Java函数式编程
文章目录
- 一、Lambda
- 1. Lambda表达式
- 2. 函数接口
- 2.1 Function
- 2.2 Consumer
- 2.3 Supplier
- 2.4 Predicate
- 2.5 Operator
- 二、流
- 1. 定义流
- 2. 流操作
- 2.1 filter
- 2.2 map、flatMap
- 2.3 distinct、sorted、peek
- 2.4 limit、skip
- 2.5 forEach、forEachOrdered
- 2.6 min、max、count
- 2.7 anyMatch、allMatch、noneMatch
- 2.8 findFirst、findAny
- 2.9 reduce、collect
- 三、收集器
- 1. 定义收集器
- 2. 自带收集器
- 2.1 toCollection
- 2.2 toMap
- 2.3 joining
- 2.4 mapping
- 2.5 summingInt、summarizingInt、averagingInt
- 2.6 groupingBy、partitioningBy
- 2.8 collectingAndThen
- 四、并行
- 1. fork/join
我们从小学数学开始,就会慢慢形成函数的概念,简单的说,函数描述的就是自变量与因变量的映射关系。不管是在编程语言中,还是一个在系统设计中,都会用到函数思想来设计。它就像是一个黑箱子,我们在调用函数的时候,不用在乎函数内部的实现,只需要保证输入参数调用能返回想要的结果。运用函数思想去思考许多问题,都能简化模型,比如,调用一个接口或一个微服务,我只需关注传入的参数和返回正确的结果,而不需要过多关注内部实现。
一、Lambda
对于Java开发人员来说,抽象的概念并不陌生,面向对象编程是对数据进行抽象,而函数式编程是对行为进行抽象,数据和行为这两种方式结合使用,才能开发出更易读、易维护、可靠的代码。尤其是在写回调函数和事件处理程序时,不用编写繁杂的,可读性差的匿名内部类,使用函数式编程会更简单。
1. Lambda表达式
Lambda表达式是JDK8提供的一种新语法,来简化匿名内部类,Lambda表达式使用 -> 箭头来连接参数和方法体,对于函数接口才能使用Lambda表达式来实现。要想使用Lambda表达式,定义的函数接口只能存在一个接口方法,不包括默认方法。所以,在定义函数接口的时候会使用 @FunctionInterface 注解来标注这是一个函数接口。例如:
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
2. 函数接口
在JDK自带的 java.util.function 包下提供了几类常用的函数接口。在后面我们讲的函数接口中,只讲一般形式,不讲衍生形式,比如:Function 类接口只会讲 Function 接口,不会讲它的衍生接口,像 IntFunction等,因为一般形式掌握了,衍生形式也就没问题了。
2.1 Function
Function 一般接口提供了一个含有一个参数并有返回结果的方法。例如使用 Function 接口来求一个数的平方:
Function<Integer, Integer> f = x -> x * x;
System.out.println(f.apply(2));
2.2 Consumer
Consumer 一般接口提供了一个含有一个参数没有返回结果的方法。例如使用 Consumer 接口来在控制台打印字符串:
Consumer<String> f = System.out::println;
f.accept("Hello world");
2.3 Supplier
Supplier 一般接口提供了一个没有参数有返回结果的方法。例如使用 Supplier 接口来获取一个随机整数:
Supplier<Integer> f = () -> new Random().nextInt();
System.out.println(f.get());
2.4 Predicate
Predicate 一般接口提供了一个含有一个参数并返回 boolean 结果的方法。例如使用 Predicate 接口来判断一个数是否为偶数:
Predicate<Integer> f = x -> x % 2 == 0;
System.out.println(f.test(3));
2.5 Operator
Operator 类接口提供了一些含有一个或两个参数并有返回结果的方法。例如使用 BinaryOperator 接口求直角三角形已知两直角边求斜边:
BinaryOperator<Double> f = (x, y) -> Math.sqrt(x * x + y * y);
System.out.println(f.apply(3.0, 4.0));
二、流
JDK8还增加了流(Stream)操作,它结合函数式接口使得集合的操作变得更加简单和方便,而且还使并行编程变得简单。把对集合的操作转向对流的操作,利用流更丰富的API来使代码变得简洁、高效。
并行不同于并发,并发是在一个CPU上的通过时间调度来完成任务的,并行是多个CPU同时执行任务,效率更高,并行化编程会充分利用多核CPU的优势,从而加快程序运行效率。
1. 定义流
Stream 接口提供的 empty() 方法可以定义一个没有任何元素的流,如下:
Stream<?> stream = Stream.empty();
Stream 接口提供的 of(T...) 方法可以使用一组初始值来定义一个流,如下:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
也可以从现有的集合或者数组中生成一个流,如下:
// 使用 Collection 接口中的 stream() 方法生成
List<Integer> list = new ArrayList<>();
Stream<Integer> stream = list.stream();
// 使用 Arrays 工具类中的 stream(T[] array) 方法生成
Integer[] array = new Integer[5];
Stream<Integer> stream = Arrays.stream(array);
2. 流操作
我们在进行流操作前,先定义示例数据,新建以下示例类:
// 老师
public class Teacher {
private String name;
}
// 学生
public class Student {
private String name;
private Integer age;
private Boolean gender; // true:男生,false:女生
private Double score;
}
// 班级
public class Clazz {
private String no;
private List<Teacher> teachers;
private List<Student> students;
}
上面的示例中,每个班级中有多个老师和多个学生。
2.1 filter
filter 方法可以通过给定条件来过滤流中的元素,Predicate 函数参数提供过滤条件。操作示意图如下:

例如,已知一个班级的所有学生信息,返回这个班级的所有男生信息:
List<Student> boys = students.stream()
.filter(Student::getGender)
.collect(Collectors.toList());
上面代码中的
collect(Collectors.toList())收集器是将流转换成List的操作,收集器会在后面说到。
2.2 map、flatMap
map 方法可以转一个类型转换成另外一个类型,所以可以将一个流转换成另外一个流,Function 函数参数提供转换的操作。操作示意图如下:

例如,已知一个班级的所有学生信息,返回这个班级的学生姓名列表:
List<String> nameList = students.stream()
.map(student -> student.getName())
.collect(Collectors.toList());
衍生操作:
mapToInt, mapToLong, mapToDouble,这些操作固定了转换的类型。
flatMap 方法可以将一个类型转换成另一个流类型,并且将多个流合并成一个流,Function 函数参数提供转换的操作,它与 map 方法的不同是 map 函数参数返回其他类型,而它的函数参数返回流类型。操作示意图如下:
[外链图片转存失败(img-4CGFhuWf-1563114572524)(function/stream-flatMap.png)]
例如,已知学校所有的班级信息,返回全校所有学生的信息:
List<Student> students = classes.stream()
.flatMap(clazz -> clazz.getStudents().stream())
.collect(Collectors.toList());
衍生操作:
flatMapToInt, flatMapToLong, flatMapToDouble,这些操作固定了转换的类型。
2.3 distinct、sorted、peek
distinct 方法根据对象的 equals() 方法来对流中的元素进行去重操作。如果自己定义的类型需要重写 equals() 方法。例如去除学生列表中的重复数据:
List<Student> list = students.stream()
.distinct()
.collect(Collectors.toList());
sorted 方法对一个流中的元素进行排序操作,如果不传比较器参数,元素对象需要实现 Comparable 接口来定义该类型的比较方法,下面通过带比较器参数的 sorted 方法来实现一个班级学生信息按照成绩倒序排序:
List<Student> list = students.stream()
.sorted((o1, o2) -> -o1.getScore().compareTo(o2.getScore()))
.collect(Collectors.toList());
peek 方法可以对元素进行操作,但不会转换元素类型,Consumer 函数参数可以进行操作。例如打印一个班级学生的姓名:
List<Student> list = students.stream()
.peek(student -> System.out.println(student.getName()))
.collect(Collectors.toList());
2.4 limit、skip
limit 方法可以根据传入的最大个数参数对流进行截取。例如获取一个班级学生的前三名:
List<Student> list = students.stream()
.sorted(((o1, o2) -> -o1.getScore().compareTo(o2.getScore())))
.limit(3)
.collect(Collectors.toList());
流操作过程是先根据成绩倒序排序,再截取前三个元素。
skip 方法可以跳过前面几个元素对流进行操作时,如果跳过的个数不小于流的元素个数,将会返回一个空的流。例如获取一个班级学生从第四名开始的学生:
List<Student> list = students.stream()
.sorted(((o1, o2) -> -o1.getScore().compareTo(o2.getScore())))
.skip(3)
.collect(Collectors.toList());
2.5 forEach、forEachOrdered
forEach 和 forEachOrdered 都是遍历流的操作,但在并行流操作的时候,forEach 方法不能保证元素是按顺序处理的,如果需要保证顺序,则需要使用 forEachOrdered,当然有顺序操作会影响并行操作的效率。
2.6 min、max、count
min 方法和 max 方法是通过传入比较器来返回流中最小和最大的元素。例如获取一个班级中成绩最好的同学和成绩最差的同学:
Student student = students.stream()
.max(Comparator.comparing(Student::getScore))
.orElse(null);
Student student = students.stream()
.min(Comparator.comparing(Student::getScore))
.orElse(null);
min方法和max方法返回Optional对象。
count 方法返回当前流中元素的个数。
2.7 anyMatch、allMatch、noneMatch
anyMatch 方法可以在流中匹配是否含有某个元素,只要匹配的元素存在一个或一个以上,返回 true,Predicate 函数参数给定了匹配的规则。操作示意图如下:
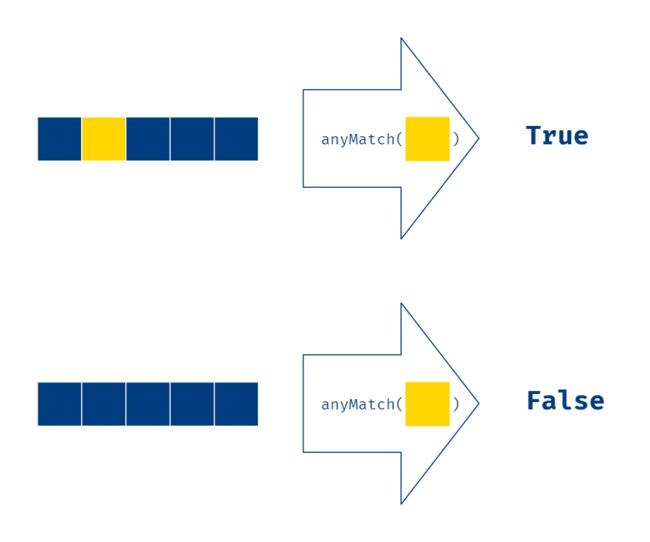
例如,已知一个班级的学生信息,判断这个班级的学生中是否含有男生:
boolean haveBoy = students.stream()
.anyMatch(Student::getGender);
allMatch 方法可以判断流中所有元素是否符合匹配规则,匹配的元素必须为流中所有的元素,才返回 true。操作示意图如下:

例如,已知一个班级的学生信息,判断这个班级的学生成绩是否全部及格:
boolean good = students.stream()
.allMatch(student -> student.getScore().compareTo(60.0) > 0);
noneMatch 方法可以判断流中所有元素是否都不符合匹配规则,匹配的元素流中一个都没有,返回 true。操作示意图如下:
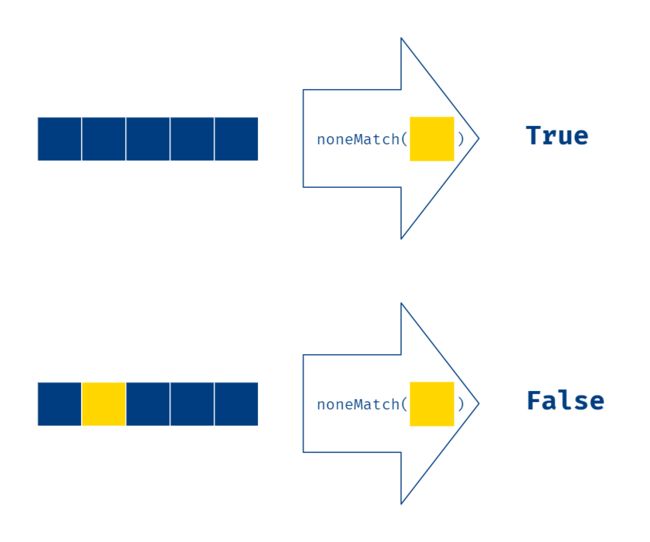
例如,已知一个班级的学生信息,判断这个班级的学生成绩是否一个满分的都没有:
boolean perfect = students.stream()
.noneMatch(student -> student.getScore() == 100.0);
2.8 findFirst、findAny
findFirst 和 findAny 方法都可以从流中获取一个元素,在串行流中,这两个方法都会返回流的第一个元素,但在并行流中,findAny 方法返回的是最快执行完操作的那个元素,如果操作对顺序没有要求,findAny 的效率要高于 findFirst,这两个方法返回的都是 Optional 类。例如返回流中第一个元素:
Student student = students.stream()
.findFirst()
.orElse(null);
2.9 reduce、collect
reduce 方法可以用来对流进行聚合,它有三个重载方法,可以针对不同场合使用。第一个方法如下:
Optional<T> reduce(BinaryOperator<T> accumulator);
// 功能等效于下面操作
boolean foundAny = false;
T result = null;
for (T element : stream) {
if (!foundAny) {
foundAny = true;
result = element;
} else {
result = accumulator.apply(result, element);
}
}
return foundAny ? Optional.of(result) : Optional.empty();
注意该方法返回的是一个 Optional 类,该方法从流中第一个元素开始通过 accumulator 函数进行聚合,accumulator 函数的第一个参数为聚合结果,第二个参数为元素,例如对一个整型数据流进行求和:
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
Integer sum = stream.reduce((a, b) -> a + b).orElse(0);
第二个重载方法添加了一个初始值,方法如下:
T reduce(T identity, BinaryOperator<T> accumulator);
// 功能等效于下面操作
T result = identity;
for (T element : stream) {
result = accumulator.apply(result, element);
}
return result;
该方法与第一个方法功能一样,只不过在聚合时提供了一个初始值参数,例如对一个整型数据流基于5进行求和:
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
Integer sum = stream.reduce(5, (a, b) -> a + b);
第三个重载方法与第二个功能类似,返回类型可以转换,方法如下:
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
该方法用于串行流中,第三个函数参数不会执行,无论返回什么都不会执行,功能与第二个方法一模一样,但在并行流中,第三个参数用来定义组合操作,与前面两个方法不同的是,第三个方法可以返回与流中元素不同类型的返回值。下面分别使用串行和并行流来进行 reduce 操作:
// 串行 执行后no的值为:N1234
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
String no = stream.reduce("N", (a, b) -> a + b, (a, b) -> a + b);
// 并行 执行后no的值为: N1N2N3N4
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
String no = stream.parallel().reduce("N", (a, b) -> a + b, (a, b) -> a + b);
所以在并行流中,无论是使用 reduce 的第二个方法,还是第三个方法,对初始值的处理会不同于串行流,并行流中看上去是流中每个元素都与初始值进行了操作。
collect 方法看上去与 reduce 方法功能一样,只是操作的函数由 BiFunction 换成了 BiConsumer,所以我们可以看出,collect 对流进行聚合操作的时候,不用返回结果,只是可以在结果的引用上进行修改。它有两个重载方法,第一个方法如下:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
// 功能等效于下面操作
R result = supplier.get();
for (T element : stream)
accumulator.accept(result, element);
return result;
这个方法看上去和 reduce 的第三个方法一样,只是初始值的提供换成了 Supplier 函数参数提供,accumulator 聚合操作换成了 BiConsumer 函数。我们使用这个方法来模拟前面一直用的 collect(Collectors.toList()) 方法:
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
List<Integer> list = stream
.collect(() -> new ArrayList<>(),
(res, ele) -> res.add(ele),
(left, right) -> left.addAll(right));
第一个函数参数提供一个初始集合容器,第二个函数参数提供聚合元素的操作,第三个函数参数在并行流中提供将并行执行的结果进行组合操作,这一套路和 reduce 一样。
collect 的第二个重载方法更简单了,JDK将常用的一些聚合的操作都封装成了 Collectors 收集器,方法如下 :
<R, A> R collect(Collector<? super T, A, R> collector);
三、收集器
前面我们已经讲过了流的聚合操作,在对流进行一系列操作后,最终再聚合成我们想要的数据结构,我们可以使用JDK提供的收集器,也可以自己定义一个收集器。
1. 定义收集器
定义一个收集器只需要实现 Collector 接口,然后使用流的 collect 方法来使用,下面我们自己模拟 Collectors.joining() 收集器,首先定义收集器:
public class StringCollector implements Collector<Object, StringJoiner, String> {
@Override
public Supplier<StringJoiner> supplier() {
return () -> new StringJoiner(",", "[", "]");
}
@Override
public BiConsumer<StringJoiner, Object> accumulator() {
return ((stringJoiner, o) -> stringJoiner.add(o.toString()));
}
@Override
public BinaryOperator<StringJoiner> combiner() {
return StringJoiner::merge;
}
@Override
public Function<StringJoiner, String> finisher() {
return StringJoiner::toString;
}
@Override
public Set<Characteristics> characteristics() {
return Collections.emptySet();
}
}
使用上面定义的收集器:
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
String str = stream.collect(new StringCollector());
// str的值为:[1,2,3,4]
2. 自带收集器
2.1 toCollection
将流转换成集合。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
List<Integer> collection = stream.collect(Collectors.toCollection(() -> new ArrayList<>()));
List<Integer> list = stream.collect(Collectors.toList());
Set<Integer> set = stream.collect(Collectors.toSet());
三个收集器:
toCollection:通过函数提供集合类型,可以用于自己封装的集合类型toList:将流转换成List集合toSet:将流转换成Set集合
2.2 toMap
将流转成Map,例如,已知一个班级的学生信息,将学生列表转换成以姓名为Key,学生信息为Value的Map:
Map<String, Student> map = students.stream()
.collect(Collectors.toMap(Student::getName, Function.identity()));
2.3 joining
将流中每个元素通过指定分隔符拼接成字符串。例如,已知一个班级的学生信息,将学生的姓名拼接成用逗号隔开的字符串:
String collect = students.stream()
.map(Student::getName)
.collect(Collectors.joining(","));
可以使用
joining的另一个重载方法指定结果字符串的前缀和后缀。
2.4 mapping
将流中的元素类型转成成另一种类型,与 map 方法类似。例如,获取学生的姓名列表:
List<String> collect = students.stream()
.collect(Collectors.mapping(Student::getName, Collectors.toList()));
// 等效于
List<String> collect = students.stream()
.map(Student::getName)
.collect(Collectors.toList());
这种与流中方法类似的集合器的还有:
minBy等效于minmaxBy等效于maxcounting等效于countreducing等效于reduce
2.5 summingInt、summarizingInt、averagingInt
summingInt、summingLong、summingDouble 都是用来对相应类型的数据进行统计的,返回值对应 IntSummaryStatistics、LongSummaryStatistics、DoubleSummaryStatistics,它们都包含统计项:计数、最小值、最大值、平均值、总和。例如,已知一个班级的学生信息,统计学生的成绩:
DoubleSummaryStatistics statistics = students.stream()
.collect(Collectors.summarizingDouble(Student::getScore));
// {count=6, sum=500.000000, min=59.000000, average=83.333333, max=95.000000}
averagingInt、averagingLong、averagingDouble 只是用来统计平均值。
summarizingInt、summarizingLong、summarizingDouble 只是用来统计总和。
2.6 groupingBy、partitioningBy
groupingBy 方法可以分组收集流数据,会生成一个以分组字段为Key的Map,如果要按自己定义的类分组,该类需要重写 hashCode 方法。例如,已知一个班级的学生信息,按性别分组:
Map<Boolean, List<Student>> collect = students.stream()
.collect(Collectors.groupingBy(Student::getGender));
partitioningBy 是用于分区,功能和 groupingBy 类似,返回结果类型也一样,但分区方法的返回Map的Key只能是 Boolean 类型,所以结果只能分为两组。
2.8 collectingAndThen
collectingAndThen 方法可以对流进行聚合后,再添加后置操作,该方法第一个参数是收集器,第二个参数是 Function 函数,用于后置操作。例如将流收集成List后再返回集合的大小:
Integer collect = students.stream()
.collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
四、并行
数据并行化是将原有的数据集合分割成多个部分,然后给每个部分分配单独的处理单元。比如使用多核CPU的计算机,并行处理就会把数据分发到这多个CPU上单独处理。它与并发不同,并发是在单核上根据时间调度来处理的。当然并行计算并不意味着代码性能就一定能得到提升,影响并行计算的几个主要因素有:
- 数据大小,数据量必须足够大,这样并行任务的拆分和结果的合并这些额外的开销可以忽略。
- 源数据结构,通常是集合,分割相对容易。
- 装箱,处理基本类型比处理装箱类型要快。
- 核的数量,计算机只有一个内核,没必要并行。
- 单元处理开销,流中每个元素的操作时间越长,并行的性能提升越明显。
流的并行化操作非常简单,有两种方式可以生成并行流:
Stream<Student> stream = students.parallelStream();
Stream<Student> stream = students.stream().parallel();
1. fork/join
并行流的底层操作使用了 fork/join 框架,JDK自带的 ForkJoinPool 线程池就可以实现这项操作,它的原理很简单,将现有的任务以递归的形式一层一层拆分成多个子任务,然后多个子任务并行操作,执行完成后将子任务的结果再合并成最终结果。操作示意图如下:

参考文献
[1]:《Java8函数式编程》王群锋译,[英] Richard Warburton著