HITICS 大作业 by LS
HITICS 深入理解计算机系统大作业
摘要
本文简单介绍了hello从.c文件经历了.i,.s,.o等中间文件形式,被转换成可执行目标文件的过程。又简述了shell如何通过创建子进程运行这个可执行目标文件,一直到这个程序运行结束的过程,可谓是“hello的程序人生”
关键词:程序;预处理;编译;汇编;链接;异常;虚拟内存;Unix IO
第1章 概述
Hello简介
P2P:hello.c经过cpp,ccl,as,ld的处理由一个源代码文件转换成了一个可执行目标文件,shell fork子进程运行这个可执行目标文件
020:子进程通过execve执行这个可执行目标文件,中间经过异常、信号、虚拟内存管理等等步骤,最终运行结束,被父进程回收,抹去存在的痕迹。
1.1环境与工具
XPS 15 9570
VMWARE
UBUNTU
WINDOWS
EDB
NOTEPAD++
VIM
READELF
1.2 中间结果
| 文件 | 功能 |
|---|---|
| hello.i | 预处理后的ASCII码文件 |
| hello.o | 汇编文件 |
| hello.elf | 可重定位目标文件 |
| helloasm.txt | hello.o 反汇编代码 |
| hello | 最终的可执行目标文件 |
| helloasmm.txt | hello 反汇编代码 |
| helloelf_lk.txt | hello的部分elf内容 |
| elfall.txt | hello的全部elf内容 |
1.3 本章小结
这篇论文要开始了,介绍的hello的程序人生。
第2章 预处理
预处理的概念与作用
C语言标准规定,预处理是指前4个编译阶段(phases of translation)。
1.三字符组与双字符组的替换
2.行拼接(Line splicing): 把物理源码行(Physical source line)中的换行符转义字符处理为普通的换行符,从而把源程序处理为逻辑行的顺序集合。
3.单词化(Tokenization): 处理每行的空白、注释等,使每行成为token的顺序集。
4.宏扩展与预处理指令(directive)处理.
2.2 在Ubuntu下预处理的命令
cpp hello.c > hello.i
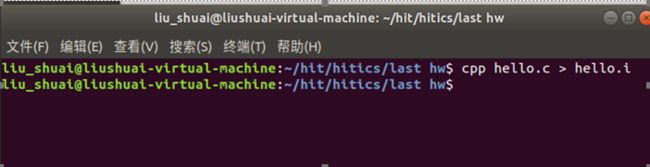
2.3 Hello的预处理结果解析
在这里可以看到.i文件变成了一个3188行的大文件,前面就是各种库的展开。
比如这里
![]()
是stdlib.h,里面有很熟悉的老朋友:

其中还有很多#ifdef,cpp会根据#ifdef后面的值到底有没有定义过来决定是否编译其中的语句。
2.4 本章小结
本章主要介绍了预处理的概念与作用,给出了预处理命令,对hello.c预处理之后的hello.i文件进行解析。
课程当中并没有着重讲过预处理这个环节,仅在链接开头提过,因此限于本人水平问题,不给出详细说明。
第3章 编译
3.1 编译的概念与作用
在整个编译过程中,编译器会完成大部分的工作,将把C语言提供的相对比较抽象的执行模型表示的程序转化成处理器执行的非常基本的指令。
3.2 在Ubuntu下编译的命令
gcc -s hello.i -o hello.s
![]()
3.3 Hello的编译结果解析
3.3.0 伪指令
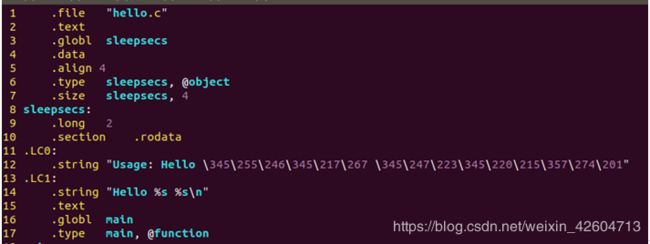
所有以’.’开头的行都是指导汇编器和连接器工作的伪指令。(我们通常可以忽略这些行。)但在这里不能忽略……
其中:
.file声明了源文件的名字
.text声明代码段
.data rodata 声明只读数据段
.globl声明一个全局变量
.type声明变量类型(function or object)
.size声明变量大小
.long 声明一个long类型
.string 声明一个string类型
.align声明对齐大小要求
3.3.1 数据
Hello.s用到的数据类型有整数(int argc, int i, int sleepsecs,immediate), 字符串(“Usage: Hello 学号 姓名!\n”,“Hello %s %s\n”),数组(char *argv[])
3.3.1.1 整数
Hello.c里用到的整数有:int argc, int i, int sleepsecs,其中:
- argc是main传进来的参数,代表的是命令行中的参数个数。
- i是定义的局部变量,存储在栈中

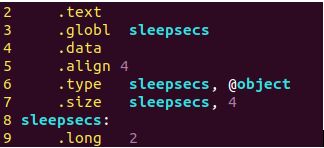
如图所示,因为在一开始定义的时候并未初始化,所以没有立即将i的值压入栈中,在for循环中定义了i从初值为0开始循环,此时将0压入栈中 - sleepsecs是定义的全局变量(int sleepsecs = 2.5)
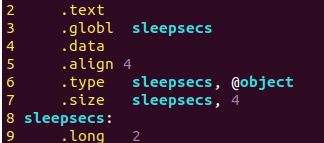
可以看出sleepsecs是一个全局变量,对齐要求是4字节,是一个对象类型的变量,大小是4个字节,定义为一个long类型的变量,值为2,因为linux系统里面int跟long都是4个字节,所以可以互换地使用。
4.Immediates,例如判断是否进入if分支中的立即数3:
3.3.1.2 字符串
Hello.c用到了两个字符串(前面已列出)

都是定义在.rodata节中,表明是只读不可修改,都是用于printf输出的字符串
3.3.1.3 数组
用到的数组是char *argv[],是命令行传进来的参数,argv作为第二个参数传进来,所以存在%rsi中。
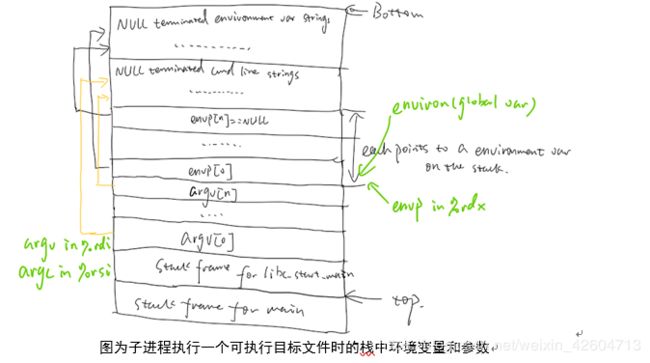
Argv是命令行传入的参数,数组中的每个元素都指向一个字符串,一般来说argv[0]指向的是执行的文件的名字。
![]()
3.3.2 赋值操作&逗号操作
程序中涉及到了’=’赋值操作和逗号操作符
3.3.2.1 赋值操作
程序中的赋值操作用“=”来完成
全局变量sleepsecs的赋值直接在.data段的声明中完成
局部变量i的赋值用汇编指令mov来完成
![]()
3.3.2.2 逗号操作符
逗号操作符是指在C语言中,多个表达式可以用逗号分开,其中用逗号分开的表达式的值分别结算,但整个表达式的值是最后一个表达式的值。在这里面是printf中的分别打印各自指定的值
![]()
3.3.3 类型转换
涉及到的类型转换是int sleepsecs = 2.5,因为是个int(long)类型,所以直接就将小数点之后抹去了,声明的时候也是声明为2.
3.3.4 算术操作
程序中C代码涉及到的算术操作有:++
汇编代码中涉及到的算术操作有:subq,addq,leaq
3.3.4.1 C代码中的算术操作
1.i++,即自增操作,约等价于i= i+1,先引用后自增、
3.3.4.2 汇编代码中的算术操作
1.subq A,B
表示B-A,结果存放在B中,A,B可以是内存位置、立即数、寄存器,但不能同时是内存位置
![]()
2.addq A, B
表示A+B,结果存放在B中,A,B可以是内存位置、立即数、寄存器,但不能同时是内存位置
![]()
3.leaq A,B
本身表示加载有效地址,把A的地址加载到B中,但因为是做加减乘混合运算,有时也可以用于算术运算
3.3.5 关系操作
程序中C代码涉及的关系操作有:!=,<
汇编代码中涉及的关系操作有:cmp
3.3.5.1程序C代码中涉及的关系操作
程序中C代码涉及的关系操作有:!=,<
汇编代码中涉及的关系操作有:cmp
1.!=
![]()
用于判断是否进入分支
2.<
![]()
用于判断是否进入/跳出循环
3.3.5.2程序汇编代码中涉及的关系操作
1.cmp A, B
执行隐含的减法操作,B-A但不保存结果,根据结果设置标志位,修改OF,SF,ZF,CF,AF,PF
![]()
3.3.6 控制转移
程序C代码涉及的控制转移有:if语句,for循环
程序汇编代码中涉及的控制转移有:jmp类
3.3.6.1 程序C代码涉及的控制转移
1.if语句
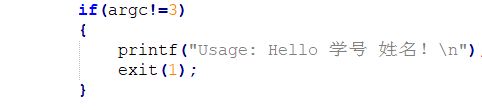
2.for循环

3.3.6.1 程序汇编代码涉及的控制转移
1.je
Cmpl将压入栈中的第二个参数与3作比较,并设置条件码,如果ZF = 1就跳转,否则执行下一条指令
2.jmp
![]()
无条件跳转,跳到.L3标记的位置
3.jle
![]()
Cmpl设置条件码,将9和局部变量i进行比较,如果ZF = 1或OF = 1就进行跳转,否则继续执行下条指令
3.3.7 函数操作
函数操作本质上是一个用户层面的过程调用,涉及到参数传递,函数调用,函数返回
3.3.7.1 参数传递
X86-64在调用函数之前,会将前六个参数传递给寄存器,剩下的参数(若有)压入栈中

如图所示,调用sleep函数之前将需要睡眠的秒数通过寄存器%rdi传递给了函数sleep,因为sleep是动态链接库中的函数,所以需要使用PLT定位,此为链接内容,后话……后话……
3.3.7.2 函数调用
在函数调用之前,会将返回地址(即当前pc值)压入栈中,使得函数调用结束之后能够返回。
3.3.7.3函数返回
在调用函数执行结束之后,若无返回值则直接返回,若有返回值则将返回值放入%rax寄存器之后返回
3.3.7.3 程序中涉及的函数调用
1.main
参数传递:外部调用会将argv和argc分别通过寄存器%rdi和%rsi传入main函数
函数调用:一个新的进程开始执行某一可执行目标文件时会先调用__libc_start_main,是系统启动时调用的函数,call指令会将返回地址压入栈中,然后调用main函数
函数返回:通常来说main函数会返回0
2.printf
参数传递:main函数中将第一条要打印的字符串的地址传入%rdi
![]()
因为只有一个字符串所以使用puts
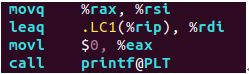
函数调用:因为是动态链接库的函数,需要使用位置无关代码,因此需要GOT和PLT交互在运行时确定函数的地址,所以这里是call puts@PLT/printf@PLT
函数返回:没有返回值
3.exit
参数传递:无
函数调用:因为是动态链接库里的函数,需要使用位置无关代码因此需要GOT和PLT交互在运行时确定函数的地址,所以这里是call exit@PLT
函数返回:不返回,直接退出(这好像是要系统调用)
![]()
4.sleep
参数传递:在调用sleep函数之前先将要睡眠的秒数传入寄存器%edi中
函数调用:call指令会在调用之前把返回地址压入栈中,因为是动态链接库里的函数,需要使用位置无关代码因此需要GOT和PLT交互在运行时确定函数的地址,所以这里是call sleep@PLT
函数返回:如果被信号打断,会返回睡眠剩余的秒数,否则就返回0

5.getchar
参数传递:无
函数调用:call指令会在调用之前把返回地址压入栈中,因为是动态链接库里的函数,需要使用位置无关代码因此需要GOT和PLT交互在运行时确定函数的地址,所以这里是call getchar@PLT
3.4 本章小结
本章介绍了编译的概念及作用,以hello.i生成的hello.s为例介绍了.s文件中的组成部分,并阐述了各个指令的作用
第4章 汇编
4.1 汇编的概念与作用
汇编大多是指汇编语言,汇编程序。把汇编语言翻译成机器语言的过程称为汇编。在汇编语言中,用助记符(Memoni)代替操作码,用地址符号(Symbol)或标号(Label)代替地址码。这样用符号代替机器语言的二进制码,就把机器语言变成了汇编语言。于是汇编语言亦称为符号语言。用汇编语言编写的程序,机器不能直接识别,要由一种程序将汇编语言翻译成机器语言,这种起翻译作用的程序叫汇编程序,汇编程序是系统软件中语言处理的系统软件。
4.2 在Ubuntu下汇编的命令
![]()
Unix>as hello.s -o hello.o
4.3 可重定位目标elf格式
![]()
用这个命令看可执行目标文件hello的内容。
在第七章里面学过一个elf文件是长成这样的:
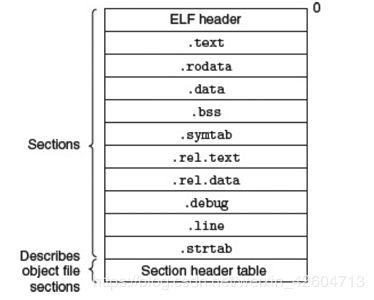
用vim读刚刚生成的文件:
1.ELF头
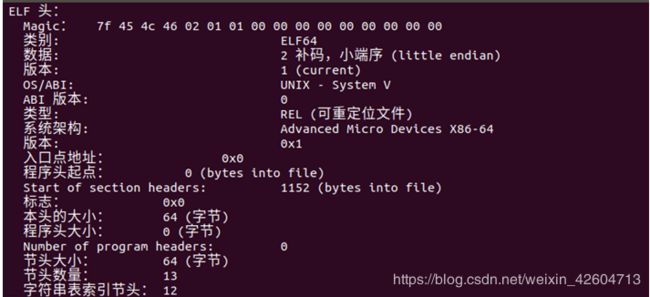
ELF头里面包含了机器的信息,能够让链接器解析这个文件。
第一个Magic就是一个16字节的序列,描述了字的大小和生成了这个文件的系统的字节序列
2.节头部表
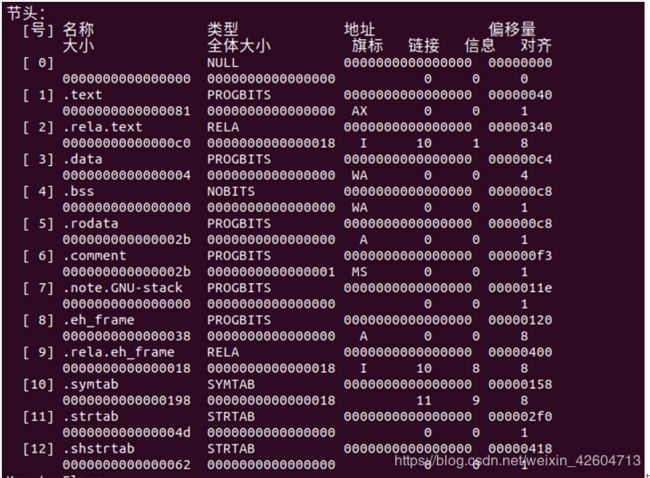
每个节在这个表中都有一个对应的条目,这个表描述了每个节的信息,包括大小、类型、起始地址、偏移量等等
3. .rel.text
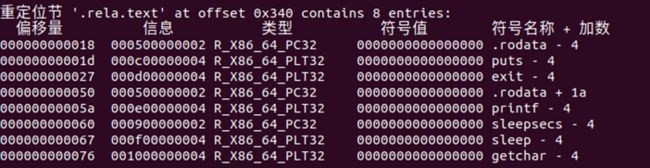
.rel.text节
.rel.text是需要重定位的.text段中的内容。
“A list of locations in the .text section that will need to be modified when the linker combines this object file with others. In general, any instructions that calls an external function or references a global variable will need to be modified.”
CS:APP书上的原话
这里引用了全局变量的指令是sleep(sleepsecs),以及两个printf函数中要打印出的字符串,其他的都是引用了外部函数的指令。
从左到右的每一列分别是偏移量、信息、类型、符号值、符合名称、加数
偏移量就是在每个节中的偏移量的值,不同的类型对应了在重定位过程中不同的算法,带PC的是用相对寻址,不带PC、PLT的用的是绝对寻址,带PLT的用的是PLT在运行的过程中确定动态库中符号的位置,加数是辅助重定位时确定每个符号的位置用的

重定位算法
可以看出其中是要使用addend进行确定位置的计算的
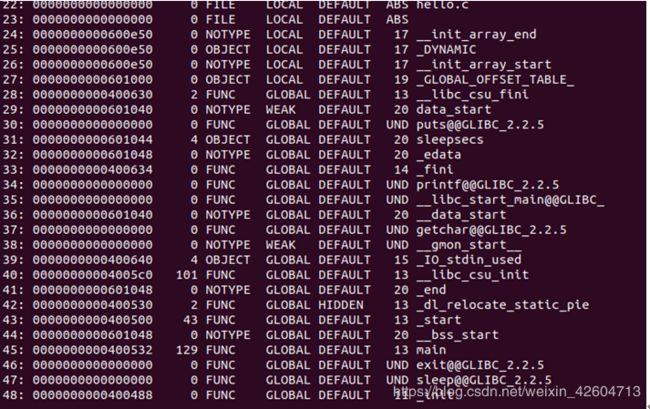
4.符号表
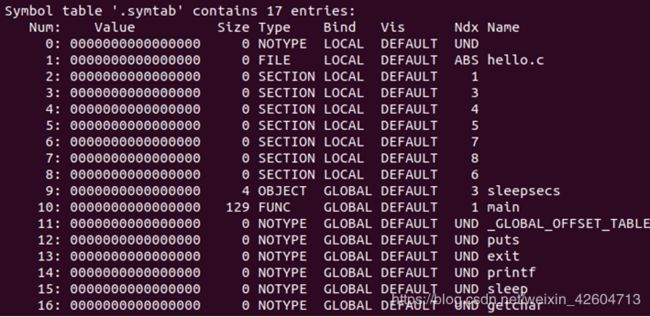
这里举个例子:
比如上图所示的main函数,它是一个大小为129字节(size = 129)的全局(bind = global)变量,类型是函数(type = func),在.text节(ndx = 1)中从偏移量位0(value = 0)的地方开始
4.4 Hello.o的结果解析
![]()
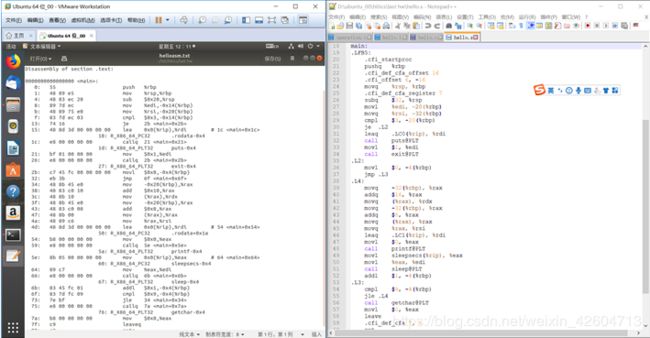
反汇编与.s文件对照
通过对比反汇编和.s文件,能够发现以下的不同:
- 分支转移
在.s文件中,分支转移是依靠.L2这样的标记确定位置的
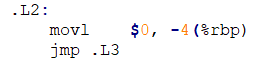
但是在反汇编文件中是通过确定的地址来确定位置的,因为这个时候已经是目标文件了,是可以有具体地址的,链接完之后可以直接映射到虚拟内存空间跑的。

- 调用外部函数和引用全局变量
(1).引用全局变量
在.s文件中,引用全局变量时是简单的用标记的全局变量的位置来给出全局变量的地址的:
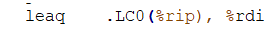
上图是.s文件对字符串"Usage: Hello 学号 姓名!\n"的引用
在反汇编中,引用全局变量是通过根据符号的类型等待链接的时候选择重定位算法来确定全局变量的位置:
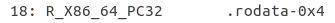
比如上图,就是R_X86_64_PC32类型的,使用的是间接寻址法,在之前有给出这个寻址法的算法
(2).调用外部函数
在.s文件中,引用外部函数就是简单的@PLT,告诉编译器要用PLT进行寻址
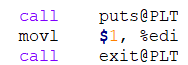
在反汇编中,调用外部函数是通过R_X86_64_PLT32类型使用对应的重定位算法确定位置等待链接的时候确定位置之后进行调用
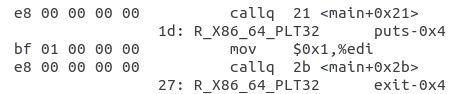
这里有个很有意思的现象,每次call都是下一条指令的地址,这是因为现在还没有进行链接,编译器也不知道这个函数的位置是什么,只能先写在重定位条目中方便链接器进行重定位,确定真正的地址。
4.5 本章小结
本章阐述了hello.s到hello.o的汇编过程,使用readelf工具看到了elf的真面目,利用objdump得到的反汇编比较了.s和反汇编代码的区别,明确了编译器在这一阶段做的事情。
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
第5章 链接
5.1 链接的概念与作用
“Linking consists of static linking and dynamic linking.
Static linkers such as the Linux LD program takes as input a collection of relocatable object files and command-line arguments and generates as output a fully linked executable object file that can be loaded and run. The input relocatable object files consist of various code and data sections, where each section is a contiguous sequence of bytes. Instructions are in one section, initialized global variables are in another section, and uninitialized variables are in yet another section.
To build the executable, the linker must perform two main tasks:
Step 1. Symbol resolution
Step 2.Relocation
Dynamic linking is combined with shared libraries.”
5.2 在Ubuntu下链接的命令
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o
这是一个命令:)

5.3 可执行目标文件hello的格式
1.ELF头:
ELF头里面包含了机器的信息,能够让链接器解析这个文件。
第一个Magic就是一个16字节的序列,描述了字的大小和生成了这个文件的系统的字节序列

2.节头部表
节头部表包含了各个节的基本信息,每个节在这个表中都有一个与之相对应的条目。如图所示,从左到右有每个节的号、名称、类型、地址、偏移量、大小、全体大小、旗标、链接、信息、对齐。

书上的可执行文件ELF的信息
(1) .init节
“The .init section defines a small function, called _init, that will be called by the program’s initialization code”
CS:APP书上原话
起始地址是0x488,大小是0x17字节,对齐要求是4
![]()
(2) .plt节
.plt节就是plt表,每个引用了外部函数的模块都有一个plt表,起始地址是0x4004a0,大小是0x60,对齐要求是16
![]()
(3) .text节
.text节中存放的是代码,起始地址是0x400500,大小是0x132字节,对齐要求是16
![]()
(4) .rodata节
.rodata节中存放的是只读数据 ,比如printf函数中要打印的字符串,起始地址是0x400640,大小是0x2f字节,对其要求是4
![]()
(5) .got节
.got节中存放的是GOT表,用于重定位时确定全局变量的位置
起始位置是0x600ff0,大小是0x10字节,对齐要求是8
![]()
(6) .got.plt节
.got.plt节中存放的是与PLT进行交互的GOT表的内容,用于动态链接时确定外部函数位置,起始地址是0x601000,大小是0x40,对齐要求是8
![]()
(7) .data节
.data节中存放的是各种数据,起始地址是0x601040,大小是0x8,对齐要求是4
![]()
(8) .symtab节
“.symtab is a symbol table with information about functions and global variables that are defined and referenced in the program. However, unlike the symbol table inside a compiler, the .symtab symbol table does not contain entries for local variables “
CS:APP书上原话
起始地址是0,大小为0x498,对齐要求是8
![]()
5.4 hello的虚拟地址空间
(1) .init节
“The .init section defines a small function, called _init, that will be called by the program’s initialization code”
CS:APP书上原话

_init
(2) plt节
.plt节就是plt表,每个引用了外部函数的模块都有一个plt表,起始地址是0x4004a0,大小是0x60,对齐要求是16
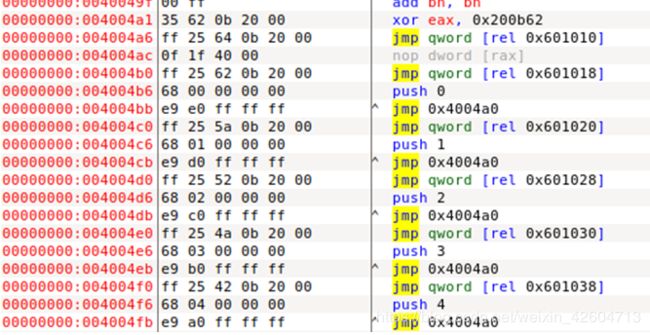
Plt表的内容
这里面就是PLT表中通过与GOT表交互来确定外部函数位置的指令,那些jmp 0x+地址的就是GOT表的地址
(3) text节
.text节中存放的是代码,起始地址是0x400500,大小是0x132字节,对齐要求是16
太多了就不截图了,就是机器码
(4) rodata节
.rodata节中存放的是只读数据 ,比如printf函数中要打印的字符串,起始地址是0x400640,大小是0x2f字节,对其要求是4
![]()
这是那两个printf里面的字符串
(5) got节
.got节中存放的是GOT表,用于重定位时确定全局变量的位置
起始位置是0x600ff0,大小是0x10字节,对齐要求是8
![]()
可以看出got是空的,因为动态链接的时候才会用得到
(6) .got.plt节
.got.plt节中存放的是与PLT进行交互的GOT表的内容,用于动态链接时确定外部函数位置,起始地址是0x601000,大小是0x40,对齐要求是8

比如这里高亮出来的地方就是PLT表中的指令,每个GOT表初始内容都是其对应的PLT表的第二条指令的地址
这是把对应函数的ID给压到栈里了
(7) .data节
.data节中存放的是各种数据,起始地址是0x601040,大小是0x8,对齐要求是4
![]()
这个2应该就是sleepsecs 的大小
(8) .symtab节
“.symtab is a symbol table with information about functions and global variables that are defined and referenced in the program. However, unlike the symbol table inside a compiler, the .symtab symbol table does not contain entries for local variables “
CS:APP书上原话
起始地址是0,大小为0x498,对齐要求是8
这个起始地址是0我也是醉了,问了大佬也不知道为什么,没有办法我只能readelf看符号表的内容了
5.5 链接的重定位过程分析
从hello的反汇编文件中可以看出多了东西,不再只有main一个函数,首先来看main这个函数:
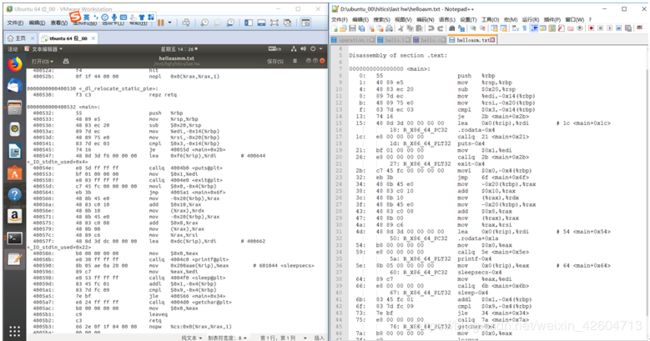
Hello.o与hello反汇编文件对比
- 分支转移
在经过重定位之后,每个函数都有一个确定的运行时地址,因此分支转移上面直接写的就是运行时应该跳转的地址

- 调用外部函数和引用全局变量
(1) 引用全局变量
Hello中全局变量是通过.text和.data段之间的距离不变,用R_X86_64_PC32间接寻址算法确定他的位置的
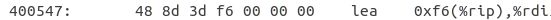
(2) 调用外部函数
这里以一个例子说明调用方式:

这条指令首先跳转到printf函数所对应的PLT表中:

PLT表的第一条指令是跳到这个PLT表所对应的GOT表中去,在刚刚我们已经看到了,GOT表对应条目的初始值是PLT表的第二条指令的地址,回到PLT表中第二条指令,pushq 0x1,就是把printf对应的ID压到栈里去,随后跳转到.plt中,也就是plt表的第一个条目。PLT表的第一个条目是将GOT[1]压进栈中,GOT[1]是重定位条目的地址,然后跳转到GOT[2]中去,GOT[2]就是动态链接器dynamic linker的入口。
动态链接器根据刚刚压入栈中的两个参数:函数ID和重定位条目地址就可以确定printf的地址再写回到printf函数对应的GOT表的条目中去,之后就可以直接通过PLT跳转到GOT表中找到printf的地址,从而实现调用。
接下来看一下函数,已经不只有main函数了,还有一些链接器插进来链接时进行辅助用的:
<_init>:系统启动用的函数
__libc_start_main
<_start>:调用main
__libc_csu_init
__libc_csu_fini
<.plt>:plt表
puts@plt:puts对应的plt表条目
printf@plt:printf对应的plt表条目
getchar@pltgetchar对应的plt表条目
exit@pltexit对应的plt表条目
sleep@pltsleep对应的plt表条目
<_fini>
5.6 hello的执行流程
有的图懒得截了……
1.调用start函数,地址是0x400500
2.调用__libc_start_main函数,地址是 0x400532
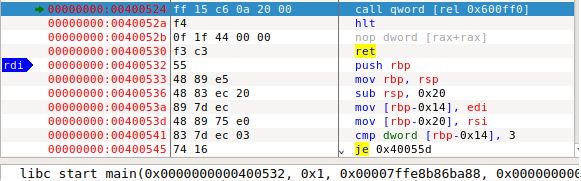
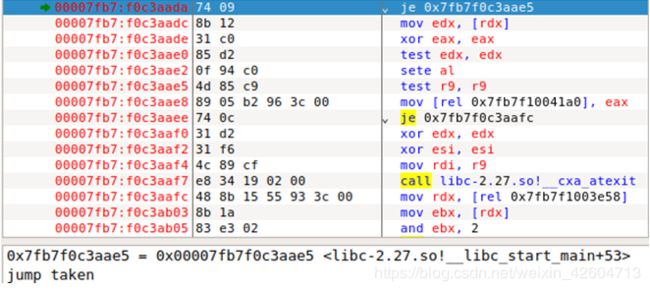
- 调用libc-2.27.so!__cxa_atexit 0x7fce 8c889430

4. 调用libc-2.27.so!__new_exitfn
5. 调用__libc_csu_init
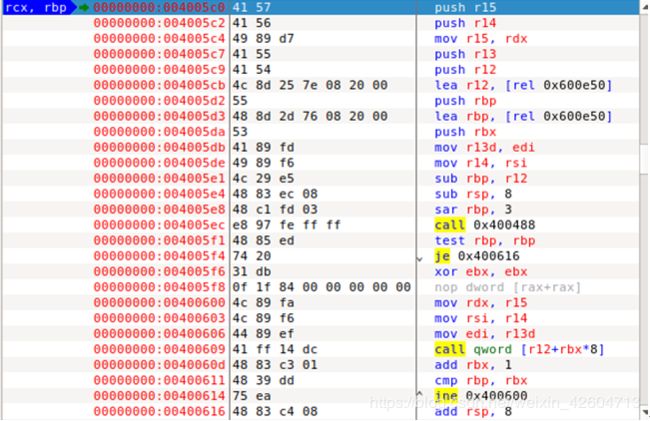
6. 调用__libc_csu_init 0x4005c0
7. 调用_init函数 0x400488
![]()
8. 调用libc-2.27.so!_setjmp函数 0x7fce 8c884c10
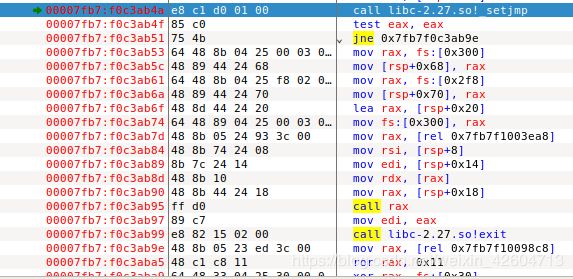
9. 调用-libc-2.27.so!_sigsetjmp函数 0x7fce 8c884b70
10. 调用–libc-2.27.so!__sigjmp_save函数 0x7fce 8c884bd0
11. 调用main 0x400532
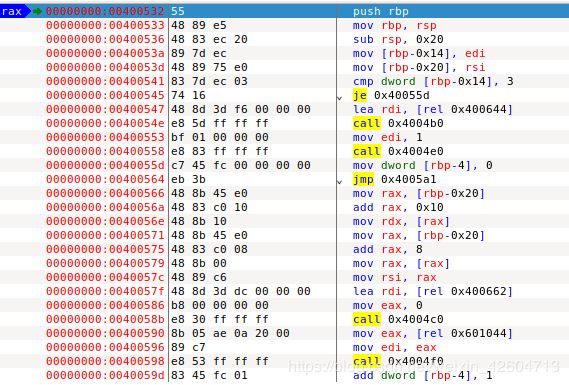
12. 调用puts 0x4004b0

13. 调用exit 0x4004e0
14. 调用ld-2.27.so!_dl_runtime_resolve_xsave 0x7fce 8cc4e680
15. 调用ld-2.27.so!_dl_fixup 0x7fce 8cc46df0
![]()
16. 调用–ld-2.27.so!_dl_lookup_symbol_x 0x7fce 8cc420b0
17. 调用libc-2.27.so!exit 0x7fce 8c889128
5.7 Hello的动态链接分析
这个过程就是我之前所说的那个过程,使用lazy binding的方式,利用GOT表和PLT表之间的交互实现函数的动态链接
调用之前的got.plt长这样

之前已经给出过这个GOT里面初始存的是对应PLT表的第二条指令
![]()
上图是开始调用puts这个函数(0x4004b0)的状态
![]()
上图是puts的第一条指令,跳转到对应的GOT表中
![]()
上图是GOT表中的内容,初始值为PLT表的第二条指令,看一下puts这个函数的第二条指令的地址,的确是这样的
Puts对应的PLT条目的第二条指令是push0,也就是puts函数的ID
第三条指令是跳转到PLT表的第一个条目中去,里面是将GOT[1]压入栈中,GOT[1]存放的内容前面已经讲过,是重定位条目:
![]()
![]()
上图是GOT[1]存放的是重定位条目的地址,是0x007f3522cb9170
![]()
接着跳转到GOT[2]去,GOT[2]里存的是动态链接器的地址:
![]()
最后动态链接器根据以上压入栈中的两个参数成功的找到了puts的地址,并写入了puts对应的GOT表!!!!
![]()
5.8 本章小结
本章主要介绍了链接的概念与作用、hello的ELF的真面目,分析了hello的虚拟地址空间、重定位过程、动态链接过程、执行过程,不禁感叹,系统设计的真的是很巧妙啊!尤其是动态链接过程中的GOT、PLT,佩服,佩服!
第6章 hello进程管理
“A process is an instance of a program in execution. Each program in the system runs in the context of some process. The process provides to the application the following two key abstractions:
An independent logical control flow that provides the illusion that our program has exclusive use of the processor.
A private address space that provide the illusion that our program has exclusive use of the memory system.”
——CS:APP
6.2 简述壳Shell-bash的作用与处理流程
“A shell is an interactive application-level program that runs other programs on behalf of the user. A shell performs a sequence of read/evaluate steps and then terminates. The read step reads a command line from the user. The evaluate step parses the command line and runs programs on behalf of the user.”
——CS:APP
6.3 Hello的fork进程创建过程
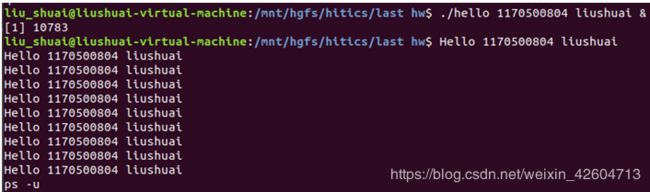
在终端中输入./hello 1170500804 liushuai回车,终端就会读入这个命令,接着进行解析,发现不是内置命令,于是之后终端判断./hello是一个执行一个可执行文件的命令,于是就fork出一个子进程来执行这个文件
“Each program in the system runs in the context of some process. The process consists of the state that the program needs to tun correctly. This state includes the program’s conde and data stored in memory, its stack, the contents of its general purpose registers, its program counter, environment variables, and the set of open file descriptors.”
——CS:APP
从中可以看出子进程继承了父进程的上下文,包括栈、通用寄存器、程序计数器,环境变量和打开的文件
“The child gets an identical(but separate)copy of the parent’s user-level virtual address space, including the code and data segments, heap, shared libraries and user stack, The child also gets identical copies of any of the parent’s open file descriptors, which means the child can read and write any files that were open in the parent when it called fork. The most significant difference between the parent and the newly created child is that they have different PIDs”
——CS:APP
Fork出来的子进程有着跟父进程不一样的PID,但其他都一样,父进程有什么,子进程就有什么,但二者是独立的,意味着二者是并发运行的,当子进程运行结束时,父进程如果还在,就回收子进程,否则就由init进程回收子进程
![]()
父进程bash,子进程./hello 1170500804 liushuai
进程结束之后,由bash来回收子进程。
6.4 Hello的execve过程
“The execve function loads and runs a new program in the context of the current process. The execve function loads and runs the executable object file filename with the argument list argv and the environment variable list envp”
“After execve loads , it calls the start-up code. The start-up code sets up the stack and passes control to the main routine of the new program, which has a prototype of the form or equivalently.”
——CS:APP
“Loading and running a.out requires the following steps:
- Delete existing user areas
- Map private areas
- Map shared areas
- Set the program counter”
——CS:APP
在execve先将hello加载进来,并加载进来由命令行输入的参数列表和参数个数以及环境变量。加载的时候先将原来的用户层面的区域删去,即kernel以下部分,然后将私有的区域映射进来,例如打开的文件,代码、数据段,然后将公共的区域映射进来,例如动态链接库中的printf函数、exit函数等,最后将pc指向代码的入口,即系统启动函数,然后系统启动函数设置栈并把控制传送给main函数,这样就在子进程中加载完成了。
6.5 Hello的进程执行
“The general phenomenon of multiple flows executing concurrently is known as concurrency. The notion of a process taking turns with other processes is also known as multitasking. Each time period that a process executes a portion of its flow is called a time slice. Thus, multitasking is also referred as time slicing.”
“At certain points during the execution of a process, the kernel can decide to preempt the current process and restart a previously preempted process. This decision is known as scheduling and is handled by code in the kernel, called the scheduler. When the kernel selects a new process to run, we say that the kernel has scheduled the process. After the kernel has scheduled a new process to run, it preempts the current process and transfers control to the new process using a mechanism called a context switch.”
“A context switch can occur while the kernel is executing a system call on behalf of the user. If the system call blocks because it is waiting for some event to occur, then the kernel can put the current process to sleep and switch to another process.”
“Another example is the sleep system call, which is an explicit request to put the calling process to sleep.”
这里的情况是主动调用sleep函数,在调用sleep函数之前,如果没有别的原因使得scheduler将hello挂起的话,sleep函数会显式地请求kernel将hello挂起,此时进入内核模式切换到其他进程,切换回用户模式运行那个进程,直到2.5秒之后,收到了sleep结束的信号,又会切换到内核模式,回到hello,输出我的学号和姓名,接着又执行了sleep函数。每次从sleep到sleep都是这个控制流的一部分,即时间片。之后的sleep们都是这样处理,直到程序结束完毕,进程结束被回收。
——CS:APP
6.6 hello的异常与信号处理
产生的异常:page fault, interrupt(keyboard),traps(system calls)
产生的信号:SIGSTP,SIGCONT,SIGKILL

键盘上输入Ctrl Z之后,是来自键盘的interrupt,并且发送一个SIGSTP的信号,SIGSTP的默认行为是在屏幕上打印进程名字,然后停止(挂起)前台作业

键入ps命令,因为之前那个进程已经挂起,前台没有正在运行的工作,可以继续在命令行中输入命令。这是一个来自键盘上的命令,是一个内置命令所以shell立即执行,在这里可以看出进程停止了,但没有终止。
![]()
键入jobs命令之后,之后发生的事情同上可以看出前台作业./hello 1170500804 liushuai已经停止。
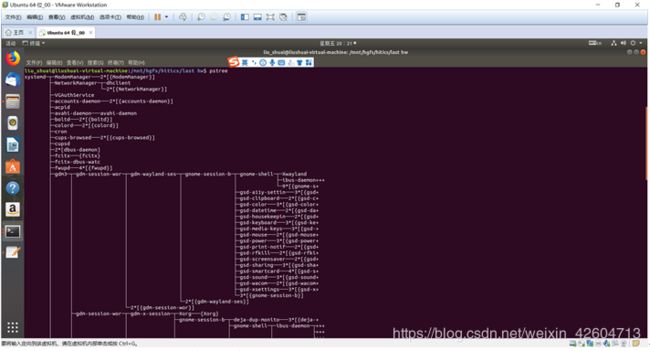
键入pstree命令,同上,因为没有正在工作的前台作业,所以可以向命令行中输入命令,解析出这是一个内置命令后马上给出了回应。

输入fg命令将其调回前台,然后我又让他停止了。(支配的感觉真好)
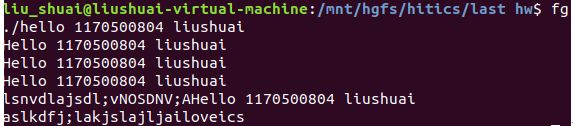
最后是乱按(注意右下角)
6.7本章小结
本章正式进入hello出生后的部分了!!简述了进程、shell的概念与作用,并描述了fork和execve的过程,最后给出了执行hello时遇到的异常和信号的处理方式。
第7章 hello的存储管理
7.1 hello的存储器地址空间
“The main memory of a computer system is organized as an array of M contiguous byte-size cells. Each byte has a unique physical address (PA).”
——CS:APP
Hello存放在物理磁盘中,此时使用的是物理地址
“With virtual addressing, the CPU accesses main memory by generating a virtual address, which s converted to the appropriate physical address before being sent to main memory.”
——CS:APP
在之前链接的时候,各种函数的地址,比如main函数的地址是0x400532,实际上是虚拟地址,这是将物理地址映射成了虚拟地址,方便加载与链接。
逻辑地址:逻辑地址(LogicalAddress)是指由程序产生的与段相关的偏移地址部分。就是hello.o里面的相对偏移地址。
“An address space is an ordered set of nonnegative integer addresses. If the integers in the address space are consecutive, then we say that it is a linear address space.”
——CS:APP
这里线性地址就是之前hello中的虚拟内存地址,很明显那是线性的。
7.2 Intel逻辑地址到线性地址的变换-段式管理
7.2.1 原理
为了进行段式管理,每道程序在系统中都有一个段(映象)表来存放该道程序各段装入主存的状况信息。段表中的每一项(对应表中的每一行)描述该道程序一个段的基本状况,由若干个字段提供。段名字段用于存放段的名称,段名一般是有其逻辑意义的,也可以转换成用段号指明。由于段号从0开始顺序编号,正好与段表中的行号对应,如2段必是段表中的第3行,这样,段表中就可不设段号(名)字段。装入位字段用来指示该段是否已经调入主存,“1”表示已装入,“0”表示未装入。在程序的执行过程中,各段的装入位随该段是否活跃而动态变化。当装入位为“1”时,地址字段用于表示该段装入主存中起始(绝对)地址,当装入位为“0”时,则无效(有时机器用它表示该段在辅存中的起始地址)。段长字段指明该段的大小,一般以字数或字节数为单位,取决于所用的编址方式。段长字段是用来判断所访问的地址是否越出段界的界限保护检查用的。访问方式字段用来标记该段允许的访问方式,如只读、可写、只能执行等,以提供段的访问方式保护。除此之外,段表中还可以根据需要设置其它的字段。段表本身也是一个段,一般常驻在主存中,也可以存在辅存中,需要时再调入主存。假设系统在主存中最多可同时有N道程序,可设N个段表基址寄存器。对应于每道程序,由基号(程序号)指明使用哪个段表基址寄存器。段表基址寄存器中的段表基址字段指向该道程序的段表在主存中的起始地址。段表长度字段指明该道程序所用段表的行数,即程序的段数。
7.2.2 管理
为了进行段式管理,除了系统需要为每道程序分别设置段映象表外,还得由操作系统为整个主存系统建立一个实主存管理表,它包括占用区域表和可用区域表两部分。占用区域表的每一项(行)用来指明主存中哪些区域已被占用,被哪道程序的哪个段占用以及该段在主存的起点和长度。此外,还可以设置诸如该段是否进入主存后被改写过的字段,以便该段由主存中释放时,决定是否还要将其写回到辅存中原先的位置来减少辅助操作。可用区域表的每一项(行)则指明每一个未被占用的基地址和区域大小。当一个段从辅存装入主存时,操作系统就在占用区域表中增加一项,并修改可用区域表。而当一个段从主存中退出时,就将其在占用区域表的项(行)移入可用区域表中,并进行有关它是否可与其它可用区归并的处理,修改可用区域表。当某道程序全部执行结束或者是被优先级更高的程序所取代时,也应将该道程序的全部段的项从占用区域表移入可用区域表并作相应的处理。
7.3 Hello的线性地址到物理地址的变换-页式管理
“Conceptually, a virtual memory is organized as an array of N contiguous byte-size cells stored on disk. Each byte has a unique virtual address that serves as an index into the array. The contents of the array on disk are cached in main memory. As with any other cache in the memory hierarchy, the data on disk is partitioned into blocks that serve as the transfer units between the disk and the main memory. VM systems handle this by partitioning the virtual memory into fixed size blocks called virtual pages. Each virtual page is P = 2^p bytes in size. Similarly, physical memory is partitioned into physical pages, also P bytes in size.”
——CS:APP
通过虚拟内存的页式管理,可以做到如下的事情:
- 方便链接
每个进程正是因为虚拟内存的页式管理可以拥有相同的虚拟内存映像而不用去管具体在物理内存中存在哪个地方的事情。这些都交给MMU进行address translation - 方便加载
在一个新的子进程加载进一个可执行文件时,将这个文件的所有东西都复制进自己的虚拟地址空间,而是通过将虚拟页映射到某一块物理内存中。第一次执行存放在某一块区域中的命令来触发缺页中断,这时虚拟页会自动滑入。 - 方便共享
当两个进程想要共享代码段、数据段的时候,比如共享库,就没有必要在每个进程中都复制一份,这是非常浪费内存空间的,可以将本进程的一个虚拟页映射到物理内存,这样持有一份副本就可以为多个进程所用。 - 方便内存分配
每个进程都有自己独有的代码、数据、堆、栈,如果是通过物理地址进行分配的话,那么必须就把它们分配到连续的物理内存当中,这是具有一定难度的事情,但是通过虚拟页式管理可以将连续的虚拟页映射到不连续的物理页,这样就降低了分配的难度
7.4 TLB与四级页表支持下的VA到PA的变换
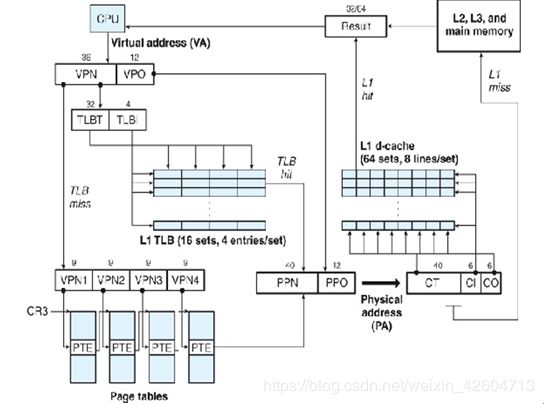
首先虚拟地址是由VPN和VPO组成的,VPN可以作为在TLB中的索引,如上图所示,TLB可以看作是一个PTE的cache,将常用的PTE缓存到TLB中,加速虚拟地址的翻译。TLB是具有高相连度的,应该是为了一次多存一些PTE。如果能够在TLB中找到与VPN对应的PTE,即为TLB hit,TLB直接给出PPN,然后PPO即为VPO,这样就构成了一个物理地址。
如果不能做到TLB hit就要到四级页表当中取寻址,在i7中VPN有36位,被分成了四段,从左往右的前三个九位的地址分别对应于在前三级页表当中的偏移,偏移在页表中所对应的页表条目指向某一个下一级页表,而下一个9位VPN就对应的是在这个页表中的偏移。最后一级页表中的页表条目存放的是PPN
比如VPN1在第一级页表中对应于一个页表条目,这个页表条目指向下一级页表中的某个页表,再依靠VPN2在这个页表中找到它对应的页表条目,同样,这个也表条目指向的是第三级页表中的某个页表,再依靠VPN3找到在这个页表中与之对应的页表条目,这个页表条目指向的是第四级页表中的某个页表,再依靠VPN4找出与之对应的页表条目,这个页表条目中存放的是PPN,在四级页表中最多可以存放512G的内存内容,显然一般是用不了那么多的。
最后再把VPO拿来当成PPO就能找到在对应的物理页上存放的内容了。
7.5 三级Cache支持下的物理内存访问
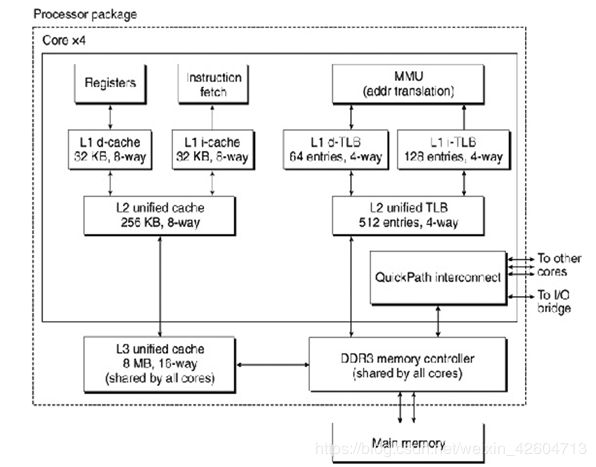
以L1为例,在之前的TLB和四级页表中已经获得了物理地址,使用CI进行组索引,因为一个块大小是64字节,所以CO有6位,即从倒数第6位到倒数第8位是组索引,如果对应的组中tag值相等并且valid值是1,那么就索引成功,不然就需要到下一级高速缓存中去取对应地址的块
7.6 hello进程fork时的内存映射
之前已经有提到过了,这里就简单的引用CS:APP的原文了(都是手敲的!不是复制的!!!)
“When the fork function is called by the current process, the kernel creates various data structures for the new process and assigns it a unique PID. To create the virtual memory for the new process, it creates exact copies of the current process’s mm_struct, area structs and page tables. It flags each page in both processes as read-only, and flags each area struct in both processes as private copy-on-write.
When the fork returns in the new process, the new process now has an exact copy of the virtual memory as it existed when the fork was called. When either of the processes performs any subsequent writes, the copy-on-write mechanism creates new pages, thus preserving the abstraction of a private address space for each process”
——CS:APP
7.7 hello进程execve时的内存映射
“The execve function loads and runs a new program in the context of the current process. The execve function loads and runs the executable object file filename with the argument list argv and the environment variable list envp”
“After execve loads , it calls the start-up code. The start-up code sets up the stack and passes control to the main routine of the new program, which has a prototype of the form or equivalently.”
——CS:APP
“Loading and running a.out requires the following steps:
- Delete existing user areas
- Map private areas.
- Map shared areas
- Set the program counter”
——CS:APP
7.8 缺页故障与缺页中断处理
分三步走:
第一步先确认是不是一个合法的地址,即通过不断将这个地址与每个区域的vm_start&vm_end进行比对,如果并不是在一个区域里的话,就给出segmentation fault,因为它引用了一个不合法的地址
第二步确认访问权限是不是正确的。即如果这一页是只读页,但是却要做出写这个动作,那明显是不行的。如果做出了这类动作,那么处理程序就会触发一个保护异常,默认行为是结束这个进程
第三部确认了是合法地址并且是符合权限的访问,那么就用某个特定算法选出一个牺牲页,如果该页被修改了,就将此页滑出(swap out)并且swap in那个被访问的页,并将控制传递到触发缺页中断的那条指令,这条指令继续执行的时候就不会触发缺页中断,这样就可以继续顺畅地执行下去啦。
7.9动态存储分配管理
“A dynamic memory allocator maintains an area of a process’s virtual memory known as the heap. Details vary from system to system, but without loss of generality, we will assume that the heap is an area of demand-zero memory that begins immediately after the uninitialized data area and grows upward. For each process, the kernel maintains a variable brk that points to the top of the heap.
An allocator maintains the heap as a collection of various-size blocks. Each block is a contiguous chunk of virtual memory that is either allocated or free. An allocated block has been explicitly reserved for use by the application. A free block is available to be allocated. Afree block remains free until it is explicitly allocated by the application. An allocated block remains allocated until it is freed, either explicitly by the application or implicitly by the memory allocator itself.
Allocators come in two basic styles. Both styles require the application to explicitly allocate blocks. They differ about which entity is responsible for freeing allocated blocks:
Explicit allocators require the application to explicitly free any allocated blocks.
Implicit allocators, on the other hand, require the allocator to detect when an allocated block is no longer being used by the program and then free the block.”
——CS:APP
Implicit free lists:
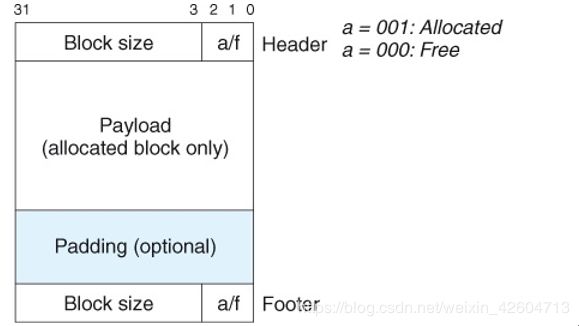
隐式空闲链表在每个空闲块中给出了四个字节的header,因为地址一定是8字节对齐的,所以最后三位肯定是空的,所以最后三位中的1位可以用来存放这个块是否分配(0/1)的信息。还可以加入一个footer,在合并时可以用来确定前一个块是不是空的,因此最小块大小是8个字节,而将空闲链表分配出去时可以不用加入footer,只需在header的空闲3位中再选1位用来作为前一块是否是空闲的标记(0/1)就可以了。
隐式链表的好处在于它简单,易于操作,但是它的坏处在于搜索时间实在是太长了,如果采用first-fit的话内存利用率会低,但如果采用best-fit的话需要对于一整个堆进行搜索。
Explicit free lists:
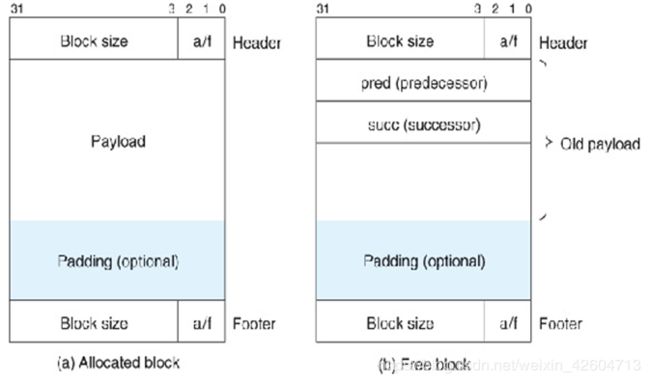
对于分配的块,只需要一个header和一个footer来表示已经分配过了以及标明大小方便回收的时候插入空闲链表。
而对于未分配的块,需要分配一个指向前面一个块的指针和指向后面一个块的指针来显示地组成这个链表
如果使用后进先出的方法那么所有的free操作都可以在常数时间内完成,如果都用了footer进行标记的话合并操作也可以在常数时间内完成。
如果使用的是地址从小到大排列的话那么内存利用率会上升,但相应的要付出更加长的搜索时间的代价。
而显式空闲链表的坏处就是会增加内部碎片。
Segregated free list
下图是我自己做的思维导图
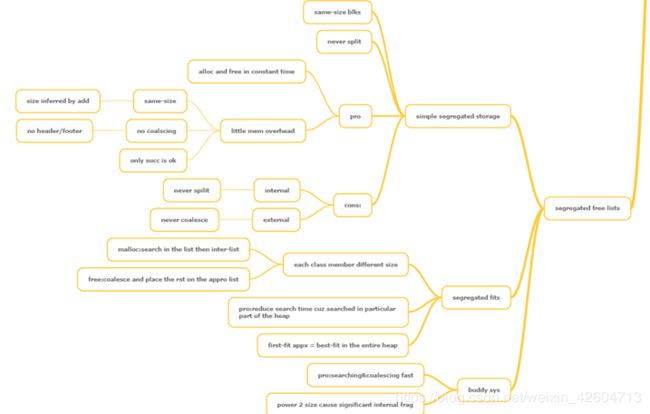
分离链表分:简单分离链表、分离适配和伙伴系统。
简单分离链表的每个等价类中的块大小是一样的,所以可以根据地址判断块大小,所以分配可以在常数时间内完成。因为块大小固定,所以不需要合并,只需要寻找不同的等价类就可以了,那么header和footer也不需要了,只需要一个能够指向后面块的指针就可以了,这样会大降低内存开销,但是一个很大很大的缺陷就是这样会产生很大很大很大的内部和外部碎片(浪费啊!)
分离适配是每个等价类中的块大小不尽相同,而每个等价类代表的是一定的大小范围的块,这样做的好处是可以在堆的某一块中搜索从而降低搜索时间,并且有研究证明分离适配的first-fit大约就等于别的空闲链表的best-fit,内存利用率显著上升。
伙伴系统是对于堆一开始是一整块,然后每次申请空间都会向上舍入到离它最近的2得幂次方字节,通过对现有大小的块进行不断二分直到找到符合舍入后大小的块为止
很明显,这样做的坏处是它向上舍入到2的幂次方字节会产生很大的内部碎片,也有可能产生外部碎片,因此这不适合通用的内存分配,但是一旦我们初始知道分配大小为2的整数次幂的话就非常具有吸引力了,因为分配和合并都非常快。
7.10本章小结
本章主要介绍了 hello 的存储器地址空间、intel 的段式管理、hello 的页式管理, 以i7为例介绍了VA 到PA 的变换、物理内存访问,还介绍了hello 进程 fork 时的内存映射、execve 时的内存映射、缺页故障与缺页中断处理、动态 存储分配管理。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
设备的模型化:文件
设备管理:unix io接口
所有的I/ O 设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行。这种将设备优雅地映射为文件的方式,允许Linux 内核引出一个简单、低级的应用接口,称为Unix I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行,这就是Unix I/O接口。
8.2 简述Unix IO接口及其函数
Unix I/O接口:
1.打开文件。一个应用程序通过要求内核打开相应的文件,来宣告它想要访间一个I/O 设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文件的所有操作中标识这个文件。内核记录有关这个打开文件的所有信息。应用程序只需记住这个描述符。
2.Linux shell 创建的每个进程开始时都有三个打开的文件:标准输入(描述符为0) 、标准输出(描述符为1) 和标准错误(描述符为2) 。头文件< unistd.h> 定义了常量STDIN_FILENO 、STOOUT_FILENO 和STDERR_FILENO, 它们可用来代替显式的描述符值。
3.改变当前的文件位置。对于每个打开的文件,内核保持着一个文件位置k, 初始为0。这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行seek 操作,显式地设置文件的当前位置为K。
4.读写文件。一个读操作就是从文件复制n>0 个字节到内存,从当前文件位置k 开始,然后将k增加到k+n 。给定一个大小为m 字节的文件,当k~m 时执行读操作会触发一个称为end-of-file(EOF) 的条件,应用程序能检测到这个条件。在文件结尾处并没有明确的“EOF 符号” 。类似地,写操作就是从内存复制n>0 个字节到一个文件,从当前文件位置k开始,然后更新k 。
5.关闭文件。当应用完成了对文件的访问之后,它就通知内核关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放它们的内存资源。
Unix I/O函数:
1.进程是通过调用open 函数来打开一个已存在的文件或者创建一个新文件的:
int open(char *filename, int flags, mode_t mode);
open 函数将filename 转换为一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符。flags 参数指明了进程打算如何访问这个文件,mode 参数指定了新文件的访问权限位。
返回:若成功则为新文件描述符,若出错为-1。
2.进程通过调用close 函数关闭一个打开的文件。
int close(int fd);
返回:若成功则为0, 若出错则为-1。
3.应用程序是通过分别调用read 和write 函数来执行输入和输出的。
ssize_t read(int fd, void *buf, size_t n);
read 函数从描述符为fd 的当前文件位置复制最多n 个字节到内存位置buf 。返回值-1表示一个错误,而返回值0 表示EOF。否则,返回值表示的是实际传送的字节数量。
返回:若成功则为读的字节数,若EOF 则为0, 若出错为-1。
ssize_t write(int fd, const void *buf, size_t n);
write 函数从内存位置buf 复制至多n 个字节到描述符fd 的当前文件位置。图10-3 展示了一个程序使用read 和write 调用一次一个字节地从标准输入复制到标准输出。
返回:若成功则为写的字节数,若出错则为-1。
8.3 printf的实现分析
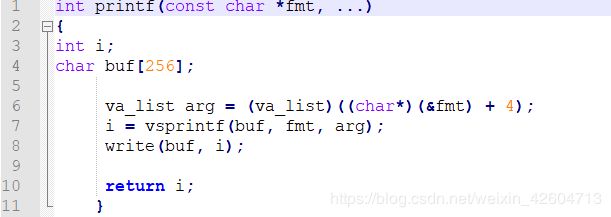
在形参列表里有这么一个token:…
这个是可变形参的一种写法。
当传递参数的个数不确定时,就可以用这种方式来表示。
很显然,我们需要一种方法,来让函数体可以知道具体调用时参数的个数。
先来看printf函数的内容:
这句:
va_list arg = (va_list)((char*)(&fmt) + 4);
va_list的定义:
typedef char va_list
这说明它是一个字符指针。
其中的: (char)(&fmt) + 4) 表示的是…中的第一个参数。 fmt是一个指针,这个指针指向第一个const参数(const char *fmt)中的第一个元素。
fmt也是个变量,它的位置,是在栈上分配的,它也有地址。
对于一个char *类型的变量,它入栈的是指针,而不是这个char *型变量。
接下来是vsprintf这个函数
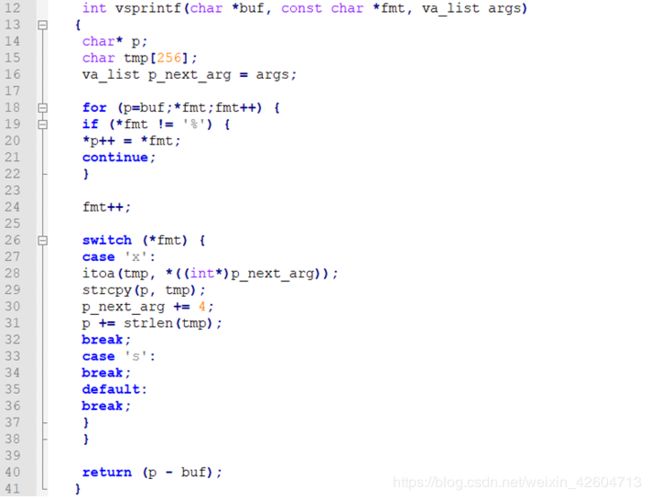
vsprintf返回的是一个长度,返回的是要打印出来的字符串的长度 ,write:写操作,把buf中的i个元素的值写到终端。从vsprintf生成显示信息,到write系统函数,到陷阱-系统调用 int 0x80或syscall.
字符显示驱动子程序:从ASCII到字模库到显示vram(存储每一个点的RGB颜色信息)。
显示芯片按照刷新频率逐行读取vram,并通过信号线向液晶显示器传输每一个点(RGB分量)。
8.4 getchar的实现分析
异步异常-键盘中断的处理:键盘中断处理子程序。接受按键扫描码转成ascii码,保存到系统的键盘缓冲区。
getchar等调用read系统函数,通过系统调用读取按键ascii码,直到接受到回车键才返回。
8.5本章小结
本章介绍了IO管理,简述了linux IO接口和函数,复读了老师给的博客上关于printf的内容,看了半天也没有看的很明白,复读了老师给的getchar的分析。
结论
本文简述了hello从C代码到编译到汇编到链接最后再到执行的过程。
首先是hello诞生的过程:
在预处理阶段,将hello中的宏等逐级展开,并转换成由ASCII码组成的hello.i文件;在编译阶段,编译器将hello.i文件转换成了汇编语言,即机器级语言,汇编器将hello.i文件转换成汇编文件hello.s,可以知道一条高级语言的语句对应的可能有好几条汇编语言语句;在汇编阶段,汇编器将将hello.s文件转换成hello.o文件,进一步将汇编语言转成机器代码,并设置重定位信息,方便链接器进行链接;在链接阶段,将hello.o转换成可执行目标文件hello,这是一个可以直接映射到某个进程的虚拟地址空间中进行运行的,完成了静态链接中的符号解析、重定位和动态链接等步骤,至此hello完全诞生。
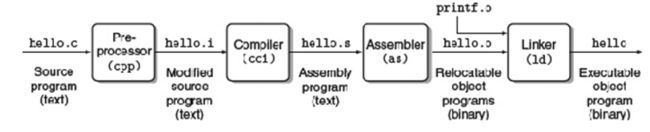
上图是hello“诞生”的过程
接下来是hello执行的过程:
在运行阶段,通过命令行键入命令./hello 1170500804 liushuai就可以使shell创建一个新的子进程来运行这个可执行目标文件:首先子进程能够得到父进程的一切,包括虚拟地址空间、栈、堆、打开文件句柄等等;子进程通过调用execve函数来运行这个可执行目标文件,先删去原有的用户级虚拟内存空间,通过将虚拟页映射到物理内存中,触发缺页中断来加载这个文件等等;执行的时候内核会有调度,也就是时间分片,多任务执行:内核暂时挂起这个进程的执行,调度可以是内核自行根据存放在其中的代码——调度器的算法来进行调度,也可以进程自己显式地请求挂起,也就是发送SIGSTP信号,即Ctrl z,也可以通过Ctrl c继续运行这个程序,当子进程执行完毕,结束的时候shell会安排父进程回收子进程,如果父进程已经结束会安排init进程(pid = 1)来回收,回收后就删去这个进程的所有轨迹。
附件
| 文件 | 功能 |
|---|---|
| hello.i | 预处理后的ASCII码文件 |
| hello.o | 汇编文件 |
| hello.elf | 可重定位目标文件 |
| helloasm.txt | hello.o 反汇编代码 |
| hello | 最终的可执行目标文件 |
| helloasmm.txt | hello 反汇编代码 |
| helloelf_lk.txt | hello的部分elf内容 |
| elfall.txt | hello的全部elf内容 |