Linux hadoop2.6.5搭建伪分布式
先搭建单机hadoop,可以进入下面网址参考教程:
https://mp.csdn.net/postedit/88530014
1、先进行配置bash_profile
输入命令:vim ~/.bash_profile 进入文件里面配置下图的环境:(加入你的hadoop路径)

并生效环境变量:source ~/.bash_profile
加入jdk:
进入 cd /usr/local/hadoop/etc/hadoop/ 找到
hadoop-env.sh 文件:进入 vim hadoop-env.sh (Hadoop环境变量文件)
:set nu 显示段号找到27行加入jdk路径
找不到路径就


2、接下来配置四个文件(重点!!!绝对不能错)
先来认识一下几个必须认识的目录文件夹:
bin: 存放的是实现管理脚本和使用的脚本的目录;
sbin: 存放的是我们管理脚本的所在目录(例如:启动、停止运行的脚本);
etc:存放一些hadoop的配置文件;
lib:该目录下存放的是Hadoop运行时依赖的jar包,也就是hadoop编译时需要的本地库;
logs:该目录存放的是Hadoop运行的日志;
share:Hadoop各个模块编译后的jar包所在的目录;
hdfs:该文件夹下面是支持hdfs运行的jar包。
下图是总目录:(进入你的安装目录下面的etc目录下面的hadoop)
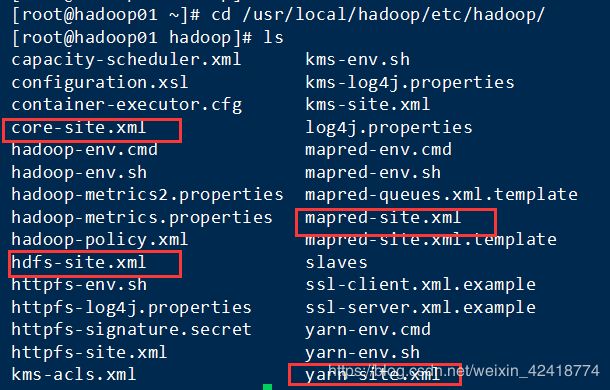
(1)、hdfs-site.xml //HDFS配置文件,该模板的属性继承于core-site.xml
代码如下:
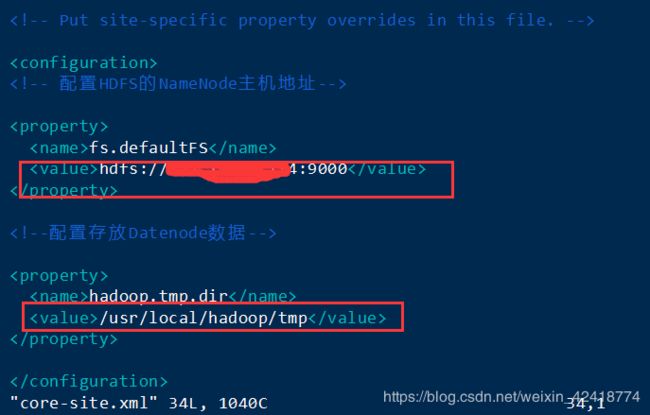
fs.defaultFS
hdfs://内网IP:9000
hadoop.tmp.dir
/root/haitao/hadoop/hp/tmp //在你的hadoop文件下面新建tmp文件夹
查看内网IP : ip addr
把代码加到:
(3)、mapred-site.xml //MapReduce的配置文件,该模板的属性继承于core-site.xml
mapreduce.framework.name
yarn
加入如下图:

(4)、yarn-site.xml
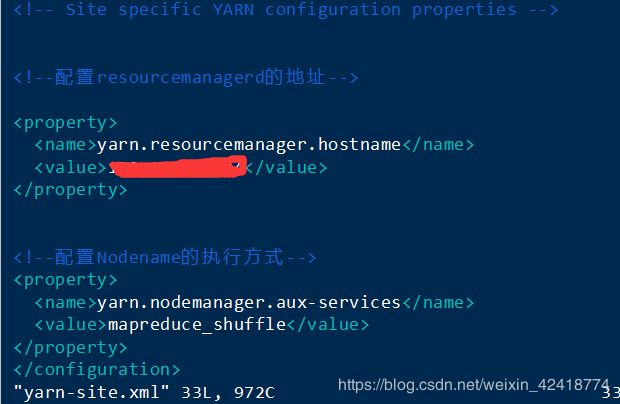
yarn.resourcemanager.hostname
内网ip
yarn.nodemanager.aux-service
mapreduce_shuffle
加入如下图:
记得加入代码后:esc :wq 保存退出!!!!
3、格式化以及启动
进入hadoop目录下面执行格式化:
bin/hdfs namenode -format或者进入bin目录再执行:hdfs namenode -format最后出现下图:

显示Exiting with status 0 就成功了!
接下来就是启动:
下图红框里面的分别是启动(start-all.sh )和关闭(stop-all.sh )

有些版本可能需要使用:sh start-all.sh 来启动!!!
启动成功如下图:

查看进程:jps
结果如下图:

一般到这里就成功了,你就可以去开启的服务器端口了:分别是9000;50070;8088 这三个端口
最后就可以在浏览器进行运行访问:
HDFS:http://你的ip:50070
Yarn:http://你的ip:8088
如下两图结果:
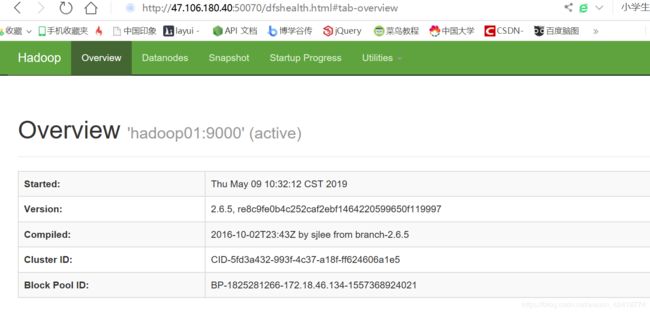
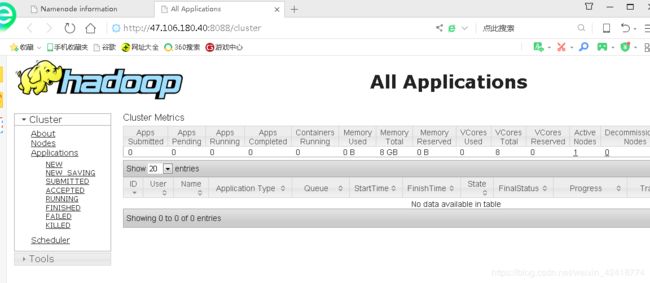
注意注意!!!!
如果过程出错或者是进程少了,一定要去查看logs日志:
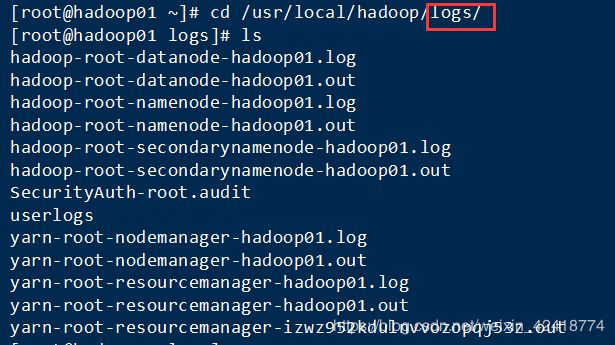
你少了什么,哪里出错了就进那个log里面去看,然后去修改错误,修改前先把hadoop停止运行stop-all.sh !!!
修改后再启动!