面试总结3 Zuul工作流程、ningix具体过程、 IO流的适配器模式和装饰者模式、用prepredStament为什么能防止sql注入、Spring boot 与spring cloud的区别
总内容
Zuul工作流程?
ningix具体过程
IO流的适配器模式和装饰者模式
为什么用prepredStament为什么能防止sql注入
Spring boot 与spring cloud的区别
接口中只能有抽象方法吗?
大根堆,小根堆解决Top k问题
排序算法的时间复杂度和稳定性和原地排
IO流读写文件以及要是文件不存在会抛出异常
redis数据类型
linux命令抓取8080端口
如果sql查询很慢,怎么造成的
springboot最大的好处
二叉查找树与完全二叉树与满二叉树的区别
hashmap底层实现的数据结构以及用hashmap实现队列(先进先出)-用linkedhashmap
1 Zuul工作流程?
路由顾名思义那是一个帮助我们能够快速寻找到我们需要服务的组件,在springcloud中
路由主要用于和ribbon工作作用,实现负载均衡。其主要作用就是转发和过滤,也是微服务一个不可缺少的部分。
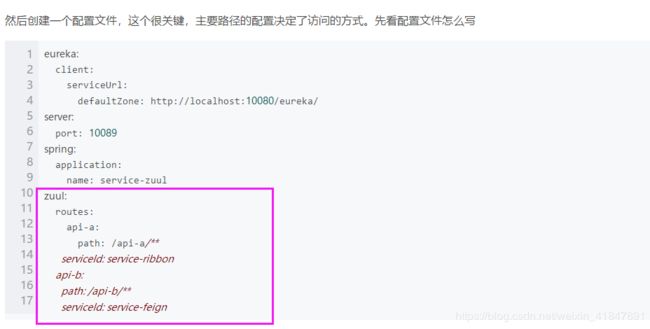
然后在pom文件中引入相关的依赖,具体如下:


2 ningix具体过程

安装完成即可,在/usr/sbin/目录下是nginx命令所在目录,在/etc/nginx/目录下是nginx所有的配置文件,用于配置nginx服务器以及负载均衡等信息


3 IO流的适配器模式和装饰者模式
适配器模式 InputStreamReader适配了InputStream
装饰者模式 BufferedReader(new InputStreamReader(new FileInputStream))
4 为什么用prepredStament为什么能防止sql注入
因为用了PreperStament,就可以把sql语句提前编译,编译带?号的sql语句,
编译好了之后,用数据替换?号,不会再编译sql语句,所以避免了sql注入漏洞5 Spring boot 与spring cloud的区别
Spring boot:
是 Spring 的一套快速配置脚手架,可以基于spring boot 快速开发单个微服务,Spring Boot,看名字就知道是Spring的引导,
就是用于启动Spring的
Spring Cloud:
基于Spring Boot,为微服务体系开发中的架构问题,提供了一整套的解决方案——服务注册与发现,服务消费,服务保护与熔断,网关,
分布式调用追踪,分布式配置管理等。
Spring Cloud是一个基于Spring Boot实现的云应用开发工具;Spring boot专注于快速、方便集成的单个个体,
Spring Cloud是关注全局的服务治理框架;spring boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,
能不配置就不配置,Spring Cloud很大的一部分是基于Spring boot来实现。
学过Spring的都知道,Spring开发有非常头疼的三点:
1. 依赖太多了,而且要注意版本兼容
2. 配置太多了,要配置注解驱动
3.部署和运行麻烦
Spring Boot的哲学就是约定大于配置。既然很多东西都是一样的,为什么还要去配置。
1. 通过starter和依赖管理解决依赖问题。
2. 通过自动配置,解决配置复杂问题。
3. 通过内嵌web容器,由应用启动tomcat,而不是tomcat启动应用,来解决部署运行问题。
Spring Cloud体系就比较复杂了。基本可以理解为通过Spring Boot的三大魔法,将各种组件整合在一起,非常简单易用。
总结一句:
Spring boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring boot,属于依赖的关系。6 接口中只能有抽象方法吗?
Jdk1.7之前只能有抽象方法,jdk1.8就可以有静态方法和默认方法。Jdk1.9可以有私有方法
7 大根堆,小根堆解决Top k问题
大根堆: 根节点value不小于子节点的value,满足这条性质的二叉树即为大根堆。
可以求最大值和top k小的数
小根堆:根节点value不大于子节点的value,满足这条性质的二叉树即为小根堆。
可以求最小值和top k大的数8排序算法的时间复杂度和稳定性和原地排
最好 平均 最坏 稳定性 原地排
冒泡排序: n n^2 n^2 稳定 是
选择排序: n^2 n^2 n^2 不稳定 是
直接插入排序: n n^2 n^2 稳定 是
快速排序: nlogn nlogn n^2 不稳定 是
希尔排序: n nlogn 不稳定 是
归并排序: nlogn nlogn nlogn 稳定 否
堆排序: nlogn nlogn nlogn 不稳定 是9IO流读写文件以及要是文件不存在会抛出异常
try
{FileReader fr = new FileReader("a.txt");}
FileWriter fw = new FileWriter("b.txt");
BufferedReader br=new BufferedReader(fr);
BufferedWriter bw=new BufferedWriter(fw);
String line=null;
while((line=br.readline())!=null){
bw.write(line);
bw.newline();
bw.flush();
}catrch(){};
finally{
bw.close();
br.close();
}
11redis数据类型
键:string
值:string、
list、
hash、
set、
zset。12linux命令抓取8080端口
方法一:
ps -aux | grep 8080
方法二:
netstat –apn | grep 8080 先查出占用8080这个端口号的进程id-pid
ps -ef | grep pid 然后再根据pid查出占用的进程13如果sql查询很慢,怎么造成的
1 可能建的表没有遵循三大范式或者有时候需要建的表遵循反三范式(建表不规范)
2 一条sql语句里面子查询很多
3没有运用存储过程等帮助查询的模块
4没有在常用的字段上建立合适的索引
5或者建立的索引失效(索引失效的方法很多,比如在该字段上用了函数运算,或者is null,is not null
或者该字段用了模糊查询like “%”)
6直接select * 查出所有的字段信息
7没有选择正确的存储引擎
8没有垂直分表14springboot最大的好处
1 使编码简单
2 使配置简单
3 使部署简单
4 使监控简单
以上这些都是spring的不足15二叉查找树与完全二叉树与满二叉树的区别
1 二叉查找树:
左节点<根节点<右节点 左右子树依此递归
2 完全二叉树:
叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部
3 满二叉树:
在一颗二叉树中,所有分支节点都存在左子树和右子树,并且所有叶子结点都在同一层上。
总结:满二叉树肯定是完全二叉树,而完全二叉树不一定是满二叉树16hashmap底层实现的数据结构以及用hashmap实现队列(先进先出)-用linkedhashmap
hashmap底层数据结构就是jdk1.7-数组+链表,jdk1.8-数组+链表+红黑树
用hashmap实现队列功能可以用linkedhashmap