Python第三方库jieba以及wordcloud学习笔记
jieba库
jieba库是具有强大分词功能的第三方库。在中文文本分词中具有较好的应用表现。工作机制为
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了系统给定分词,还支持用户自定义添加词组
jieba分词的三种模式:
1、精确分词模式:jieba.lcut(string) 返回一个列表类型的分词结果;
2、全模式:jieba.lcut(string,cut_all=True),返回一个列表类型的分词结果,存在冗余
3、搜索引擎模式:jieba.lcut_for_search(string),返回一个列表类型的分词结果,存在冗余
>>> str="结巴库测试时使用的字符串例子"
>>> eg1=jieba.lcut(str)
>>> eg1
['结', '巴库', '测试', '时', '使用', '的', '字符串', '例子']>>> eg2=jieba.lcut(str,cut_all=True)
>>> eg2
['结巴', '巴库', '测试', '时', '使用', '的', '字符', '字符串', '例子']>>> eg3=jieba.lcu_for_search(str)
>>> eg3
['结', '巴库', '测试', '时', '使用', '的', '字符', '字符串', '例子']
此外,jieba库还支持用户自定义添加词组用于分词。
在上面的例子中,我们可以发现。尽管在我们看来,结巴库应该是被划分为一个词。而分词结果却没有达到这一效果。在执行jieba.add_word(word)后,再进行分词可以得到如下结果
>>> jieba.add_word("结巴库")
>>> eg4=jieba.lcut(str)
>>> eg4
['结巴库', '测试', '时', '使用', '的', '字符串', '例子']
wordcloud库
wordcloud库是一个优秀的第三方词云库,通过把词云当做一个WordCloud对象进行操作,可以生成一段文本中高频词汇组成的词云图。

运用wordcloud库进行上面操作的基本步骤如下
1、获取一段.txt文本文件的内容,并进行处理
2、构建一个WordCloud类型对象,w=wordcloud.WordCloud(<参数>)
3、应用wordcloud库提供的函数.generate()和.to_file()加载文本并输出为图像文件(.png或.jpg格式)
词云对象参数
width:指定词云对象生成图片的宽度,默认400像素
height:高度,默认两百
min_font_size:指定词云字体的最小字号,默认4号
max_font_size:最大字号,根据高度自动调节
font_step:指定词云中字体字号的步进间隔,默认为1
font_path:指定字体文件的路径,默认为None
max_words:指定词云显示的最大单词数量,默认200
stop_words:指定词云的排除词列表,即不显示的单词列表
mask:指定词云形状,默认为长方形,需要引用imread(0函数
运用实例:对三国演义中角色出场频次分析及词云图绘制
import jieba
import wordcloud
def wordStatistics(txt,excludeWord=None):
words = jieba.lcut(txt)
tempExclude=excludeWord
counts = {} # 创建一个空的字典类型
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据键值大小即出场频率由低到高排序
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
txt=open("threeKindoms.txt",'r',encoding='UTF-8').read()
#词频统计部分
exclude={}
wordStatistics(txt)
在执行上述代码后,得到的结果如下
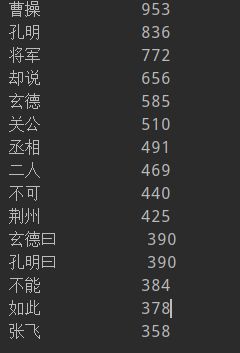
可以看到,其中存在一些无关项或者重叠项。因此需要对代码进一步优化。即增加判断无关词即重叠词归并计数。代码实现如下
import jieba
import wordcloud
def wordStatistics(txt,excludeWord=None):
words = jieba.lcut(txt)
counts = {} # 创建一个空的字典类型
for word in words:
if word in excludeWord or len(word)==1:
continue
elif word=='孔明' or word=='孔明曰' or word=='诸葛亮':
word='孔明'
counts[word] = counts.get(word, 0) + 1
elif word=='曹操' or word=='孟德' or word=='丞相' or word=='主公':
word='曹操'
counts[word] = counts.get(word, 0) + 1
elif word=='刘备' or word=='玄德' or word=='玄德曰' or word=='大耳儿':
word='刘备'
counts[word] = counts.get(word, 0) + 1
elif word=='云长' or word=='关公' or word=='关羽':
word='关羽'
counts[word] = counts.get(word, 0) + 1
elif word=='张飞' or word=='翼德':
word='张飞'
counts[word] = counts.get(word, 0) + 1
elif word=='赵云' or word=='子龙':
word='赵云'
counts[word] = counts.get(word, 0) + 1
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据键值大小即出场频率由低到高排序
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
txt=open("threeKindoms.txt",'r',encoding='UTF-8').read()
#词频统计部分
exclude={'却说',"不能",'如此','不可','二人','荆州'}
wordStatistics(txt,excludeWord=exclude)
得到新的结果如下:

可以看出来来,在更改后,又出现了其他新的无关词汇。别名情况几乎没有。当然,在分配word的过程中,统计结果精确程度就看各位对三国的熟悉程度啦。我读过几遍三国,印象中是:曹操通常被称为丞相,主公也多一点。到死也没有称帝。而刘备的大耳儿,则是出现在吕布被曹操弄死的那天。曹操在抓到吕布后,问刘备该如何处置。刘备说,还记得丁原、董卓他们的下场吗?于是曹操决定处死吕布。吕布临时前对刘备说,"大耳儿,犹记轩辕门射戟乎?"当年刘备被袁绍还是谁欺负的时候,去求吕布帮忙。搞了个轩辕门射戟。说是,我用这方天画戟射中100尺外的什么东西,这事儿就算了,大家伙和气生财。(这里可以看出,吕布不是莽夫。既没有拒绝刘备,在另一方看来也是不可能的事情,不算得罪)。当然,将军这个词一定是没有统计的词频,涉及到的武将太多啦。--题外话
进一步将无关项加入排除列表,优化,得到最后结果。

import jieba
import wordcloud
def wordStatistics(txt,excludeWord=None):
words = jieba.lcut(txt)
counts = {} # 创建一个空的字典类型
for word in words:
if word in excludeWord or len(word)==1:
continue
elif word=='孔明' or word=='孔明曰' or word=='诸葛亮':
word='孔明'
counts[word] = counts.get(word, 0) + 1
elif word=='曹操' or word=='孟德' or word=='丞相' or word=='主公':
word='曹操'
counts[word] = counts.get(word, 0) + 1
elif word=='刘备' or word=='玄德' or word=='玄德曰' or word=='大耳儿' or word=='先主':
word='刘备'
counts[word] = counts.get(word, 0) + 1
elif word=='云长' or word=='关公' or word=='关羽':
word='关羽'
counts[word] = counts.get(word, 0) + 1
elif word=='张飞' or word=='翼德':
word='张飞'
counts[word] = counts.get(word, 0) + 1
elif word=='赵云' or word=='子龙':
word='赵云'
counts[word] = counts.get(word, 0) + 1
elif word=='后主' or word=='刘禅' or word=='阿斗':
word='刘禅'
counts[word] = counts.get(word, 0) + 1
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据键值大小即出场频率由低到高排序
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
txt=open("threeKindoms.txt",'r',encoding='UTF-8').read()
#词频统计部分
exclude={'却说',"不能",'如此','不可','二人','荆州','将军','商议','次日','引兵','军马','如何','军士','左右'\
,'大喜','天下','今日','于是','魏兵','不敢','东吴','陛下','一人','人马','不知','汉中','只见'\
,'众将','蜀兵','上马','大叫','太守','都督','此人','夫人','后人','背后','城中','天子','一面','何不'}
wordStatistics(txt,excludeWord=exclude)接下来便是根据统计出来的词频绘制一个简单的词云图了。在这里,需要用到wordcloud库贴心提供的根据使用频率来绘制图云的函数
.generate_from_frequencies(text)
import jieba
import wordcloud
def wordStatistics(txt,excludeWord=None):
words = jieba.lcut(txt)
counts = {} # 创建一个空的字典类型
for word in words:
if word in excludeWord or len(word)==1:
continue
elif word=='孔明' or word=='孔明曰' or word=='诸葛亮':
word='孔明'
counts[word] = counts.get(word, 0) + 1
elif word=='曹操' or word=='孟德' or word=='丞相' or word=='主公':
word='曹操'
counts[word] = counts.get(word, 0) + 1
elif word=='刘备' or word=='玄德' or word=='玄德曰' or word=='大耳儿' or word=='先主':
word='刘备'
counts[word] = counts.get(word, 0) + 1
elif word=='云长' or word=='关公' or word=='关羽':
word='关羽'
counts[word] = counts.get(word, 0) + 1
elif word=='张飞' or word=='翼德':
word='张飞'
counts[word] = counts.get(word, 0) + 1
elif word=='赵云' or word=='子龙':
word='赵云'
counts[word] = counts.get(word, 0) + 1
elif word=='后主' or word=='刘禅' or word=='阿斗':
word='刘禅'
counts[word] = counts.get(word, 0) + 1
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据键值大小即出场频率由低到高排序
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
return counts
txt=open("threeKindoms.txt",'r',encoding='UTF-8').read()
#词频统计部分
exclude={'却说',"不能",'如此','不可','二人','荆州','将军','商议','次日','引兵','军马','如何','军士','左右'\
,'大喜','天下','今日','于是','魏兵','不敢','东吴','陛下','一人','人马','不知','汉中','只见'\
,'众将','蜀兵','上马','大叫','太守','都督','此人','夫人','后人','背后','城中','天子','一面','何不'}
result=wordStatistics(txt,excludeWord=exclude)
#绘制图云部分
w=wordcloud.WordCloud(font_path="msyh.ttf",max_words=15,background_color="white",font_step=2)
w.generate_from_frequencies(result)
w.to_file("threeKingdoms.png")
其实在绘制图云部分,看似只有三行代码,实际上却卡了我一会儿。我是真滴蠢~因为我不知道他提供了按照频率即字典键值大小来绘制图云的功能啊。后来翻了一下官网示例代码才搞明白。学习了。

有需要txt文件的可以百度云自取:
链接:https://pan.baidu.com/s/1SWYAXq0nGNJVRXwU-u8brw 提取码:2vz4
请听下回分解~