#python python简单爬虫示例——爬取自己的所有博客,并将所有的博客导出到一个网页
#python python简单爬虫示例——爬取自己的所有博客,并将所有的博客导出到一个网页
学习本文需要先准备的知识点:python基本语法
1.前期准备(知识点讲解)
(1)、urllib.request库——打开url的可扩展库
urllib.request.urlopen(url)
#这个方法用户获取指定的链接网页。url参数,可以是一个string,或者一个Request对象,通常是需要获取的网页的链接。urllib.request.urlopen(url).read()
#读取指定的页面,返回值是一串字符串,是指定页面的html标签组成的字符串
(2)、urllib.parse库——url解析库
urllib.parse.urljoin(pageUrl, newUrl)
#将两个链接拼接起来例如:
>>> from urllib import parse
>>> url1 = "https://blog.csdn.net/weixin_41475710"
>>> url2 = "article/details/82926105"
>>> parse.urljoin(url1,url2)
'https://blog.csdn.net/weixin_41475710/article/details/82926105'
>>> url1 = "https://blog.csdn.net/weixin_41475710/article/details/82926105"
>>> url2 = "article/details/82912220"
>>> parse.urljoin(url1,url2)
'https://blog.csdn.net/weixin_41475710/article/details/82912220'
(3)、BeautifulSoup库——从HTML或XML文件中提取数据
BeautifulSoup对象的创建:
对象名 = BeautifulSoup(含有网页源代码的字符串,"解析方式",from_encoding='解析编码')
解析方式常用lxml、html.parser,lxml未安装的话需要下载;解析编码就是网页的编码方式,通常为utf-8,可以在网页
里的获取网页指定标签的内容:
对象名.标签名获取指定标签的指定属性的内容
对象名.标签名.属性名例如:
#创建对象
soup = BeautifulSoup(htmlCont, 'html.parser', from_encoding='utf-8')
#访问title标签
soup.title
#获取title标签的name属性
soup.title.name从BeautifulSoup对象里面查找所有的符合要求的内容:
对象名.findAll('标签名',class_="class属性名",name="name属性名",…………)标签的所有属性都可以用作上面这个方法的晒选,注意标签的class属性用class_代替,因为python里有class的关键字,不能用关键字作为属性名。
从BeautifulSoup属性里获取第一个符合要求的内容:
对象名.find('标签名',class_="class属性名",name="name属性名",…………)此外,还可以在已经查找到的内容里面继续查找,例如:
links = soup.find('div', class_='article-list').findAll('a', class_='title'))
for link in links:
newUrl = link['href']
newFullUrl = urllib.parse.urljoin(pageUrl, newUrl)
newUrls.add(newFullUrl)如果findAll()和find()没有查找到内容,会报这样的错误:'NoneType' object has no attribute 'getText',程序就会在这里中断,如果需要重复爬取多次可以借助try来抛出错误,例如:
try:
titleNode = soup.find('h1', class_='title-article')
resData = titleNode.getText()
except:
resData = "没有内容"2.思路解析
(1)、爬取思路:
我们的爬虫需要首先能从我们博客的首页获取我们每一篇博客的链接,将其储存起来,然后爬取每一个链接,获取文章标题和内容。
a、从主页获取博客链接:
打开我们的博客主页,在文章列表的最上面右击,选择审查元素,在这附近的代码上下移动,即可找到到文章列表所在的标签:
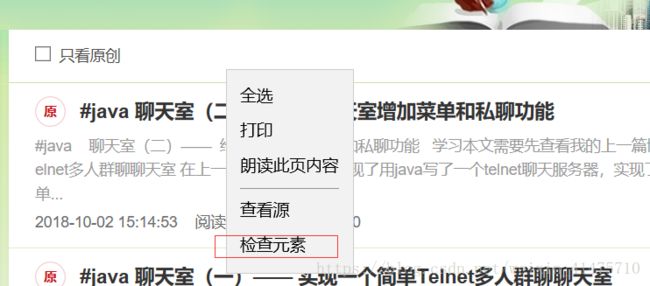
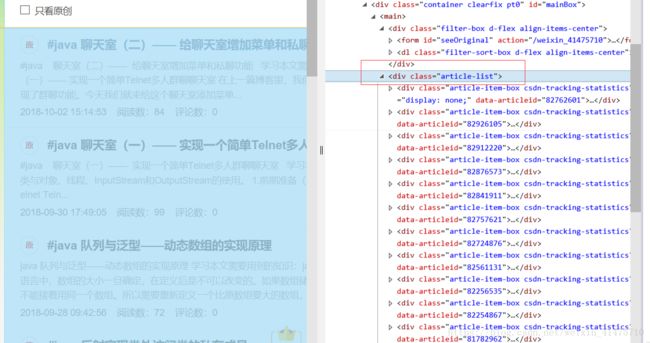
发现文章列表储存在一个class属性为article-list的div标签里面。再往下查找可以发现,文章的链接储存在a标签里面,而且链接为http://blog.csdn.net/weixin_41475710/article/details/ + 一串数字,因此只需要查找所有的href包含weixin_41475710/article/details/ 的a标签,获取他们的href属性的内容就可以获取所有博客文章的链接,将其储存起来。
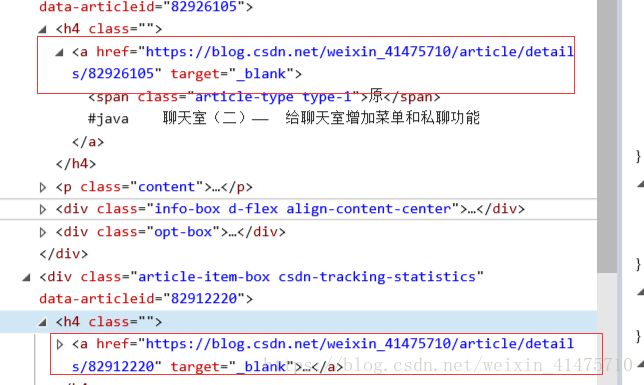
b、爬取博客文章标题和内容:
和上面同样的方式,可以发现标题储存在class为title-article的h1标签里,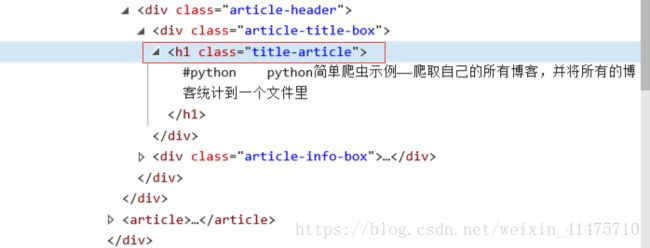
文章内容有的放在class为htmledit_views的div标签里,有的放在class为article_content clearfix csdn-tracking-statistics的div标签里:

只需要获取网页代码后查找class为title-article的h1标签,获取其中的文字即为标题,查找class为htmledit_views或者article_content clearfix csdn-tracking-statistics的div标签,获取其中的文字即为文章内容。
(2)、代码演示
a、先创建一个网页下载器,将指定页面的内容下载下来。
import urllib.request
class HtmlDownloader(object):
@classmethod
#cls表示函数本身,url是传入的网页链接
def download(cls, url):
#如果链接是空的,返回空值
if url is None:
return None
#如果url不为空,获取该网页的页面源代码
response = urllib.request.urlopen(url).read()
return responseb、创建一个网页解析器,解析网页并从中查找指定信息。
import re
import urllib.parse
from bs4 import BeautifulSoup
class HtmlParser(object):
#传入页面的url和页面的源代码,进行解析
def parse(self, pageUrl, htmlCont):
#如果url为空则函数结束
if pageUrl is None or htmlCont is None:
return
#将页面的源代码解析,使用html.parser进行解析,解析编码设置为utf-8
#在读取页面源代码的read()函数里也可以用.decode('utf-8')来指定编码方式,两者只需其一
soup = BeautifulSoup(htmlCont, 'html.parser', from_encoding='utf-8')
#调用下面的方法从网页源代码中查找内容
#查找页面里包含的指定链接并保存
newUrls = self.getNewUrls(pageUrl, soup)
#查找页面里指定的数据并保存
newData = self.getNewData(pageUrl, soup)
return newUrls, newData
#此函数用于查找页面中的指定链接,获取各个博客文章的链接
def getNewUrls(self, pageUrl, soup):
#创建一个set对象
newUrls = set()
try:
#从页面的class为'article-list'的div标签里查找属性href中包含有‘weixin_41475710/article/details/’的a标签,储存进links
links = soup.find('div', class_='article-list').findAll('a', href=re.compile(r"weixin_41475710/article/details/"))
for link in links:
#获取标签的href属性
newUrl = link['href']
#将获取到的链接与原链接拼接
newFullUrl = urllib.parse.urljoin(pageUrl, newUrl)
#将上面获拼接后的链接保存
newUrls.add(newFullUrl)
except:
return None
return newUrls
#此方法用于从获取博客文章标题和内容
def getNewData(self, pageUrl, soup):
resData = {}
resData['url'] = pageUrl
try:
#文章标题储存在class属性为'title-article'的h1标签里面
titleNode = soup.find('h1', class_='title-article')
#获取上面指定标签的文字
resData['title'] = titleNode.getText()
except:
resData['title'] = "没有内容"
#下面的代码用户获取网页的文章内容,并保存
#有些博客文章的正文储存在class为markdown_views prism-atelier-sulphurpool-light的div标签里,有的储存在class为htmledit_views的div标签里
#所以当在class为htmledit_views标签里找不到就要到class为markdown_views prism-atelier-sulphurpool-light的div标签里找
try:
summaryNode = soup.find('div', class_='htmledit_views')
resData['summary'] = summaryNode.getText()
except:
try:
titleNode = soup.find('div', class_='markdown_views prism-atelier-sulphurpool-light')
resData['summary'] = titleNode.getText()
except:
resData['summary'] = "没有内容"
return resDatac、编写一个url管理器,储存并管理url。
class UrlManager(object):
#构造函数里面创建两个set对象,用于储存新的url和已经使用的url
def __init__(self):
self.newUrls = set()
self.outUrls = set()
#向set对象里面添加一个新的链接
def addNewUrl(self, url):
if url is None:
return
if url not in self.newUrls and url not in self.outUrls:
self.newUrls.add(url)
#向set对象里添加许多新链接
def addNewUrls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.addNewUrl(url)
#判断是否还有没有爬取的新链接
def hasNewUrl(self):
return len(self.newUrls) != 0
#返回储存的第一个链接,将其从储存新链接的set里删除,存入储存已经导出的set里面
def getNewUrl(self):
newUrl = self.newUrls.pop()
self.outUrls.add(newUrl)
return newUrl
d、再写一个页面输出的类,将爬取到的信息输出到一个网页里:
class HtmlOutputer(object):
#构造函数里创建一个list
def __init__(self):
self.datas = []
#将爬取到的信息储存到上面定义的list里
def collectData(self, data):
if data is None:
return
self.datas.append(data)
#将list里的数据输出到网页里
def outputHtml(self):
#创建并打开一个网页,编码设置为utf-8,防止乱码
fout = open('output.html', 'w',encoding="utf-8")
#write函数会把函数里的字符串参数写入网页
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write("")
fout.write("%s " % data['url'])
fout.write("%s " % data['title'])
fout.write("%s " % data['summary'])
fout.write(" ")
fout.write('
')
fout.write('')
fout.write('')
e、最后写一个协调的类来将上述所有类实现并应用:
from reptile.blog_Spider import urlManager, htmlDownloader, htmlParser, htmlOutputer
class SpiderMain(object):
#构造函数里面讲所有的类初始化
def __init__(self):
self.urls = urlManager.UrlManager()
self.downloader = htmlDownloader.HtmlDownloader()
self.parser = htmlParser.HtmlParser()
self.outPuter = htmlOutputer.HtmlOutputer()
#爬取信息的主方法
def craw(self, rootUrl):
#count记录爬取次数
count = 1
#讲初始链接写入url管理器
self.urls.addNewUrl(rootUrl)
#如果url管理器里面有新的链接,就继续爬取
while self.urls.hasNewUrl():
try:
#获取url管理器里的第一个链接
newUrl = self.urls.getNewUrl()
#输出爬取的链接
print('craw %d : %s' % (count, newUrl))
#获取该链接的源代码
htmlCont = self.downloader.download(newUrl)
#从源代码里查找符合要求的url和数据
newUrls, newData = self.parser.parse(newUrl, htmlCont)
#将爬取到的url存入url管理器
self.urls.addNewUrls(newUrls)
#将爬取到的数据存入输出网页对象的list里
self.outPuter.collectData(newData)
#当次爬取完毕,count加一
count += 1
except:
#如果出现异常,输出爬取失败
print('craw failed')
#爬取完毕后,将爬取到的数据输出
self.outPuter.outputHtml()
if __name__ == "__main__":
启动程序,创建上述的类的对象,执行爬取的函数
rootUrl = "https://blog.csdn.net/weixin_41475710"
obj_spider = SpiderMain()
obj_spider.craw(rootUrl)