翻译 Learning Unsupervised Video Object Segmentation through Visual Attention
练英语,翻的并不好,参考。
利用视觉注意力 学习无监督视频目标分割
摘要
这篇论文在无监督视频物体分割(UVOS)任务上进行系统研究。利用精细地标识三个含有动态眼球追踪(eye-traking)流行视频分割数据集(DAVIS Youtube-Objects and SegTrack),我们第一次定量地验证了人类观察者视觉注意行为的高度一致性,并发现,在动态的、任务驱动的观看过程中,人类注意力与明确的主要目标判断之间存在很强的相关性。这些新奇的观测为深入了解UVOS背后的基本原理提供了一个视角。受这些发现的启发,我们将UVOS解耦为两个子任务:①在时空域,UVOS驱动的动态视觉注意力预测(DVAP),②在空间域,注意力引导的目标分割(AGOS)。我们的UVOS解决方案有三个主要优点:1)不使用昂贵的视频分割标识的模块化训练,而是使用更便宜的动态注视数据来训练初始的视频注意力模块,同时使用现有的注视-分段配对静态/图像数据来训练后续的分割模块;2)通过多源学习全面理解前景;3)从生物学上激发和评估注意力的额外可解释性。在流行基准上的实验表明,即使不使用昂贵的视频对象掩模标识,我们的模型也能实现与最新技术相比无法比拟的性能。
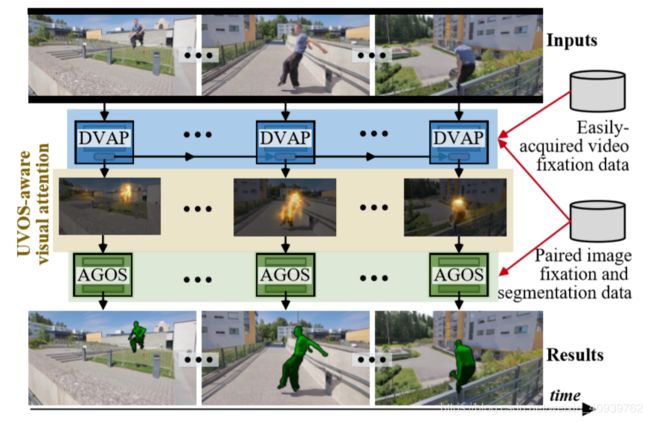
图一 我们的UVOS 解决方案有两个关键步骤:注意力引导物体分割(AGOS)和动态视觉注意力预测(DVAP)。DVAP的UVS感知注意力作为一个中间的视频对象表示,将我们的方法从依赖于大开销的视频物体标识中解放出来,并带来更好的可解释性。
1.简介
使UVOS自动地从视频背景中分割出首要物体的区域,是计算机视觉中的一个长期研究挑战,而且在很多应用方面有潜在的利益,例如,动作识别和物体追踪。由于UVOS的用户缺少互动,在现实世界场景下,自动识别复杂背景中的主体成为挑战。
深度学习最近在积极探索解决UVOS。尽管取得了可喜的成果,目前基于深度学习的UVOS模型往往依赖昂贵的像素级视频分割注释数据直接将输入的视频帧映射到相应的分割掩码中,它们受到限制,并且通常缺乏对它们选择前景对象背后的基本原理的明确解释。类似的问题也发生在一个密切相关的研究领域,视频突出目标检测(video object detection, VSOD),它的目的是为每一帧提取连续的显著性图,突出最重要的视觉区域。一个生物学的解释为选择突出的目标区域是必不可少的。视频突出目标检测的结果被用作UVOS的重要线索或预处理步骤。
在这篇论文中,我们强调了人类视觉注意力在UVOS(以及它的相关任务——视频突出物体检测)中的价值。根据认知心理学,在视觉认知中,人类能够快速地注意到视觉刺激中最重要的部分,使他们高效地达到目标(‘,’后面感觉多余)。我们因此论证“人类视觉注意力是驱动UVOS的潜在机制”。UVOS中最瞩目的应该是人类最关注的,也就是物体的选择应该是人类注意力判定。
为了证实这一新理论,我们拓展了三个流行视频分割数据集,并在真人UVOS设置中加入真实人类的标识。注视数据是通过专业眼球追踪设备,由20名观察者观看190个视频序列25049帧得到的。据我们所知,这是第一次试图收集UVOS感知人类注意力数据。这样的综合数据便于我们进行两个重要的实验,即,将受试者之间的一致性 以及 人类动态注意力 和 显性客观判断之间的关系进行量化。从我们的定量分析中发现了两个关键的观察结果:
- 在UVOS任务中,人类观察者间存在注意力行为相关性,虽然主体的标识有时在极为多变的动态场景中是不适定的。
- 人的注视与人对主要对象的显式判断之间存在着很强的相关性。
这些发现从人类注意力的角度提供了一个洞察UVOS背后原理的视角。受此启发,我们将UVOS分解为两个子任务,DVAP和AGOS。因此我们为DVAP和AGOS设计了一种新兴的具有两个紧密耦合组件的UVOS模型(见图一)。这种任务分解的一个额外优势在于模块化训练和数据获取。相对于使用昂贵的视频分割注释,相对容易获取的动态固定数据可以用来训练DVAP,现有的大规模固定分割成对注释可以用来训练AGOS模型。这是因为AGOS学习学习将一个单独的输入帧和注视数据映射成一个分割的掩膜,因此只需要静态图像数据。粗略地说,视觉注意力作为一个中间层次的表现,它连接了动态前景特征建模和静态注意感知对象分割。这样的设计自然反映了现实世界人类行为,即,首先在动态观看时将粗略的
注意力集中在重要的地方,然后集中在细粒度、像素级的对象分割上。
在我们的UVOS模型中,DVAP模型建立在CNN-convLSTM架构上,convLSTM以静态CNN特征序列为输入,学习捕获动态的视觉注意力,而AGOS模块则基于一个FCN架构。直观的,DVAP通知AGOS对象在每个帧中的位置,然后AGOS执行细粒度的对象分割。此外,我们的模型还有几个重要的特点:
- 全可微监督注意机制。对于AGOS,利用DVAP的注意作为神经注意机制,使得整个模型完全可微、端到端可训练。在高层次上,DVAP可以作为视图注意力网络为AGOS提供了明确的时空注意机制,并以监督的方式进行训练。
- 从大规模可负担的数据中学习。深度学习模型往往需要大量的数据,而大规模的视频分割注释数据是非常昂贵的。我们的模型利用了更便宜的动态凝视和存在大规模的注意力分割配对图像数据,以达到相同的目标。实验结果表明,该模型在,没有在真实视频分割数据上训练的情况下,获得了良好的分割效果。
- 生物启发和可评估的解释能力。从DVAP中获得的注意力不仅使我们的模型能够关注重要的对象,而且还提供了一个额外的维度来解释我们的模型所关注的内容。这种可解释性是有意义的(受生物学启发)和可评估的(w.r.t.人类凝视记录)。
总之,我们提出了一个强大,完全可微,由生物启发的UVOS模型来完全开发视觉注意力的价值。提出的模型产生了一个在流行基准上的最新的结果。我们期望这项工作,连同我们新收集的数据,能够为UVOS和视频突出目标检测背后的潜在机制提供帮助,并激发更多这方面的研究。
2.相关工作
无监督视频对象分割UVOS。早期的UVOS方法通常基于手工制作的特征和启发式,如长期点轨迹、运动边界、客观性和显著性。后来,随着神经网络的复兴,提出了许多基于深度学习的模型,这些模型通常使用基于多层感知器的移动对象检测器,采用两流架构,或CNN编解码器结构。由于深度神经网络强大的学习能力,这些深度无人机模型总体上实现了很好的性能。
尽管这些模型使用现实感(或前景地图,一个相似的概念),它们要么是缺乏端到端的可训练性或基于对象层次的显著性的启发式方法,而不是一种明确的、受生物启发的视觉注意力表达。它们都没有量化视觉注意力和显式主视频对象确定之间的一致性。此外,以前的深度UVOS模型局限于大规模、注释良好的视频数据的可用性。相比之下,通过利用动态视觉注意力作为中间视频对象表示,我们的方法为缓解这一问题提供了一种可行的方法。
视频突出目标检测。 VSOD是与UVOS非常接近的一个主题。VSOD[15,47,75,73,76]的目的是为视频序列中的每个像素赋予一个灰度显著值。连续的显著性映射对于广泛的应用是有价值的,例如裁剪、对象跟踪和视频对象分割。然而,以前的VSOD只是简单地使用UVOS数据集进行基准测试,缺乏生物学证据支持这种选择。在这个作品中,通过论证人类的注视和明确的物体判断之间的一致性,我们对UVOS和VSOD进行了深入的了解,它们有一个统一的基础,即,自上而下的任务驱动的视觉注意机制。
**视觉注意力的预测。**人的注意机制在视觉信息的感知和加工过程中起着至关重要的作用。在过去的十年里,计算机视觉社区已经做出了一些努力,对这种选择性注意过程进行了计算机建模。根据潜在的机制,注意力模型可以分为自底向上(stimuli-inspired)和自顶向下(task-driven)两类。早期注意模型是基于生物启发特征(颜色、边缘、光流等)和视觉注意的认知理论(注意转移[37]、特征整合理论、引导搜索等)。最近,基于深度学习的注意力模型被提出,并普遍产生了更好的性能。
但是,以前的大多数方法都是使用静态的、自下而上的模型,并且专门设计用于在动态场景中建模由UVOS驱动的、自上而下的注意力。以前的动态眼球追踪数据集是在自由浏览或其他任务驱动设置下构建的(seeTable1)。在这项工作中,大量的视频分割数据集被仔细收集在UVOS设置。因此,我们首次为guidingUVOS学习了一个动态的、自顶向下的注意模型。通过以上努力,我们希望在UVOS和视觉注意力预测之间建立更紧密的联系。

神经网络中的可训练注意力。 近年来,将神经网络与全可微注意机制相结合的研究有了很大的发展。神经注意刺激了人类的选择性注意机制,并允许网络将注意力集中在输入中与任务最相关的部分。它展示了在自然语言处理和计算机视觉任务方面的成功,如机器翻译、图像字幕、可视化问答、分类等。这些神经注意是通过隐式的、目标驱动的和端到端的方式学习的。
我们的DVAP模块也可以看作是一种神经注意机制,因为它是端到端可训练的,并用于对AGOS模型的特征进行软加权。它在UVOS感知特性、显性训练能力(具有地面真实数据的可用性)和时空应用领域与其他技术不同。
3.UVOS感知眼球追踪数据收集
我们的工作目标之一是为三个公共视频分割数据集提供额外的注视标识。图2显示了一些带有UVOS感知的眼球跟踪注释的示例帧,以及每个数据集上的视觉注意力分布。

刺激物:动态刺激物来自DAVIS16[55]、youtube对象[57]、SegTrackV 2[42]。DAVIS16是一个流行的UVOS基准,包含50个视频序列,共3,455帧。Youtube-Objects是一个大数据集,有126个视频,覆盖了10个常见对象类别,总共有20647帧。SegTrackV 2由14个短视频组成,共947帧。
仪器:观察者的眼球运动用一个250hz的SMI RED250眼动仪(SensoMotoric Instruments)记录。动态刺激以1440×900的分辨率和原始速度显示在19英寸的计算机显示器上。根据产品说明书的建议,使用头枕来保持大约68厘米的观看距离。
参与者:20名参与者(男性12名,女性8名,年龄21 - 30岁),通过眼动仪校准,固定物下降率低于10%,符合我们的实验。所有患者视力正常/正常,从未见过刺激物。
记录方案:实验人员首先运行标准的SMI校准程序,并对其进行推荐设置,以获得最佳结果。在观看过程中,刺激视频被随机播放,参与者被要求识别每个刺激中出现的主要对象。由于我们的目标是探索人类在UVOS环境下的注意力行为,每个刺激被重复显示三次,以帮助参与者更好地捕捉视频内容。这种数据捕获设计是由协议[19]完成的。为了避免疲劳,在两者之间插入5秒钟的黑屏。此外,刺激分为5个阶段。在经历了一段视频后,参与者可以休息了。最后,在190个视频中记录了20名受试者共12,318,862次注视。
4.深度数据分析
受试者间一致性:我们首先进行实验,分析受试者的眼动一致性。为了量化这种受试者间一致性(ISC),遵循[45]中的协议,随机选择一半受试者的数据作为测试子集,其余数据作为新的真实的子集。然后,使用经典的视觉注意力评价度量AUC-Juddy[7]对测试子集进行ISC测量。实验结果如表2所示。有趣的是,在所有三个数据集中,人类受试者的注意力行为存在高度一致性。相关得分(0.899onDAVIS16,0.876onYoutube-Object,0.883 on SegTrackV 2)显著高于随机(0.5)。机会水平是随机地图的精度,每个像素的值都是在0到1之间均匀随机绘制的。这一新的观察进一步表明,尽管“无监督视频对象”经常被认为是不明确的[66,1,74],但仍然存在一些“普遍认同的”视觉上的重要线索,能够稳定而持续地吸引人的注意力。

视觉注意与视频目标判定的相关性:研究人类视觉注意与视频主要目标判定是否一致是很有必要的,这是之前从未有过的研究。在这里,我们使用[4]提出的实验方案来计算任务间相关性(ITC)。更具体地说,我们使用分割掩膜来解释固定地图。在AUC-Juddy度量的省略过程中,将人类注视点作为正集,从其他非注视点处采样的一些点作为负集。结果显示,视觉注意力落在背景上的概率并没有显著高于相应的概率水平。以youtub - objects为例,使用t检验,相关分数0.733 (std = 0.105)显著高于随机(p<0.05)。这一观察揭示了人类动态视觉注意力和视频对象决定之间的强烈相关性。
5.提出的UVOS方法
5.1 问题规划
用{It ∈R(W,H,3)}(t=1~T)表示T帧的输入视频,然后UVOS的目标是生成相应的二分类视频物体分割掩膜。许多最近提出的UVOS方法学习一个DNN作为映射函数,直接把输入映射成分割掩码。为了学习这种直接的输入-输出映射FUVOS,需要大量的像素级的视频分割注释,而这些注释的获取是非常昂贵的。

(数学符号不好打,直接看图)
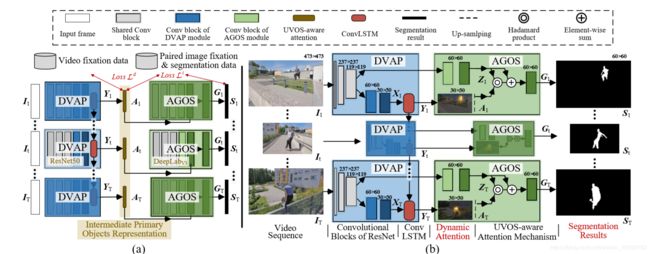
Figure3.Illustration of the proposed UVOS model. (a)Simplified schematization of our model that solves UVOS in a two-step manner, without the need of training with expensive precise video object masks. (b) Detailed network architecture, where the DVAP (§5.2) and AGOS (§5.3) modules share the weights of two bottom conv blocks. The UVOS-aware attention acts as an intermediate object representation that connects the two modules densely. Best viewed in color. Zoom in for details.
图3。UVOS模型的图解。(a)简化我们的模型,以两步的方式解决UVOS,不需要昂贵的精确视频对象掩模进行训练。(b)详细的网络架构,其中DVAP(§5.2)和AGOS(§5.3)模块共享两个底层conv块的权重。UVOS感知的注意力作为一个中间的对象表示,紧密地连接两个模块。彩色效果最佳。放大细节。
我们提出一种输入-注意力-输出的映射策略来处理UVOS。特别的,一个DVAP模型Fdvap首先被设计出来,用于预测动态UVOS-感知视觉注意力
![]()

一个AGOS模型Fagos,输入It和相应的注意力图At,然后用于生成最终分割结果St:
St = Fagos(It,At) t∈1-T。
如图3 (a)所示,{At}T =1编码了静态对象信息和时间动态,使得AGOS能够集中于空间域的细粒度分割,即,分别为每一帧应用AGOS。从本质上说,视觉注意力、视觉启发、中间对象呈现、链接、交互,通过告诉我们的模型在看什么,提供了一个明确的解释。
5.2 DVAP模型
DVAP模块建立在CNN-convLSTM架构上(见图3(b)),其中的卷积层借鉴了ResNet50[22]的前五个卷积块。为了保留更多的空间细节,我们将最后一个块的步幅减少到1。给定典型的473×473空间分辨率的输入视频序列{It}t=1-T,将来自CNN网络顶层的空间特征序列{Xt∈R 30×30×2048}t=1-T输入到convLSTM中进行学习动态视觉注意力。动态的视觉注意。作为传统全连接LSTM的卷积对应物,ConvLSTM[59]将卷积运算引入到输入到状态和状态到状态的转换中。ConvLSTM在这里很受欢迎,因为它可以同时保存空间细节和建模时间动态。我们的DVAP模块Fdvap可以表示为:
![]()
式中Yt表示第t步时刻convLSTM的三维张量隐藏状态(32通道),R为从隐藏状态产生注意图的读出函数,用s形激活函数实现为1×1卷积层。
在下一节中,我们将使用DVAP作为一种注意力机制来引导AGOS更多地集中于视觉上重要的区域。一个额外的优势的设计在于理清前景对象的时空特点,学习dynamic-gaze DVAP捕获时间信息的数据,从而允许前关注只在空间区域单像素分割(受益于现有的大规模图像数据集与固定搭配和对象分割注释)。
5.3 AGOS模块
从DVAP获得的注意力提示主要对象的位置,为AGOS提供像素级分割的信息提示,这是通过神经注意结构实现的。在深入研究我们的模型之前,我们首先给出一个神经注意机制的一般公式。
生成神经注意力的机制:神经注意机制使网络具有聚焦于输入特征子集的能力。它通过乘法操作计算一个软-掩膜来增强特征。i为d维输入向量,z是一个k维特征向量,a属于[0,1]^k是一个注意力向量,k维向量g是一个注意力增强特征,fa是个注意力网络,神经注意力就是下面这个:

那个圈里点是按位乘。fz表示一个特征提取网络。一些神经注意模型在注意函数fA中加入了soft-max约束条件,将注意值限制在0 ~ 1之间。由于上面的注意力框架是完全可微的,所以它是端到端的可训练的。然而,由于缺乏对注意力的“基础事实”的关注,它被训练成一种含蓄的方式。
显式的、时空的和UVOS感知的注意机制:我们将DVAP作为一种注意力机制集成到AGOS中。设Zt、Gt分别表示具有相同维数的分割特征和注意一瞥,则我们的uvs -aware attention表示为:
时空注意力:

时空特征增强:

Fz从输入帧It中提取分割特征。Gc和Zc是G和Z在d通道的切片。如你所见,我们的UVOS-aware attention和时间特征一起编码空间前景信息,使AGOS模型能够在每个帧上搞个物体分割。对于注意力趋近0的位置,相关特征反馈会被狠狠抑制。这可能会丢失重要信息。受[22,68]启发,特征增强步骤在Eq6被用一个残余的形式增强。

该策略保留了原始信息(即使注意值非常小),同时有效地增强了与对象相关的特性。此外,由于地面真实注视数据的可用性,我们的UVOS感知注意力机制以一种明确的方式进行训练(详见§5.4)。
AGOS模块也构建在ResNet[22]的卷积块上,并使用DeepLabV 3[10]中提出的ASPP模块进行了修改。输入维度473x473x3,能够从ASPP模型Faspp中提取出分割特征60x60x1536。注意力图At也被双线性插值乘2上采样。最终AGOS模型长这样:

DVAP和AGOS中的知识共享:这俩用了相同的底层网络架构(ResNet的conv1-conv5),从不同的角度捕获信息。我们发展了一个技术来鼓励两个网络间的知识共享,而不是分别学他们俩。尤其是,我们允许两个网络分析前三个卷积块,然后分别学习其他高层。这事因为底层典型地捕获底层信息(边界、角落等),而顶层趋向于学习高等级,具体任务的知识。除此之外,这种共享权重提高效率,减少了参数存储。
5.4实现细节
Training Loss:对DAVP,输入473x473x3,预测一个注意力图A∈[0,1]^(30x30)。由P∈[0,1]30x30维和F∈{0,1}(30x30)得到groud-truth连续注意力图和二分固定图。F是个离散图,记录一个像素是否受人眼关注,P在F被一个高斯过滤器模糊后获得。loss函数Ldavp长这样:

Lce是经典交叉熵,Lcc,Lnss,Lsim分别由常用的归一化扫描路径显著性(NSS)、相似度(SIM)、线性相关系数(CC)三个视觉注意力评价指标推导而来。由于综合考虑了[26]中不同的量化因素,这种组合可以提高性能。我们使用特性作为主要的损失,并设置α1 =α2 =α3 = 0.1。
对AGOS,给它I,它就产生一个最终的分割预测S(60x60)。用M{0,1}(60x60)表示ground-truth二分掩膜,Lagos长这样:
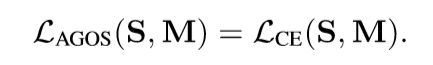
训练方案:我们利用视频注视数据和注意力-分割配对图片数据来迅练整个UVOS模型。该训练过程在视频训练训练批和图像训练批上迭代执行。具体来说,在视频训练批中,我们只用动态注视数据来训练DVAP。给了训练视频序列It,用{At,Pt,Ft}t=1-T来表示相关注意力预测,ground-truth连续注意力图和离散固定图,我们训练模型来最小化loss:
 上标d代表动态视频数据。注意我们不考虑Lagos来保存昂贵的单像素分割groud-truth。
上标d代表动态视频数据。注意我们不考虑Lagos来保存昂贵的单像素分割groud-truth。
图像训练批量包含多个注意分割成对图像掩模,用于同时训练DVAP和AGOS模块。设{I,S,F,M}为图像训练批次中的训练样本,其中包含静态图像和对应的ground-truth(即,持续注意映射,二值固定映射,分割掩码)。综合损失函数结合了ldvap和lagos:

其中上标s用来强调静态性质。利用静态数据,将DVAP中convLSTM的总时间跨度设置为1。每个视频训练批次使用来自同一视频的10个连续帧。视频和起始帧都是随机选择的。每个图像训练批次包含10个随机采样的图像。
后面是实验和总结。累死我了,不搞了。