【深度学习入门】Paddle实现手写数字识别详解(基于DenseNet)
【深度学习入门】Paddle实现手写数字识别(基于DenseNet)
- 0. 闲言碎语:
- 1. MNIST 数据集:
- 2. DenseNet 详解:
- 2.1 ResNet(颠覆性的残差结构):
- 2.2 DenseNet(跨层链接的极致):
- 3. 代码:
0. 闲言碎语:
OK,因为课程需要就来做了一个手写数字(当初就是这个小项目入的坑hahhh),因为必须在百度的 AI Studio 上进行,所以只能用 Paddle,看了一下 Paddle 的文档,结论是:这不就是 tensorflow + torch 的结合体吗hahhh?所以还是比较容易写这个数字识别的 demo的;
这里就分享一个 Baseline 吧~
1. MNIST 数据集:
MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的灰度图,标签为0~9共10个数字。官网:http://yann.lecun.com/exdb/mnist/

2. DenseNet 详解:
其实我以前写过,想看更详细的请移步:残差神经网络ResNet系列网络结构详解:从ResNet到DenseNet,这里就简单复述一下:
2.1 ResNet(颠覆性的残差结构):
说到 DenseNet,就不得不提它的前身 ResNet;
论文地址:《Deep Residual Learning for Image Recognition》
LeNet 和 AlexNet的提出开启了卷积神经网络应用的先河,随后的GoogleNet、VGG等网络使用了更小的卷积核并加大了深度,证明了卷积神经网络在处理图像问题方面具有更加好的性能;
但是随着层数的不断加深,卷积神经网络也暴露出来许多问题:
- 理论上讲,层数越多、模型越复杂,其性能就应该越好;但是实验证明随着层数的不断加深,性能反而有所下降。
- 深度卷积网络往往存在着梯度消失/梯度爆炸的问题;由于梯度反向传播过程中,如果梯度都大于1,则每一层大于1的梯度会不断相乘,使梯度呈指数型增长;同理如果梯度都小于1,梯度则会逐渐趋于零;使得深度卷积网络难以训练。
- 训练深层网络时会出现退化:随着网络深度的增加,准确率达到饱和,然后迅速退化。
而ResNet提出的残差结构,则一定程度上缓解了模型退化和梯度消失问题:
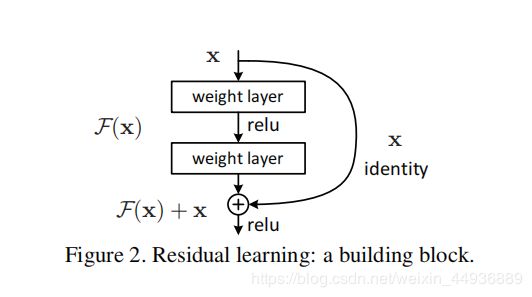
作者提出,在一个结构单元中,如果我们想要学习的映射本来是y=H(x),那么跟学习y=F(x)+x这个映射是等效的;这样就将本来回归的目标函数H(x)转化为F(x)+x,即F(x) = H(x) - x,称之为残差。
于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(x)和x的差值,即去掉映射前后相同的主体部分,从而突出微小的变化,也能够将不同的特征层融合。而且y=F(x)+x在反向传播求导时,x项的导数恒为1这样也解决了梯度消失问题。
用数学表达式表示为:
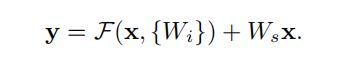
2.2 DenseNet(跨层链接的极致):
论文地址:《Densenet: densely connected convolutional networks》
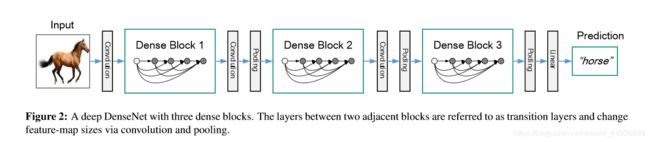
DenseNet 的主要思想是将每一层都与后面的层都紧密(Dense)连接起来,将特征图重复利用,网络更窄,参数更少,对特征层能够更有效地利用和传递,并减轻了梯度消失的问题。
网络结构如图:
其基本的结构单元为:

即在一个DenseNet结构单元中,前面的特征层会与它后面的所有特征层相连,称之为Dense Block,其具体结构为:
X —>(BN+ReLU+3x3 Conv)× 4 —> translation layer;
(BN为batch normalization)
有文章中指出,在每3×3卷积之前可以引入1×1卷积作为瓶颈层,可以减少输入特征映射的数量,从而提高计算效率。
作者就将子单元(BN-ReLU-3x3Conv)改成了bottleneck layer:
(BN+ReLU+1x1Conv—>BN+ReLU-3x3Conv)
并且为了解决前后特征层深度和尺寸不同的问题,作者加入了Translation Layer:
BN+Relu+1x1Conv+Pooling
3. 代码:
代码使用 Paddle(支持国产hahhh)
#导入需要的包
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
numpy 是一个科学计算库,用来做矩阵运算非常快(所以Python里面计算的时候不要用for啦)
paddle 是百度开发的深度学习框架(也没几年,所以不怎么有人用,开源社区做的也不是很好)
PIL 图像处理库(感觉没有opencv-python好用)
matplotlib 一个绘图工具(画一些散点图、折线图之类的)
os 路径和文件管理的库(python默认安装的)
BUF_SIZE=128 # 没仔细查,应该是每次缓存队列中保存数据的个数
BATCH_SIZE=32 # 批次大小
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE) # paddle 给的数据迭代器
test_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.test(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
train_data=paddle.dataset.mnist.train(); # paddle直接给了MNIST的数据,我们直接读取就ok
这一块没什么要注意的,就是 train_reader 是训练集迭代器,test_reader 是测试集迭代器;
# 定义DenseNet
class DenseNet():
def __init__(self, layers, dropout_prob):
self.layers = layers
self.dropout_prob = dropout_prob
def bottleneck_layer(self, input, fliter_num, name):
bn = fluid.layers.batch_norm(input=input, act='relu', name=name + '_bn1')
conv1 = fluid.layers.conv2d(input=bn, num_filters=fliter_num * 4, filter_size=1, name=name + '_conv1')
dropout = fluid.layers.dropout(x=conv1, dropout_prob=self.dropout_prob)
bn = fluid.layers.batch_norm(input=dropout, act='relu', name=name + '_bn2')
conv2 = fluid.layers.conv2d(input=bn, num_filters=fliter_num, filter_size=3, padding=1, name=name + '_conv2')
dropout = fluid.layers.dropout(x=conv2, dropout_prob=self.dropout_prob)
return dropout
def dense_block(self, input, block_num, fliter_num, name):
layers = []
layers.append(input)#拼接到列表
x = self.bottleneck_layer(input, fliter_num, name=name + '_bottle_' + str(0))
layers.append(x)
for i in range(block_num - 1):
x = paddle.fluid.layers.concat(layers, axis=1)
x = self.bottleneck_layer(x, fliter_num, name=name + '_bottle_' + str(i + 1))
layers.append(x)
return paddle.fluid.layers.concat(layers, axis=1)
def transition_layer(self, input, fliter_num, name):
bn = fluid.layers.batch_norm(input=input, act='relu', name=name + '_bn1')
conv1 = fluid.layers.conv2d(input=bn, num_filters=fliter_num, filter_size=1, name=name + '_conv1')
dropout = fluid.layers.dropout(x=conv1, dropout_prob=self.dropout_prob)
return fluid.layers.pool2d(input=dropout, pool_size=2, pool_type='avg', pool_stride=2)
def net(self, input, class_dim=1000):
layer_count_dict = {
121: (32, [3, 3, 6])
}
layer_conf = layer_count_dict[self.layers]
conv = fluid.layers.conv2d(input=input, num_filters=layer_conf[0] * 2,
filter_size=3, name='densenet_conv0')
conv = fluid.layers.pool2d(input=conv, pool_size=2, pool_padding=1, pool_type='max', pool_stride=2)
for i in range(len(layer_conf[1]) - 1):
conv = self.dense_block(conv, layer_conf[1][i], layer_conf[0], 'dense_' + str(i))
conv = self.transition_layer(conv, layer_conf[0], name='trans_' + str(i))
conv = self.dense_block(conv, layer_conf[1][-1], layer_conf[0], 'dense_' + str(len(layer_conf[1])))
conv = fluid.layers.pool2d(input=conv, global_pooling=True, pool_type='avg')
out = fluid.layers.fc(conv, class_dim, act='softmax')
return out
这当然不是我写的啦,,,网上找的轮子,其实一般来说图像识别这边不需要自己造轮子的,这个任务还比较简单,如果你想去写一个语义分割、目标检测的话,自己造轮子不仅浪费时间,而且命名空间会很麻烦,网上的预训练模型可能用不了;
总之这里定义个一个 DenseNet 类,并且把原来的 121 层改成了 9 层(毕竟这个任务相比 ImageNet 的 1000 分类+224 大小图像来说比较简单,太复杂很容易过拟合并且训练满),通过 .net() 方法输出预测;
# 定义输入输出层
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')#单通道,28*28像素值
label = fluid.layers.data(name='label', shape=[1], dtype='int64') # 图片标签
# 获取分类器
model = DenseNet(121, 0.5)
out = model.net(input=image, class_dim=10)
# 获取损失函数和准确率函数
cost = fluid.layers.cross_entropy(input=out, label=label) #使用交叉熵损失函数,描述真实样本标签和预测概率之间的差值
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=out, label=label) # 定义准确率
这里也没啥好说的,都有注释;
唯一要注意的一点是,Paddle 里面的 fluid.layers.cross_entropy 中 label 不需要改成跟预测一样的向量形式,跟 TF 的 tf.nn.sparse_softmax_cross_entropy_with_logits() 类似;
# 定义优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-2) #使用Adam算法进行优化
opts = optimizer.minimize(avg_cost)
# 定义一个使用CPU的解析器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
这里跟那个 TF 是一模一样了,定义了一个 Adam 优化器,然后配置了训练使用 CPU;
feeder 就是传入数据的一个东东;
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
然后写了几个列表变量,保存训练的结果;
定义了 draw_train_process 函数,用来画 loss 跟 acc 的折线图;
EPOCH_NUM=20 # 调参 训练轮数
model_save_dir = "/home/aistudio/data/hand.inference.model"
for pass_id in range(EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()): #遍历train_reader
train_cost, train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #给模型喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
all_train_iter=all_train_iter+1
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
# 每100个batch打印一次信息 误差、准确率
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
#每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()): #遍历test_reader
test_cost, test_acc = exe.run(program=fluid.default_main_program(), #执行训练程序
feed=feeder.feed(data), #喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
test_accs.append(test_acc[0]) #每个batch的准确率
test_costs.append(test_cost[0]) #每个batch的误差
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs)) #每轮的平均误差
test_acc = (sum(test_accs) / len(test_accs)) #每轮的平均准确率
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print ('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, #保存推理model的路径
['image'], #推理(inference)需要 feed 的数据
[out], #保存推理(inference)结果的 Variables
exe) #executor 保存 inference model
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
这里运行就可以开始开心地:训练-测试-训练-测试,,,,,

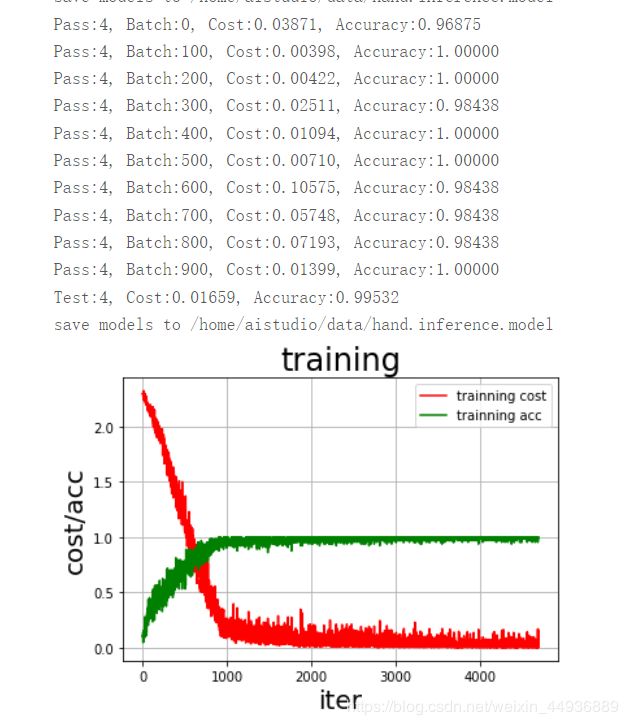
呼…只用 CPU 还真是慢啊,,,
大概最后 99.532% 的准确率(其实简单的 2 ~ 3 层的卷积网络也能达到这个水平,,,就当科普一下 DenseNet 喽);
def load_image(file):
im = Image.open(file).convert('L') #将RGB转化为灰度图像,L代表灰度图像,像素值在0~255之间
im = im.resize((28, 28), Image.ANTIALIAS) #resize image with high-quality 图像大小为28*28
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)#返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。
#print(im)
im = im / 255.0 * 2.0 - 1.0 #归一化到【-1~1】之间
return im
def load_image_cv(path):
im = cv2.imread(path, 0)
im = cv2.resize(im, (28, 28)).astype(np.float)
im = im / 255.0 * 2.0 - 1.0
return im
这里定义一下加载图片的函数(我顺便再写一个cv2的吧,是不是更简洁呀哈哈);
infer_path='/home/aistudio/work/data5435/infer_9.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
infer_exe = fluid.Executor(place)
#声明一个新的作用域
inference_scope = fluid.core.Scope()
然后读取一下用来测试的那张图片(路径可以改成你自己的),并声明一个新的作用域用来测试(感觉跟Session一样的东西);
#运行时中的所有变量都将分配给新的scope
with fluid.scope_guard(inference_scope):
#获取训练好的模型
#从指定目录中加载模型
[inference_program, #推理Program
feed_target_names, #是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个列表,从中我们可以得到推断结果。model_save_dir:模型保存的路径
infer_exe) #infer_exe: 运行 inference model的 executor
infer_path='/home/aistudio/work/data5286/infer_3.png'
img = load_image(infer_path)
results = infer_exe.run(program=inference_program, #运行推测程序
feed={feed_target_names[0]: img}, #喂入要预测的img
fetch_list=fetch_targets) #得到推测结果,
# 获取概率最大的label
print(results)
lab = np.argsort(results) #argsort函数返回的是result数组值从小到大的索引值
print(lab)
print("该图片的预测结果的label为: %d" % lab[0][0][-1]) #-1代表读取数组中倒数第一列
img = Image.open(infer_path)
plt.title('pred:'+str(lab[0][0][-1]))
plt.imshow(img)
plt.title()
ok 测试完毕~

最后欢迎关注我的个人博客哦:https://blog.csdn.net/weixin_44936889
