Spark集群启动流程-Master启动-源码分析
Spark集群启动流程-Master启动-源码分析
总结:
1.初始化一些用于启动Master的参数
2.创建ActorSystem对象,并启动Actor
3.调用工具类AkkaUtils工具类来创建actorSystem(用来创建Actor的对象)
4.创建属于Master的actor,在创建actor的同时,会初始化Master
5.生命周期方法(preStart)是在构造器之后,receive方法之前执行,只会执行一次
6.启动一个定时器,定时检查超时的Worker
7.获取到超时的Worker然后把他移除掉(删除内存和磁盘里的workerinfo)
8.启动receive方法,会不断的执行,用于接收actor发送过来的请求
详解:
我们先来看看启动的命令脚本,进入到\spark\bin\下,cat start-all.sh,可以看到,它其实内部调用了很多其他的脚本
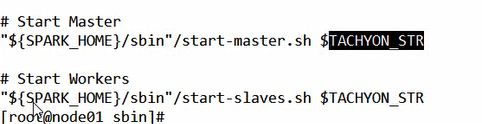
先启动了start-master.sh,再次cat start-master.sh

可以看到,它将CLASS 1这个变量传给了sbin目录下的soark-daemon.sh,往上翻会看到CLASS 1的具体指的是“org.apache.spark.deploy.master.Master”,即传的值是Master的全类名,我们cat一下soark-daemon.sh
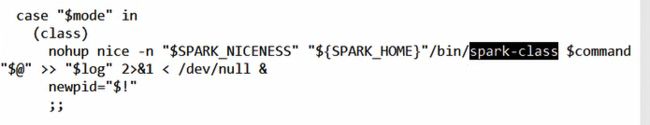
它最终调用一个类来启动服务,再cat一下start-slaves.sh

它传入的是spark的url,这里就是启动了worker了,可以用start-slaves.sh单独启动Master和Worker
从上述中我们可以看出他们启动的都是一个类,所以下面,我们只分析Master类和Worker类,首先将安装包下的core包导入到IDEA中我们来进行逐步分析(导入略)
首先我们搜索找到Master
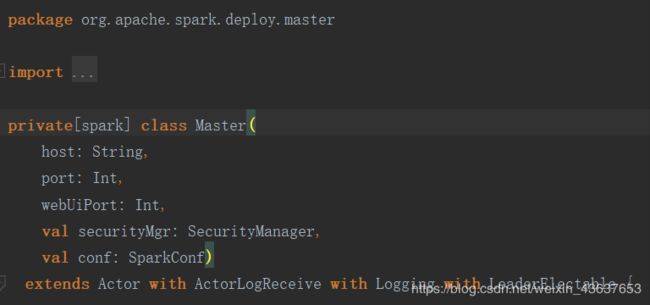
这是Master类,既然要启动就一定有main方法,一般他是放在一个伴生对象里,我们在搜索框里输入object找到伴生对象,其中有main方法
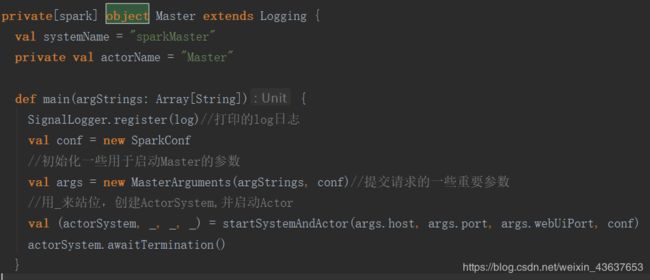
在main方法中new了一个MasterArguments并将conf和一些重要的启动参数argStrings传入其中,并将args传入到startSystemAndActor这个方法中,我们先点开startSystemAndActor方法看看
它调用了AkkaUtils工具类下的createActorSystem方法,最后一行返回了四个值,后面三个值就是赋值给前面用_占的位
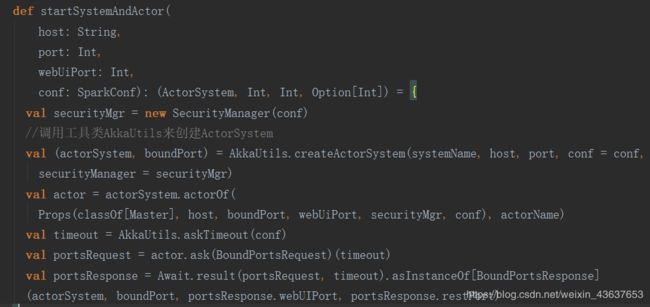
调用工具类AkkaUtils来创建ActorSystem,ActorSystem就是创建Actor的方法,我们点进去createActorSystem方法看一下
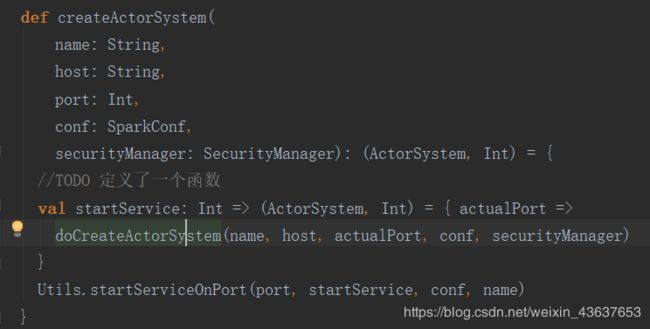
这里定义了一个startService的函数,函数里面调用了doCreateActorSystem方法,就在下面,里面就是一些初始化成
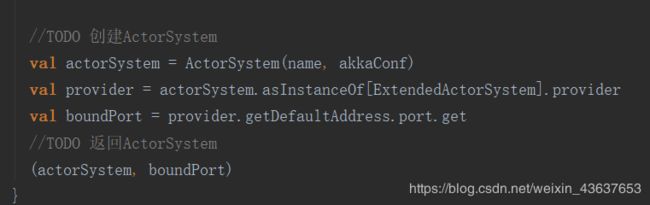
创建了ActorSystem,直接类名加小括号里面传参,说明是通过调用了ActorSystem里的apply方法来创建了这个actorSystem实例,当然这里可以用ActorSystem.create方法来创建。我们返回到Master里的startSystemAndActor中,现在ActorSystem已经创建完成并且返回给了val (actorSystem,boundPort)中的actorSystem,接下来我们就用actorSystem这个实例来创建actor了,调用的就是actorOf方法
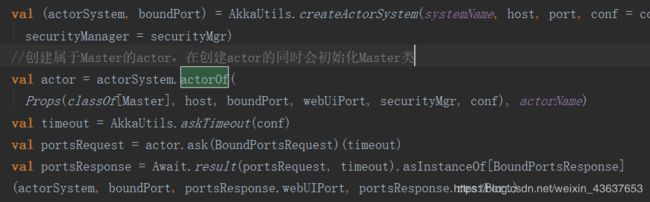
然后通过classOf反射的方式拿到Master这个类来启动Master的actor,在创建actor的同时会初始化Master类。
接下来呢,将会执行一个叫preStart的生命周期方法,这个方法,是在构造器之后,receive方法之前执行,而且只执行一次。
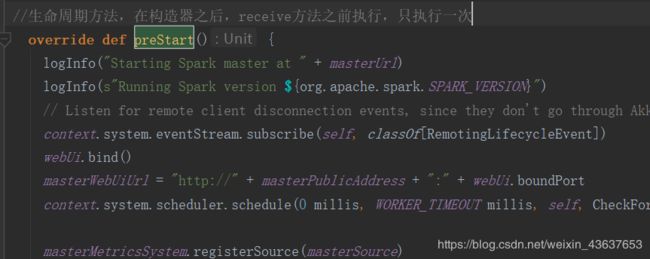
那么接下来就要实现这个方法里面的内容了,那么,根据之前的学习,我们知道,这时候呢应该要启动一个定时器:

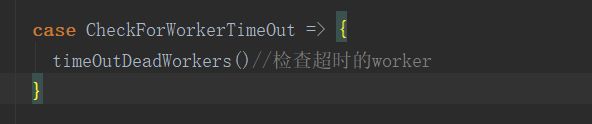
//第一个参数,是从什么时候开始,第二个参数是从什么时候结束点 // 进去会发现它默认的是60秒检查一次worker //第三个参数是指的是自己给自己发送检查能否正常运行,第五个参数,是检查 //超时的worker的逻辑,点进去则是一个模式匹配,再次点进去,会发现,其实他 就执行了一个方法timeOutDeadWorkers()
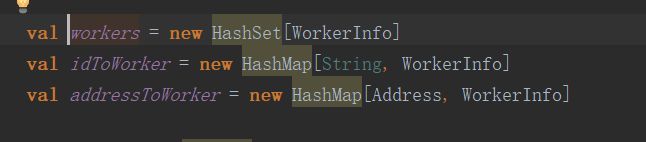
我们再次点进去timeOutDeadWorkers方法中。首先,它调用了系统的时间,然后,调用了一个变量workers,里面的类型是new HashSet[WorkerInfo],WorkerInfo再点进去,里面其实存储的都是发送过来的一些连接信息,用HashSet,那么他有个去重的功能。这里不光有workers变量,还有idToWorker,这里用HashMap来存,那么key是id,value是这个id对应的WorkerInfo,还有addressToWorker,则是这个地址对应的WorkerInfo
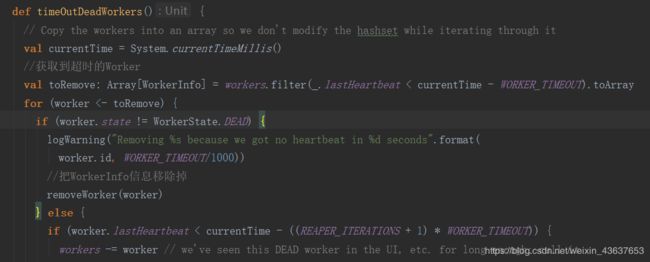
那么拿到这些数据,我们进行过滤,就是过滤超时的worker,它每次拿到一个worker,进行心跳时间的判断,lastHeartbeat是最后一次心跳时间,它里面是一个var的int类型,并用_来初始化。那么当前的时间我们获取到了减去超时的阈值60,即最后一次心跳时间 < 当前时间 - 超时时间阈值60,通过这样过滤,那么,当60秒没有心跳,我们就过滤出来toArray之后赋给了toRemove。
接下来执行一个for循环,我们把每一次超时的worker拿出来,if进行判断,当.state不等于DEAD时候,执行了remove,把WorkerInfo信息移除掉
点进去这个removeWorker方法中
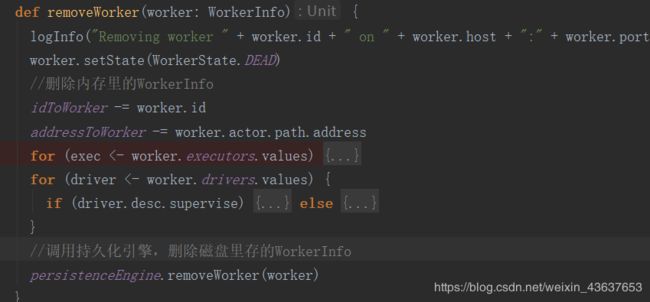
它将idToWorker和addressToWorker 移除掉了,这里最后它还将磁盘里的一份WorkerInfo也删除了。
那么这是preStart方法启动完成及里面一些重要的功能,到这里全部启动了
接下来,启动一个receive方法,这里叫receiveWithLogging,这个方法他会不但的循环执行,来接受actor发过来的请求。那么到此,这个Master就启动了

其实在启动的过程中,Master和Worker一起启动的,所以下一篇文章将介绍worker的启动 https://blog.csdn.net/weixin_43637653/article/details/84099110