使用python进行广告点击率的预测
当前在线广告服务中,广告的点击率(CTR)是评估广告效果的一个非常重要的指标。 因此,点击率预测系统是必不可少的,并广泛用于赞助搜索和实时出价。那么如何计算广告的点击率呢?
广告的点击率 = 广告点击量/广告的展现量
如果一个广告被展现了100次,其中被点击了20次,那么点击率就是20%。
今天我们就来动手开发一个移动广告点击率的预测系统,我们数据来自于kaggle,数据包含了10天的Avazu的广告点击数据。
数据
你可以在这里下载移动广告点击数据,由于总数据量达到了4千多万条,数据量过于庞大,为了不影响我们的计算速度,因此我们要从中随机抽样100万条数据,同时我们要对数据的相关字段类型进行重置,这有助于我们以后的计算以及可视化。
types_train = {
'id': np.dtype(int),
'click': np.dtype(int), #是否点击,1表示被点击,0表示没被点击
'hour': np.dtype(int), #广告被展现的日期+时间
'C1': np.dtype(int), #匿名分类变量
'banner_pos': np.dtype(int), #广告位置
'site_id': np.dtype(str), #站点Id
'site_domain': np.dtype(str), #站点域名
'site_category': np.dtype(str), #站点分类
'app_id': np.dtype(str), # appId
'app_domain': np.dtype(str), # app域名
'app_category': np.dtype(str), # app分类
'device_id': np.dtype(str), #设备Id
'device_ip': np.dtype(str), #设备Ip
'device_model': np.dtype(str), #设备型号
'device_type': np.dtype(int), #设备型号
'device_conn_type': np.dtype(int),
'C14': np.dtype(int), #匿名分类变量
'C15': np.dtype(int), #匿名分类变量
'C16': np.dtype(int), #匿名分类变量
'C17': np.dtype(int), #匿名分类变量
'C18': np.dtype(int), #匿名分类变量
'C19': np.dtype(int), #匿名分类变量
'C20': np.dtype(int), #匿名分类变量
'C21':np.dtype(int) #匿名分类变量
}
n = 40428967 #数据集中的记录总数
sample_size = 1000000
skip_values = sorted(random.sample(range(1,n), n-sample_size))
parse_date = lambda val : pd.datetime.strptime(val, '%y%m%d%H')
with gzip.open('./data/ctr/train.gz') as f:
train = pd.read_csv(f, parse_dates = ['hour'], date_parser = parse_date, dtype=types_train, skiprows = skip_values)
print(len(train))
train.head()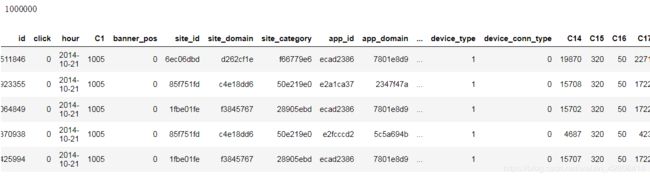
特征工程
接下来我们要做的就是数据的探索性分析(EDA)和特征工程(Feature Engineering),首先我们要确定哪些目标变量,哪些是特征变量,根据kaggle中对数据的描述信息中我们可知,目标变量就是"click"字段它表示广告是否被点击过(1表示被点击,0未被点击),其余所有的字段都是特征变量。在特征变量中C1,C14~C21表示匿名的分类变量(我们不知道它的含义),其余的特征变量都是和站点,app,设备相关的变量。我们搞清了变量的大概含义以后,接下来我们要分析一下目标变量"click",首先看看它的数据分布情况:
print(train['click'].value_counts())
print()
print(train['click'].value_counts()/len(train))
sns.countplot(x='click',data=train, palette='hls')
plt.show()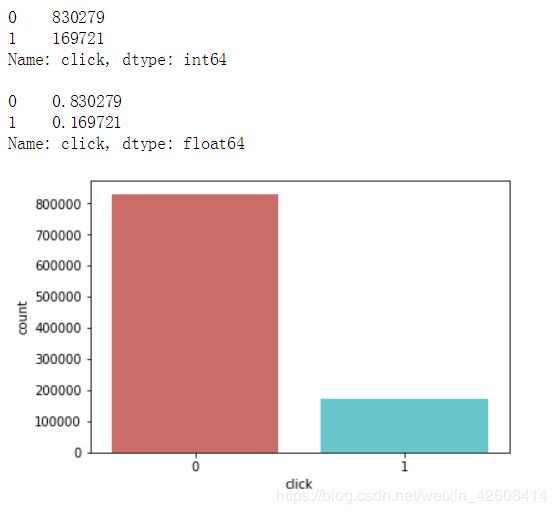
在“click”变量的统计数据中,点击的数量大约占17%,未点击的数量大约占83%。也就是说广告的平均点击率大概是在17%左右。
接下来我们来分析另外一个关键的特征变量:hour,它可能表示广告被展现的日期+时间,我们要看看不同的日期和时间对广告点击量的影响:
print(train.hour.describe())
train.groupby('hour').agg({'click':'sum'}).plot(figsize=(12,6))
plt.ylabel('点击量')
plt.title('时间和点击量')
由上面的统计结果可知数据的开始时间是2014-10-21 00:00:00,结束时间是2014-10-30 23:00:00,一共10天,点击量高峰的时刻是在10月22日和10月28日这两天,10月24日点击量最低。
对Hour的特征工程
我们知道hour变量包含了具体的日期和时间,接下来我们想知道点击量和具体的时间是什么关系,此时我们忽略日期,只关注具体时间和点击量。接下来我们从hour变量中抽取时间,然后查看时间和点击量之间的关系:
train['time'] = train.hour.apply(lambda x: x.hour)
train.sample(5) 
train.groupby('time').agg({'click':'sum'}).plot(figsize=(12,6),grid=True)
plt.ylabel('点击次数')
plt.title('时间和点击量')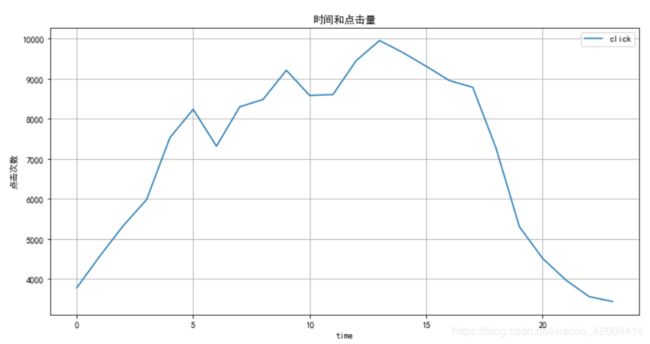
我们看到点击量的高峰大约是在每天下午的13点到14点之间 ,点击量的最低点是在每天的零点左右。这应该是合理的,因为下午1点到2点应该是人们精力最旺盛的时候,而晚上零点大部分人都进入了梦乡。
接下来我们要查看一下在不同的时间点的情况下,广告的展现量和点击量的关系:
train.groupby(['time', 'click']).size().unstack().plot(kind='bar', figsize=(12,6))
plt.ylabel('数量')
plt.title('展现量与点击量');
我们将时间按每个时间点展开,这里没有特别之处下午1点的展现量最大,所以点击量也是最大,我们发现展现量和点击量似乎是成正比的。这似乎也告诉我们,如果您要投放在线广告,请在下午1点至2点之间投放,因为此时广告的展现量和点击量都是最大的。
接下来我们来计算一下各个时间点的广告点击率,并查看点击率的数据分布。
df_click = train[train['click'] == 1]
df_hour = train[['time','click']].groupby(['time']).count().reset_index()
df_hour = df_hour.rename(columns={'click': 'impressions'})
df_hour['clicks'] = df_click[['time','click']].groupby(['time']).count().reset_index()['click']
df_hour['CTR'] = df_hour['clicks']/df_hour['impressions']*100
df_hour.head()
plt.figure(figsize=(12,6))
sns.barplot(y='CTR', x='time', data=df_hour)
plt.title('点击率的时间分布')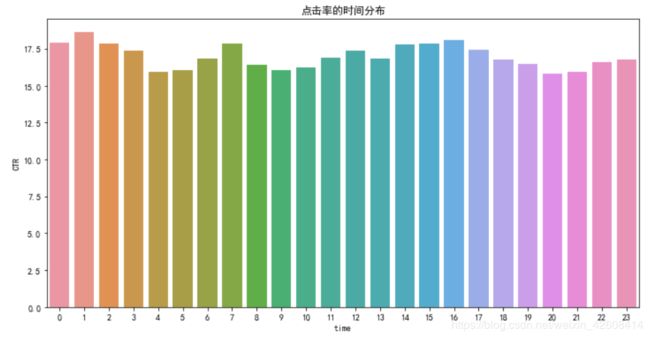
在这里我们发现了一件有趣的事,广告点击率最高的时间点居然在凌晨1点,上午7点,下午16点,而从之前的分析中我知道广告展现量最高的时间点是在下午的13点, 但是从上图中我们可知13点的广告点击率并非是最高的。这似乎说明高的展现量和高的点击量并不意味着就有高的点击率。凌晨1点上网的“夜游神”们才是点击率的真正贡献者。
按星期特征工程
前面我们我们已经分别实现了按日期和按时间两种方式来分析点击率,接下来我们再继续扩展对hour变量的分析,这回我们要按星期来分析点击率。我们首先要把hour变量转换成星期。
train['day_of_week'] = train['hour'].apply(lambda val: val.weekday_name)
cats = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
train.groupby('day_of_week').agg({'click':'sum'}).reindex(cats).plot(figsize=(12,6))
ticks = list(range(0, 7, 1))
labels = "周一 周二 周三 周四 周五 周六 周日".split()
plt.xticks(ticks, labels)
plt.title('星期的点击量')
train.groupby(['day_of_week','click']).size().unstack().reindex(cats).plot(kind='bar', title="Day of the Week", figsize=(12,6))
ticks = list(range(0, 7, 1))
labels = "周一 周二 周三 周四 周五 周六 周日".split()
plt.xticks(ticks, labels)
plt.title('星期的展现量和点击量分布') 
从上图可知星期二的展现量和点击量是最高的,接下来是星期三和星期四,不过展现量和点击量较高并不意味着点击率也较高,因此接下来我们要按星期来计算一下点击率。
df_click = train[train['click'] == 1]
df_dayofweek = train[['day_of_week','click']].groupby(['day_of_week']).count().reset_index()
df_dayofweek = df_dayofweek.rename(columns={'click': 'impressions'})
df_dayofweek['clicks'] = df_click[['day_of_week','click']].groupby(['day_of_week']).count().reset_index()['click']
df_dayofweek['CTR'] = df_dayofweek['clicks']/df_dayofweek['impressions']*100
plt.figure(figsize=(12,6))
sns.barplot(y='CTR', x='day_of_week', data=df_dayofweek, order=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'])
plt.title('星期的点击率')
通过之前的我们知道星期二和星期三有着最高的展现量和点击量,可是他们的点击率却是最低的。相反星期六和星期天却有着最高的点击率。这是否说明星期六和星期天是人民群众最空闲的时候,有了空闲时间大家才会想到去购物,所以广告的点击率才会是最高的?
通过对数据的严谨分析,我们就会从中发现人民群众的日常行为举止以及他们的活动规律都会在数据中得到体现,只要你足够努力,就可以让数据说话!
匿名特征变量C1
C1是一个匿名的分类型变量,我们不知道它的含义,我们先查看一下c1的数据分布
print(train.C1.value_counts()/len(train))
因为C1是分类型变量,它的值包含了1005,1002,1010,1012,1007,1001,1008七种,其中1005的所占比例高达91.87%,接下来我们看看C1的不同的值对点击率的贡献
C1_values = train.C1.unique()
C1_values.sort()
ctr_avg_list=[]
for i in C1_values:
ctr_avg=train.loc[np.where((train.C1 == i))].click.mean()
ctr_avg_list.append(ctr_avg)
print(" C1 value: {}, 点击率: {}".format(i,ctr_avg))
从上面的统计结果可知,虽然1005数据量所占比重最高,但是它的点击率并不是最高,1002的点击率最高达到了21.3%。接下来我们看一下C1的展现量和点击量的分布
train.groupby(['C1', 'click']).size().unstack().plot(kind='bar', figsize=(12,6), title='C1 展现量和点击量分布');
从上图可知,1005的展现量和点击量是最高的,但这并不意味着点击率也是最高的,下面我们看一下C1的点击率的分布
df_c1 = train[['C1','click']].groupby(['C1']).count().reset_index()
df_c1 = df_c1.rename(columns={'click': 'impressions'})
df_c1['clicks'] = df_click[['C1','click']].groupby(['C1']).count().reset_index()['click']
df_c1['CTR'] = df_c1['clicks']/df_c1['impressions']*100
plt.figure(figsize=(12,6))
sns.barplot(y='CTR', x='C1', data=df_c1)
plt.title('C1的点击率分布')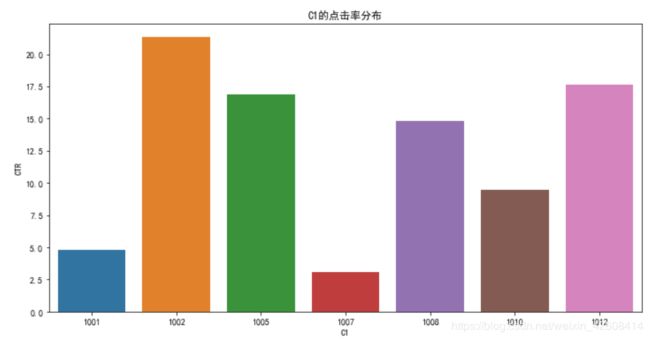
我们看到点击率最高的并不是1005,而是1002. 它的点击率达到了21%,下面我们总结一下C1数据量和点击率的分布:

从上表中我们可以看出,1002的数据比例是5.5%,它贡献的点击率为21.33%远大于17%的平均点击率,1002的数据比例为0.28%却贡献了17.66%的点击率,1008的数据比例是0.01%,它贡献了14.84%的点击率,性价比非常高。
banner_pos
banner_pos表示广告在网页中的位置,广告摆放在网页的不同位置可能会带来不同的点击量和点击量,下面我们就来分析一下banner_pos这个分类型变量。首先我们查看一下banner_pos的数据分布

从上面的统计结果可知banner_pos包含了7个值,它可能代表网页中的7个不同位置,其中位置0和位置1占据了机会99%的数据比例,也就是说绝大多数广告都房子了位置0或者位置1的地方。
下面我们看看不同位置对点击率的贡献:
banner_pos = train.banner_pos.unique()
banner_pos.sort()
ctr_avg_list=[]
for i in banner_pos:
ctr_avg=train.loc[np.where((train.banner_pos == i))].click.mean()
ctr_avg_list.append(ctr_avg)
print(" banner 位置: {}, 点击率: {}".format(i,ctr_avg))
位置0和位置1的点击率分别为16.4%和18.3%,它们的点击率并不是最高。位置7和位置3的点击率分别达到了31%和21%,它们的点击率要比位置1和位置0高很多。
train.groupby(['banner_pos', 'click']).size().unstack().plot(kind='bar', figsize=(12,6), title='banner 位置的广告展现量和点击量的分布')
下面我们再看一下banner_pos的点击率的分布
df_banner = train[['banner_pos','click']].groupby(['banner_pos']).count().reset_index()
df_banner = df_banner.rename(columns={'click': 'impressions'})
df_banner['clicks'] = df_click[['banner_pos','click']].groupby(['banner_pos']).count().reset_index()['click']
df_banner['CTR'] = df_banner['clicks']/df_banner['impressions']*100
sort_banners = df_banner.sort_values(by='CTR',ascending=False)['banner_pos'].tolist()
plt.figure(figsize=(12,6))
sns.barplot(y='CTR', x='banner_pos', data=df_banner, order=sort_banners)
plt.title('banner 位置的点击率的分布')
从上图可知位置7和位置3的点击率是最高的,但是他们的数据比例并不是最多的,相反位置0和位置1的数据比例,展现量和点击量都是最高的,但是他们的点击率并非最高。
device_type
device_type表示设备类型,广告可能会在多种设备上展示,下面我们看一下device_type的数据分布

我们看到一共有4种设备,其中设备1所占比例最大达到了92%, 绝大多数广告都是在设备1上展示的。下面我们看一下展现量和点击量的分布
train[['device_type','click']].groupby(['device_type','click']).size().unstack().plot(kind='bar', title='设备类型')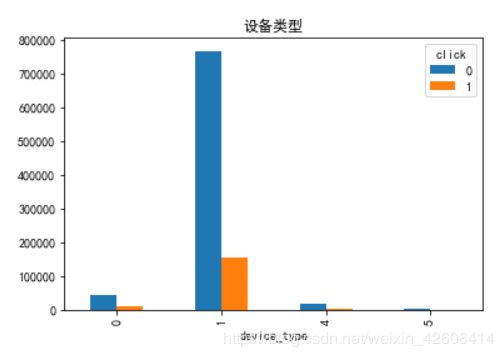
我们看到设备1上的广告展现量和点击量都是最大的。其他设备的展现量和点击量相对较少。为此我们要详细分析一下设备1上的点击量的情况,我们按照不同的时间点对设备1的点击量进行一下分析。
df_click[df_click['device_type']==1].groupby(['time', 'click'])\
.size().unstack()\
.plot(kind='bar', title="设备1的点击量分布", figsize=(12,6))
从上图可知,设备1上的点击量最高点位于下午1点,这和我们之前按时间分析点击量的结果是一致的。
下面我们分别统计出所有类型的设备的点击量、展现量和点击率。
device_type_click = df_click.groupby('device_type').agg({'click':'sum'}).reset_index()
device_type_impression = train.groupby('device_type').agg({'click':'count'}).reset_index().rename(columns={'click': 'impressions'})
merged_device_type = pd.merge(left = device_type_click , right = device_type_impression, how = 'inner', on = 'device_type')
merged_device_type['CTR'] = merged_device_type['click'] / merged_device_type['impressions']*100
merged_device_type 
我们看到点击率最高的设备是设备0,并不是设备1.所以说展现量和点击量都较高并不意味着点击率也会较高。
剩余的特征变量的分析过程和上面的类似,这里就不再一一说明,有兴趣的朋友可以自己尝试分析一下。
建模
has简介
由于我们的的数据样本量有100万条,特征变量有20个左右,那么总共的特征值将会有100万X20=2000万个左右,为了减少系统内存的消耗,我们要使用python的内置hash函数来映射某些特征变量,我们要将那些类型为object的特征变量映射为一定范围内的整数(原来的string被映射成了integer),这样就可以大大降低内存的消耗。
下面我们看看未使用hash之前我们的样本数据:

红框中的特征变量类型均为object, 下面我们要将hash函数将类型为object的变量映射成integer型
def convert_obj_to_int(self):
object_list_columns = self.columns
object_list_dtypes = self.dtypes
new_col_suffix = '_int'
for index in range(0,len(object_list_columns)):
if object_list_dtypes[index] == object :
self[object_list_columns[index]+new_col_suffix] = self[object_list_columns[index]].map( lambda x: hash(x))
self.drop([object_list_columns[index]],inplace=True,axis=1)
return self
train = convert_obj_to_int(train)
train.head()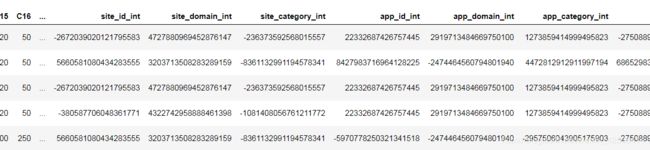
LightGBM 模型
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中,接下来我们要使用LightGBM作为我们的分类模型.
X_train = train.loc[:, train.columns != 'click']
y_target = train.click.values
msk = np.random.rand(len(X_train)) < 0.8
lgb_train = lgb.Dataset(X_train[msk], y_target[msk])
lgb_eval = lgb.Dataset(X_train[~msk], y_target[~msk], reference=lgb_train)
# 配置模型参数
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': { 'binary_logloss'},
'num_leaves': 31, # 每棵树的默认叶子数
'learning_rate': 0.08,
'feature_fraction': 0.7, # 将在训练每棵树之前选择70%的特征
'bagging_fraction': 0.3, #随机选择30%的特征。
'bagging_freq': 5, # 每5次迭代执行bagging
'verbose': 0
}
print('开始训练...')
gbm = lgb.train(params,
lgb_train,
num_boost_round=4000,
valid_sets=lgb_eval,
early_stopping_rounds=500)
XGBoost 模型
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。
def run_default_test(train, test, features, target, random_state=0):
eta = 0.1
max_depth = 5
subsample = 0.8
colsample_bytree = 0.8
params = {
"objective": "binary:logistic",
"booster" : "gbtree",
"eval_metric": "logloss",
"eta": eta,
"max_depth": max_depth,
"subsample": subsample,
"colsample_bytree": colsample_bytree,
"silent": 1,
"seed": random_state
}
num_boost_round = 260
early_stopping_rounds = 20
test_size = 0.2
X_train, X_valid = train_test_split(train, test_size=test_size, random_state=random_state)
y_train = X_train[target]
y_valid = X_valid[target]
dtrain = xgb.DMatrix(X_train[features], y_train)
dvalid = xgb.DMatrix(X_valid[features], y_valid)
watchlist = [(dtrain, 'train'), (dvalid, 'eval')]
gbm = xgb.train(params, dtrain, num_boost_round, evals=watchlist, early_stopping_rounds=early_stopping_rounds, verbose_eval=True)
features = ['C1', 'banner_pos', 'device_type', 'device_conn_type', 'C14',
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'time',
'site_id_int', 'site_domain_int', 'site_category_int', 'app_id_int',
'app_domain_int', 'app_category_int', 'device_id_int', 'device_ip_int',
'device_model_int', 'day_of_week_int']
run_default_test(train, y_target, features, 'click')
完整代码可以在此下载
