种情况:
- 一种是形参和实参保持
指向同一个对象地址,则形参的操作,会影响实参指向的对象的内容。 - 一种是形参
被改动指向新的对象地址(如重新赋值引用),则形参的操作,不会影响实参指向的对象的内容 2。
参考鸣谢
沉默王二 - 188W+程序员关注过的问题:Java到底是值传递还是引用传递? ↩︎ ↩︎
假不理 - 这一次,彻底解决Java的值传递和引用传递 ↩︎ ↩︎ ↩︎ ↩︎
什么是Java内存模型 ↩︎
为什么说Java中只有值传递 ↩︎ ↩︎
《深入理解 JAVA 虚拟机》 ↩︎
深入理解JVM-内存模型(jmm)和GC ↩︎