TensorFlow学习记录:读取已保存的.ckpt模型
之前写了一篇使用VGGNet对Cifar10数据集分类的博客,里面最后一句代码对已训练好的模型进行了保存,最近学习了如何读取已训练好的.ckpt模型,所以在这里记录一下。
在使用VGGNet对Cifar10数据集分类中,代码的最后一行使用了tf.train.Saver类的save()函数将Tensorflow模型保存到了一个指定路径下,然后这个目录下就多出了四个文件,如下图所示:

其中,checkpoint文件是一个文本文件,用文本编辑器就能打开。它保存了一个目录下所有的模型文件列表。下图为该文件的内容:
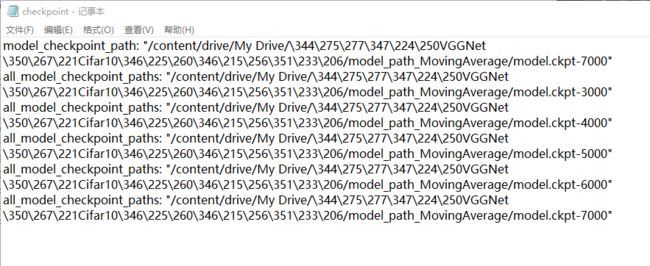
其中,model_checkpoint_path记录的是当前最新模型的路径,all_model_checkpoint_paths记录的是已保存的5个模型的路径。在Tensorflow中训练并保存模型的时候,会自动保存最新的5个模型,如果后面还有模型要保存的话,Tensorflow会自动删除最早保存的模型以及相应的文件,并且也会自动更新checkpoint文件。
1.模型保存为.ckpt文件代码实现
其余3个文件全部都是二进制文件,我们是没有办法直接打开的。这些文件的作用分别如下表所示:
| 文件名 | 说明 |
|---|---|
| model.ckpt-199999.data-00000-of-00001 | 保存了TensorFlow程序中每一个变量的取值 |
| model.ckpt.index | 保存了每一个变量的名称,是一个string-string的table,其中table的key值为tensor名,value值为BundleEntryProto,每个BundleEntryProto表述了tensor的metadata(用于解释或帮助理解信息的数据) |
| model.ckpt.meta | 保存了计算图的结构,或者可以说是神经网络的结构 |
先定义一个简单的两个变量相加的例子,并且保存为模型
import tensorflow as tf
a = tf.Variable(tf.constant([1.0,2.0],shape=[2]),name="a")
b = tf.Variable(tf.constant([3.0,4.0],shape=[2]),name="b")
result = a+b
init_op = tf.global_variables_initializer()
saver =tf.train.Saver() # 创建一个Saver类
with tf.Session()as sess:
sess.run(init_op)
saver.save(sess,"G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/普通模型/model.ckpt") #Saver类的save()函数用于保存模型,sees是当前会话,后面的是保存路径。如果在训练模型的时候后面还可以加一个参数global_step=当前训练步数
恢复模型的时候,先定义模型里面的所有运算过程,并且变量的name属性须与模型中储存的变量的name属性保持一致(其实也可以不一致,具体做法下面会提到),这样就可以通过变量将已保存的模型加载进来。这部分实现的代码如下:
import tensorflow as tf
# 先定义模型里面的所有运算过程,并且变量的name属性须与模型中储存的变量的name属性保持一致
a = tf.Variable(tf.constant([1.0,2.0],dtype=tf.float32,shape=[2]),name="a")
b = tf.Variable(tf.constant([3.0,4.0],dtype=tf.float32,shape=[2]),name="b")
result = a+b
saver = tf.train.Saver() # 创建一个Saver类。注意,这里当Saver类的对象调用restore()函数时会仅恢复上面所定义的运算过程和变量,假设模型中有保存了一个a*b的运算操作,或者对a和b使用了滑动平均算法,如果这里没有重新定义a*b的运算操作,或者对a和b使用滑动平均算法的话,是不会被恢复进来的,所以当你要打印当前默认计算图的时候是不会有a*b的运算操作或者a和b的影子变量的,一定要注意。
with tf.Session()as sess:
# 使用restore()函数加载已经保存的模型
saver.restore(sess,"G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/普通模型/model.ckpt")
print(sess.run(result))
# 输出[4. 6.]
有时我们觉得重复定义和模型一样的运算过程非常麻烦,希望可以把计算图也恢复进来。Tensorflow支持直接加载已经持久化的计算图。函数import_meta_graph()实现了这个功能,并且还会把所有计算操作都恢复进来,其输入参数为.meta文件的路径(注意.meta文件并没有存储参数的值)。这个函数返回一个Saver类的对象,再调用Saver对象的restore()函数就可以恢复所有参数了。这部分的代码如下:
import tensorflow as tf
#省略了定义计算图上运算的过程,取而代之的是通过.meta文件直接加载持久化的计算图
meta_graph = tf.train.import_meta_graph("G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/普通模型/model.ckpt.meta")
with tf.Session()as sess:
# 使用restore()函数加载已经保存的模型
meta_graph.restore(sess,"G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/普通模型/model.ckpt")
# 获取默认计算图上指定节点处的张量
print(sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
print(sess.run(tf.get_default_graph().get_tensor_by_name("a:0")))
print(sess.run(tf.get_default_graph().get_tensor_by_name("b:0")))
# 输出
# [4. 6.]
# [1. 2.]
# [3. 4.]
get_default_graph()函数用于获取当前的默认计算图,get_tensor_by_name()函数用于获取计算图中指定节点的张量(add:0表示节点add的第一个输出)。
刚才说了,恢复模型的时候,先定义模型里面的所有运算过程,并且变量的name属性必须与模型中储存的变量的name属性保持一致,如果变量的name属性和模型中变量的name属性不一致的话就不行了码?其实是有办法解决的,可以在初始化Saver类时以字典(Dictionary)的方法,将新定义的变量和模型中的变量联系起来,使用这种方法初始化Saver类时的代码为:
saver = tf.train.Saver({"a":a,"b":b})
初始化Saver类时使用字典的方法指定了模型中的变量a和新定义的变量a(name属性可以与模型中的变量a的name属性不一样)相关联,模型中变量b和新定义的变量b相关联。
通常我们不会刻意更改变量的name属性,然后使用这种字典的方式进行关联,但当我们在使用变量滑动平均值的时候,如果在加载模型时直接将影子变量的值赋值给原变量,那么就可以省略单独调用函数来获取变量滑动平均值的过程了,这样大大方便了滑动平均模型的使用。下面的代码先定义两个变量和计算这两个变量的滑动平均值,并保存它们。
import tensorflow as tf
a = tf.Variable(0,dtype=tf.float32,name="a")
b = tf.Variable(0,dtype=tf.float32,name="b")
# 先创建滑动平均类,再通过apply()函数将滑动平均算法赋值给所有变量
average_class = tf.train.ExponentialMovingAverage(0.99)
average_op = average_class.apply(tf.all_variables())
for variables in tf.global_variables():
print(variables.name)
# 输出
# a:0
# b:0
# a/ExponentialMovingAverage:0
# b/ExponentialMovingAverage:0
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session()as sess:
sess.run(init_op)
sess.run(tf.assign(a,10))
sess.run(tf.assign(b,5))
sess.run(average_op)
print(sess.run([a, average_class.average(a)])) # 计算a的滑动平均值
print(sess.run([b, average_class.average(b)])) # 计算b的滑动平均值
# 输出
# [10.0, 0.099999905]
# [5.0, 0.049999952]
saver.save(sess,"G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/滑动平均模型/model.ckpt")
通过滑动平均类生成的影子变量有一种固定的命名方式,那就是在原变量后面加上“ExponentialMovingAverage”。这些影子变量会被加入到原变量所属的集合中,所以在第一个print中,原变量和影子变量都被输出(此时还没有执行滑动平均操作)。
可以通过变量重命名的方式将变量的滑动平均值读取到原变量。下面代码实现了将变量a和b的滑动平均值读取到a和b中:
import tensorflow as tf
a = tf.Variable(0,dtype=tf.float32,name="a") # name属性一定要和模型中的变量一样
b = tf.Variable(0,dtype=tf.float32,name="b")
# 在使用字典方式给变量赋值时可以不定义滑动平均类
average_class = tf.train.ExponentialMovingAverage(0.99)
# 使用字典方式从本地读取影子变量赋值给上面定义的变量a和b
saver = tf.train.Saver({"a/ExponentialMovingAverage":a,"b/ExponentialMovingAverage":b})
# average_class.variables_to_restore()直接生成了Saver类所需的变量重命名字典,所以下面这行代码和上面的效果一样
# saver = tf.train.Saver(average_class.variables_to_restore())
with tf.Session()as sess:
saver.restore(sess,"G:/学习/TensorFlow 深度学习算法原理与编程实践/模型持久化/滑动平均模型/model.ckpt")
print(sess.run([a,b]))
# 输出[0.099999905, 0.049999952]
print(average_class.variables_to_restore())
# 输出{'b/ExponentialMovingAverage': , 'a/ExponentialMovingAverage': }
# for op in tf.get_default_graph().get_operations(): # 查看当前计算图中所有的运算操作
# print(op.name)
2.将VGGNet训练保存的模型加载进来并计算在测试集上的准确率
在加载之前训练保存的VGGNet模型之前,首先要定义和搭建VGGNet网络时一样的前向传播过程,而且还要保持所用到的命名空间和变量名的一致,然后使用上面所展示的方法加载已保存的模型,最后计算模型在测试集上的准确率。
import tensorflow as tf
import numpy as np
import time
import math
import Cifar10_data
batch_size=12
num_examples_for_eval=10000
learning_rate=0.01 #初始学习速率
learning_rate_decay=0.99 #衰减系数
data_dir="/content/drive/My Drive/cifar-10-batches-bin"
# 定义和搭建VGGNet网络时一样的前向传播过程,而且还要保持所用到的命名空间和变量名的一致,可以直接复制粘贴
def conv_op(input,name,kernel_h,kernel_w,num_out,step_h,step_w,para,reuse):
num_in=input.get_shape()[-1].value
with tf.variable_scope(name,reuse=reuse):
kernel=tf.get_variable("weights",shape=[kernel_h,kernel_w,num_in,num_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv=tf.nn.conv2d(input,kernel,(1,step_h,step_w,1),padding="SAME")
biases=tf.get_variable("bias",[num_out],initializer=tf.constant_initializer(0.0))
activation=tf.nn.relu(tf.nn.bias_add(conv,biases))
para+=[kernel,biases]
return activation
def fc_op(input,name,num_out,para,reuse,regularizer,avg_class):
num_in=input.get_shape()[-1].value
with tf.variable_scope(name,reuse=reuse):
weights=tf.get_variable("weights",shape=[num_in,num_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer())
if regularizer != None:
tf.add_to_collection("losses",regularizer(weights))
biases=tf.get_variable("bias",[num_out],initializer=tf.constant_initializer(0.0))
if avg_class ==None:
activation=tf.nn.relu_layer(input,weights,biases)
else:
activation=tf.nn.relu_layer(input,avg_class.average(weights),avg_class.average(biases))
para+=[weights,biases]
return activation
def inference_op_loss(input,keep_prob,reuse,regularizer,avg_class):
parameters=[]
#第一段卷积,输出大小为16*16*64(省略了第一个batch_size参数)
conv1_1=conv_op(input,name="conv1_1",kernel_h=3,kernel_w=3,num_out=4,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv1_2=conv_op(conv1_1,name="conv1_2",kernel_h=3,kernel_w=3,num_out=64,step_h=1,step_w=1,para=parameters,reuse=reuse)
pool1=tf.nn.max_pool(conv1_2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool1")
#第二段卷积,输出大小为8*8*128(省略了第一个batch_size参数)
conv2_1=conv_op(pool1,name="conv2_1",kernel_h=3,kernel_w=3,num_out=128,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv2_2=conv_op(conv2_1,name="conv2_2",kernel_h=3,kernel_w=3,num_out=128,step_h=1, step_w=1,para=parameters,reuse=reuse)
pool2=tf.nn.max_pool(conv2_2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool2")
#第三段卷积,输出大小为4*4*256(省略了第一个batch_size参数)
conv3_1=conv_op(pool2,name="conv3_1",kernel_h=3,kernel_w=3,num_out=256,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv3_2=conv_op(conv3_1,name="conv3_2",kernel_h=3,kernel_w=3,num_out=256,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv3_3=conv_op(conv3_2,name="conv3_3",kernel_h=3,kernel_w=3,num_out=256,step_h=1,step_w=1,para=parameters,reuse=reuse)
pool3=tf.nn.max_pool(conv3_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="bool3")
#第四段卷积,输出大小为2*2*512(省略了第一个batch_size参数)
conv4_1=conv_op(pool3,name="conv4_1",kernel_h=3,kernel_w=3,num_out=512,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv4_2=conv_op(conv4_1,name="conv4_2",kernel_h=3,kernel_w=3,num_out=512,step_h=1,step_w=1,para=parameters,reuse=reuse)
conv4_3=conv_op(conv4_2,name="conv4_3",kernel_h=3,kernel_w=3,num_out=512,step_h=1,step_w=1,para=parameters,reuse=reuse)
pool4=tf.nn.max_pool(conv4_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool4")
#第五段卷积,输出大小为1*1*512(省略了第一个batch_size参数)
conv5_1 = conv_op(pool4, name="conv5_1", kernel_h=3, kernel_w=3, num_out=512, step_h=1, step_w=1, para=parameters,reuse=reuse)
conv5_2 = conv_op(conv5_1, name="conv5_2", kernel_h=3, kernel_w=3, num_out=512, step_h=1, step_w=1, para=parameters,reuse=reuse)
conv5_3 = conv_op(conv5_2, name="conv5_3", kernel_h=3, kernel_w=3, num_out=512, step_h=1, step_w=1, para=parameters,reuse=reuse)
pool5 = tf.nn.max_pool(conv5_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME", name="pool5")
pool_shape=pool5.get_shape().as_list()
flattened_shape=pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped=tf.reshape(pool5,shape=[-1,flattened_shape],name="reshaped")
#第一个全连接层
fc_6=fc_op(reshaped,name="fc6",num_out=4096,para=parameters,reuse=reuse,regularizer=regularizer,avg_class=avg_class)
fc_6_drop=tf.nn.dropout(fc_6,keep_prob,name="fc6_drop")
#第二个全连接层
fc_7=fc_op(fc_6_drop,name="fc7",num_out=4096,para=parameters,reuse=reuse,regularizer=regularizer,avg_class=avg_class)
fc_7_drop=tf.nn.dropout(fc_7,keep_prob,name="fc7_drop")
#第三个全连层
with tf.variable_scope("fc8",reuse=reuse):
fc_8_weights=tf.get_variable("weight",shape=[fc_7_drop.get_shape()[-1],10],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer())
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc_8_weights))
fc_8_biases=tf.get_variable("bias",[10],initializer=tf.constant_initializer(0.0))
if avg_class==None:
fc_8=tf.matmul(fc_7_drop,fc_8_weights)+fc_8_biases
else:
fc_8=tf.matmul(fc_7_drop,avg_class.average(fc_8_weights))+avg_class.average(fc_8_biases)
parameters+=[fc_8_weights,fc_8_biases]
return fc_8,parameters
x = tf.placeholder(tf.float32,[batch_size,32,32,3])
y_ = tf.placeholder(tf.int32,[batch_size])
coord = tf.train.Coordinator()
images_train, labels_train = Cifar10_data.inputs(data_dir=data_dir, batch_size=batch_size, distorted=True)
images_test, labels_test = Cifar10_data.inputs(data_dir=data_dir, batch_size=batch_size, distorted=None)
# 由于只是计算在测试集上的准确率,不涉及训练过程,所以不会传入正则化方法,也不会计算滑动平均值
fc_8 ,parameters = inference_op_loss(x,keep_prob=1.0,reuse=False,regularizer=None,avg_class=None)
correct_prediction = tf.equal(tf.argmax(tf.nn.softmax(fc_8),1),tf.cast(y_,tf.int64))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# 因为不使用字典的方式给变量赋值,所以要定义滑动平均类
variable_averages = tf.train.ExponentialMovingAverage(learning_rate_decay)
saver = tf.train.Saver(variable_averages.variables_to_restore())
with tf.Session()as sess:
tf.global_variables_initializer().run()
tf.train.start_queue_runners(coord=coord)
# get_checkpoint_state()函数会通过chekcpoint文件自动找到目录中最新模型的文件名
# 函数原型get_checkpoint_state(checkpoint_dir,latest_filename)
ckpt = tf.train.get_checkpoint_state("/content/drive/My Drive/使用VGGNet跑Cifar10数据集/cifar10_model_movingaverage_199999/")
saver.restore(sess,ckpt.model_checkpoint_path)
# 通过文件名得到模型保存时迭代的轮数
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
print("The latest ckpt is model.ckpt-%s"%(global_step))
num_batch = int(math.ceil(num_examples_for_eval/batch_size))
accuracy_srore = 0
for i in range(num_batch):
# image_batch,label_batch = sess.run([images_train,labels_train])
image_batch,label_batch = sess.run([images_test,labels_test])
accuracy_srore += sess.run(accuracy,feed_dict={x:image_batch,y_:label_batch})
accuracy_srore = accuracy_srore/num_batch
print("After training %s steps,test accuracy = %g%%"%(global_step,accuracy_srore*100))
打印
![]()
参考书籍:《TensorFlow深度学习算法原理与编程实战》 蒋子阳 著