I3D【Inflated 3D ConvNet】——膨胀卷积网络用于行为识别
I3D:Quo Vadis,Action Recognition? A New Model and the Kinetics Dataset
论文地址:https://arxiv.org/pdf/1705.07750.pdf
最近读了一篇行为识别的论文I3D,全名《Quo Vadis,Action Recognition? A New Model and the Kinetics Dataset》。该论文是一篇CVPR2018年的论文。使用了新的数据集Kinetics重新评估了当前最新的模型架构,Kinetics数集有400个人体行为类别,每个类别有400多个clips,这些数据来自真实有挑战的YouTube视频。作者提出的双流膨胀3D卷积网络(I3D),该网络是对一个非常深的图像分类网络中的卷积和池化kernel从2D扩展到了3D,来无缝的学习时空特征。并且模型I3D在Kinetics预训之后,I3D在基准数据集HMDB-51和UCF-101达到了80.9%和98.0%的准确率。
在ImageNet上训练好的深度结构网络可以用于其他任务,同时随着深度结构的改进,效果也越来越好。然而,在视频领域,有一个公开的问题,在一个足够大的数据集上训练好的行为识别网络应用于不同的时序任务或数据集上是否有类似性能的提升。为了回答这个问题,作者通过实验重新实现了许多有代表性的神经网络结构,之后通过对这些网络在Kinetics上预训练,之后对这些网络在HMDB-51和UCF-101数据集上进行微调来分析他们的迁移行为,最终作者发现通过预训练这些模型表现上有很大提升,但是性能的提升很大程度上与网络的结构有关。正是基于此发现,作者提出了I3D,在Kinetics充分的预训练之后,可以实现很好的表现。I3D主要依据最优的图像网络架构实现的,并对他们的卷积和池化核从2D扩展到3D,并选择使用它们的参数,最终得到了非常深的时空分类网络。作者也发现,基于在Kinetics预训练的InceptionV1的I3D模型的表现远远超过了其他最优的模型的I3D。
在行为分类结构部分,作者指出,在视频领域,没有像图像那样有明确清晰的前端运行框架。当前,行为识别方法的主要不同在于,卷积和层运算是使用2D核还是3D核;是否输入仅仅包括输入视频或者也包括预计算的光流信息;在这部分,作者比较和研究了一些模型,这些模型有的基于2D卷积实现,也有的是基于3D ConvNet实现。同时,由于高维的参数和缺乏视频数据,以前的3D ConvNets一直相对浅,作者指出,非常深的图像分类网络可以被膨胀为时空特征提取网络,同时它们的参数初始化膨胀网络,并说明了双流网络配置仍然是有效的。之后,作者基于在ImageNet上预训练的带BN的InceptionV1为骨干,搭建了五种行为分类网络,其中四种为基于以前论文搭建的网络,最后一种作者提出网络I3D,如图1为结构描述,如图2为参数大小和网络输入设置。具体每种结构描述如下:
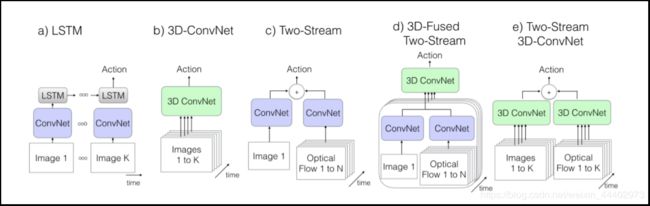
图1. 论文考虑不同行为识别结构
ConvNet+LSTM:每一帧都提取feature后整视频pooling,或者每一帧提feature+LSTM。缺点,前者忽略了时间信息,open和close door会分错,如图1(a);
改进C3D:比二维卷积网络有更多的参数,缺点参数量大,不能imagenet pretrain,从头训难训。Input,16帧 输入112*112,本文实现了C3D的一个变种,在最顶层有8个卷积层,5个pooling层和2个全联接层。模型的输入是16帧,每帧112x112的片段。不同于论文中的实现是,作者在所有的卷积层和全联接层后面加入了BN层,同时将第一个pooling层的temporal stride由1变为2,来减小内存使用,增加batch的大小,这对batch normalization很重要,如图1(b)。
双流网络:由于LSTM只抓住高层的卷积后的信息,底层的信息在某些例子上也非常重要,LSTM train消耗很大。RGB帧和10个堆叠的光流帧,光流输入是2倍的光流帧(x,y水平垂直的channel),可以有效train,如图1(c)。
新双流网络:作者实现使用InceptionV1,后面的融合部分改为3D卷积,3D pooling,最终通过一个全连接层进行分类。网络的输入是相隔10帧采样的5个连续RGB帧,采用端到端的训练方式,如图1(d)。
双流Inflated 3D卷积:扩展2D卷积base model为3D base model卷积,卷积核和pooling增加时间维,尽管3D卷积可以直接学习时间特征,但是将光流加进来后会提高性能。
I3D结构扩展方式:如果2D的滤波器为N*N的,那么3D的则为N*N*N的。具体做法是沿着时间维度重复2D滤波器权重N次,并且通过除以N进行归一化。
从预先训练的ImageNet模型中引导参数来初始化I3D:作者将图像重复复制到视频序列中将图像转换为(boring)视频。然后,在ImageNet上对3D模型进行隐式预训练,满足我们所谓的无聊视频固定点((boring)视频上的池化激活应与原始单个图像输入上的池化激活相同),这可以实现通过在时间维度上重复2D滤波器的权重N次,并且通过除以N来重新缩放它们,这确保了卷积滤波器响应是相同的。

图2. 网络参数和输入配置
I3D时间,空间感受野:对于3D来说,时间维度不能缩减地过快或过慢。如果时间维度的感受野尺寸比空间维度的大,将会合并不同物体的边缘信息。反之,将捕捉不到动态场景。因此改进了BN-Inception的网络结构。在前两个池化层上将时间维度的步长设为了1,空间还是2*2。最后的池化层是2*7*7。训练的时候将每一条视频采样64帧作为一个样本,测试时将全部的视频帧放进去最后average_score。除最后一个卷积层之外,在每一个卷积后面都加上BN和relu,具体如图3。

图3. In flated Inception-V1架构(左)及其详细的初始子模块(右)
I3D双流网络:RGB和光流是分开训练的,测试时将它们预测的结果进行平均,如图1(e)。
上述网络模型的实现细节,除了C3D其他模型使用预训练的Inception-V1作为基网络,除了最后的卷积层之外,对其他卷积层进行了BN操作和ReLU激活。在所有情况下,视频训练使用标准SGD,动量设置为0.9, 作者在Kinetics数据集上训练了110k步的模型,当验证损失饱和时,学习率降低了10倍。在Kinetics的验证集上调整了学习率超参数。模型在UCF-101和HMDB-51上训练模型达5k步,使用相似学习率适应程序。在训练期间,spatial上是先将原始帧resize成256*256的,然后随机剪裁成224*224的。在temporal上,尽量选择前面的帧以保证足够光流帧的数目足够多。短的视频循环输入以保证符合网络的input_size。在训练中还用到了随机的左右翻转。测试的时候选用中心剪裁224*224,将整条视频的所有帧输入进去,之后average_score。实验测试256x256的视频并没有提高,测试时左右翻转video,训练时增加额外的augmentation,如phonemetric,可能有更好的效果。
通过对不同结构模型进行训练和测试。图4显示了在UCF-101,HMDB-51或Kinetics上进行训练和测试时的分类准确度。作者在UCF-101和HMDB-51的split1测试集以及Kinetics的保留测试集进行了评估。有几个值得注意的观察结果。 首先,新I3D模型
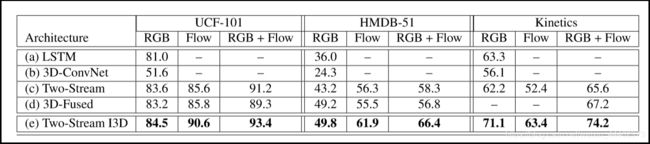
图4. 上面所述不同结构性能比较
在所有数据集中表现最佳,具有RGB,Flow或RGB +Flow。表明预训练的ImageNet扩展到3D ConvNets好处。其次,所有模型在Kinetics的性能远低于UCF-101,这表明两个数据集的不同难度水平。然而高于HMDB-51; 这可能部分是由于HMDB-51中的训练数据少的缘故,但也因为这个数据集故意构建得很难:许多剪辑在完全相同的场景中有不同的动作。作者也评估了从ImageNet预训练或没有进行预训练模型在Kinetics上的表现,结果显示在如图5中。可以看出,在ImageNet预训练是有用的。作者研究了在ImageNet + Kinetics上进行预训练而不仅仅在Kinetics预训练的重要性,如图6,其中Original:在UCF-101或HMDB-51上的训练;Fixed:在Kinetics的预训练之后,仅对模型的最后一层在UCF-101或HMDB-51上训练; Full-FT:在Kinetic上预训练训,之后在UCF-101或HMDB-51上进行端到端的微调,结果显示,所有的架构都受益于在额外视频数据Kinetics的预训练,但有些好处明显多于其他架构 - 尤其是I3D-ConvNet和3D-ConvNet。在Kinetics预训练后,训练模型的最后几层也比直接训练UCF-101和HMDB-51的I3D模型带来更好的性能。
最后作者将其方法和其他模型进行了对比,如图7,但目前这些数据集上表现最好的方法是ST-ResNet+IDT,其中使用了RGB和光流的ResNet-50模型,在UCF-101上得到94.6%,在HMDB- 51上得到70.3%。作者使用三个标准训练/测试splits的作者
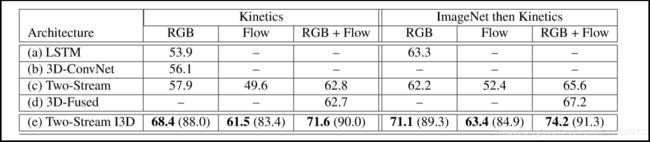
图5. 有和没有ImageNet预训练在Kinetics训练和测试性能
使用三个标准训练/测试splits的平均精度对其方法进行基准测试。当在Kinetics进行预训练时,RGB-I3D或RGB-Flow模型都可以通过任何模型或模型组合优于以前发布的所有模型性能。
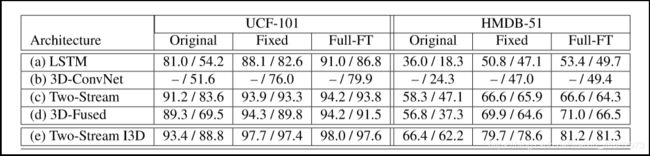
图6. UCF-101和HMDB-51测试集(两者的split1)的性能,适用于以/不使用ImageNet预训练权重开始的体系结构

图7. 与其他模型对比