eclipse远程连接Hadoop
关于Hadoop环境搭建可参照本人之前写的文章:Centosmini配置hadoop2.7.3
废话不多说,直接上干货。
前期准备:
hadoop-2.7.3.tar.gz (因为linux上配置的hadoop版本就2.7.3,所以图方便就继续用了)
hadoop-eclipse-plugin.zip (hadoop2.7.3插件压缩包,里面有后面需要用到的wintils.exe和hadoop.dll)
1.JDK环境配置
关于JDK的安装不懂的童鞋可以自行百度下哦,关于32位、64位一定要对号入座,不然出了问题就蒙圈了。这个就不多说了。。。
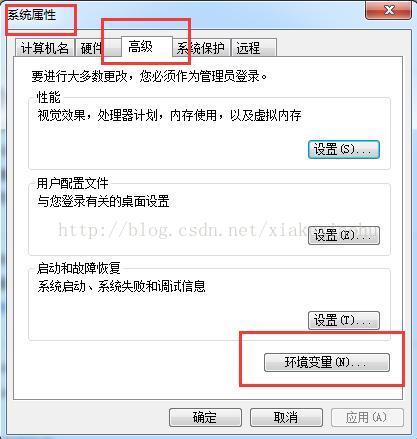
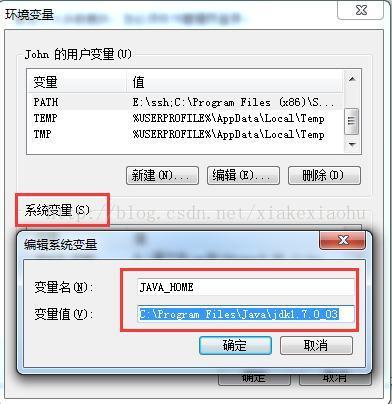
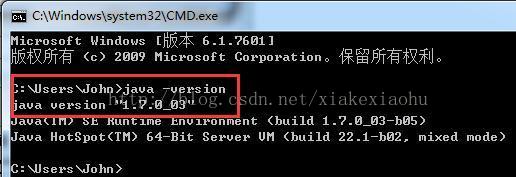
如果出现以下截图,说明你的JDK配置成功。
1.1Eclipse安装
假设你的电脑已经顺利安装了eclipse,此步忽略。
1.2在Eclipse安装hadoop插件
前面我用的是hadoop-2.7.3版本,所以接下来用的就是2.7.3的插件,上面有提到。
1.2.1插件安装
把文件解压,将hadoop-eclipse-plugin-2.7.3.jar复制到你的java安装目录下的plugins目录下

1.2.2重启eclipse
1.3配置hadoop安装路径
如果插件安装成功,打开eclipse->windows->preferences,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径(这个是指在window环境下将hadoop安装包解压文件的路径,并不是真的安装,我解压在D:\hadoop目录下)。
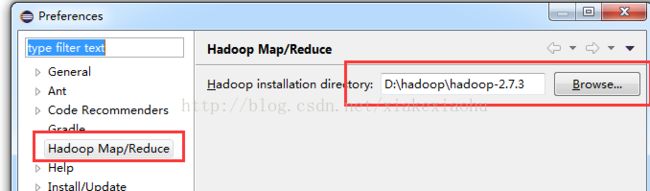
最后,将上面提到的hadoop-eclipse-plugin-2.7.3插件解压包bin目录下的winutils.exe和hadoop.dll两个文件放到hadoop安装目录的bin目录下,与此同时将这两个文件复制到c:\windowsSystem32目录下。
1.4配置Map/Reduce Locations
打开eclipsse->windows->show view->other
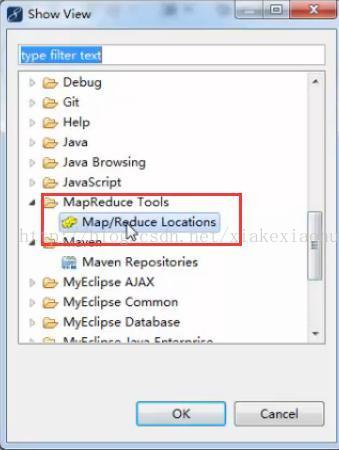
选择Map/Reduce,单击OK。
在右下方看到如图所示:
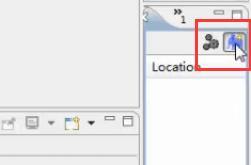
点击Map/Reduce Location选项卡,点击右边的小象图标打开Hadoop Location配置窗口:
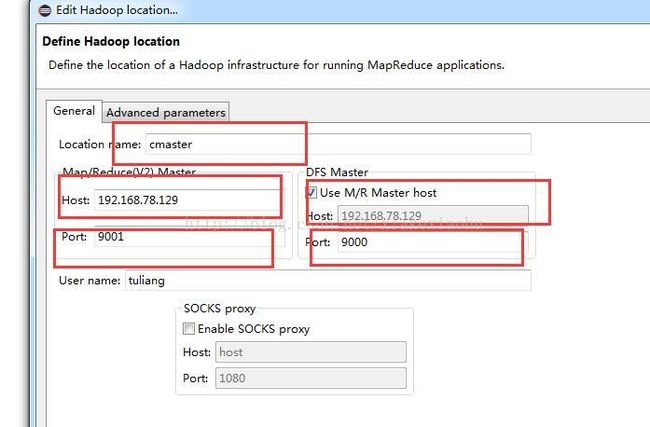
其中,Location name 随便填写,仅是标示符。配置Map/Reduce Master和DFS Master的Host和Port应该与linux环境下hadoop配置的core-site.xml一致。
如果Host你不填写具体IP的话,那么就需要在windows下,以管理员身份打开C:\WindowsSystem32\driver\hosts\etc,添加你linux虚拟机中namenode和datanode的主机名和ip,如下图:

之后回到eclipse来,点击左侧的DFS Locations->cmaster(前提是你配置是跟着我来的),如果连接成功,在project explorer的DFS Locations下会展开hdfs集群中的文件:

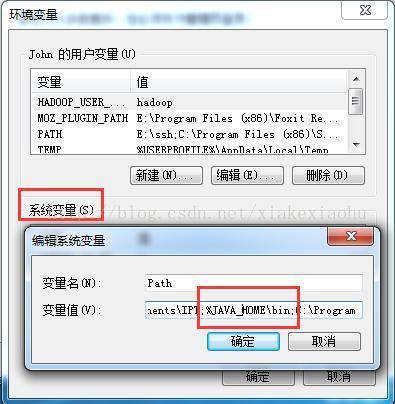
1.5Hadoop环境配置
在windows下,配置hadoop环境变量
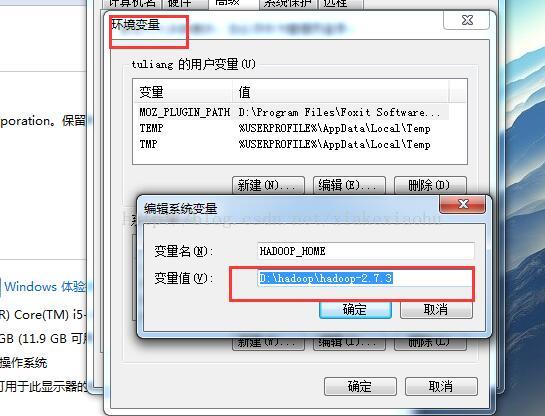
在环境变量中找到path这一项,编辑:
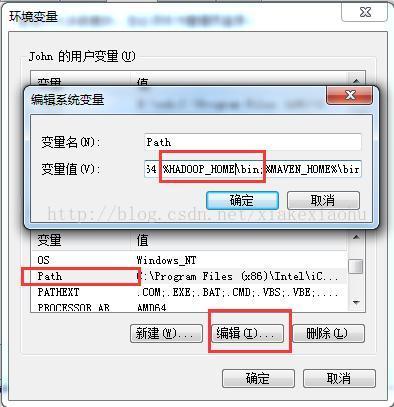
1.6构建Map/Reduce项目
我们可以通过以下几个步骤来简单的开发MapReduce程序
1.首先打开eclipse,选择File->New->Othe,之后出现下面截图:
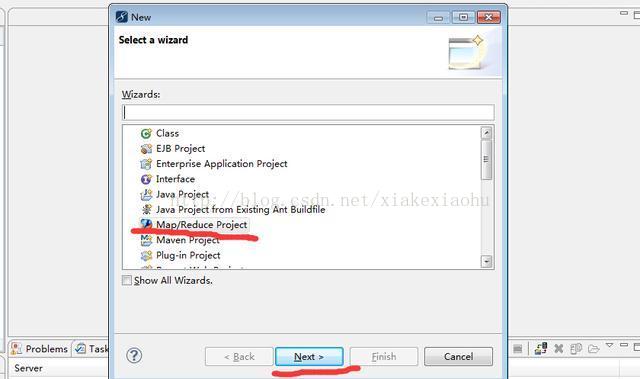
2、选中Map/Reduce Project,点击下一步出现如下界面:
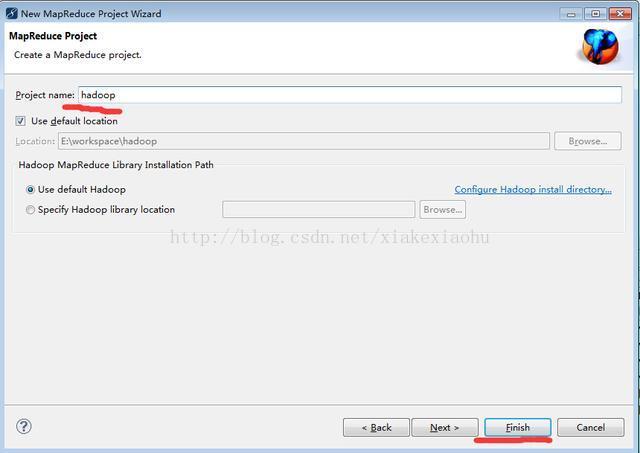
3、在Project name后面输入项目名称如hadoop,点击Finish完成Map/Reduce项目的创建

作为初学者,个人建议将Hadoop安装目录下的lib中的所有jar都导入到项目中。
4、在src目录下创建一个包名比如com.hadoop.test,然后编写一个MapReduce示例程序WordCount:
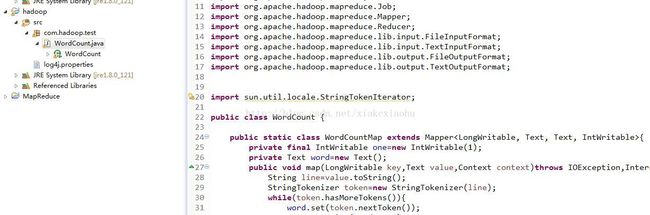
这里我们需要下载log4j.properties文件放到src目录下,这样程序运行时我们可以打印日志,便于调试程序。
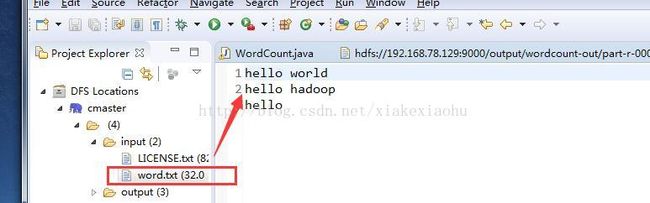
5、将自己创建的word.txt文件上传到HDFS文件系统input目录。
关于hadoop中文件上传的方式有两种:
(1).在Hadoop集群下创建一个word.txt文件,然后通过命令行的方式将该文件上传到HDFS的input目录中;$ hadoop fs -put File_Name Storage_Directory
(2).当然咱是为了在eclipse远程操作hadoop,肯定要用这种简单的方法了。在windows下创建word.txt文件,通过Eclipse链接HDFS,然后鼠标右键选中cmaster下的input目录弹出的:Upload files to HDFS,然后选中本地的word.txt文件上传至/input目录下。
ps:如果上传失败,可能是因为权限不够,在linux下面输入命令:hadoop fs -chmod 777 \input(后面Run失败也可能是因为输出目录的权限不够,也可以参照该方法解决)

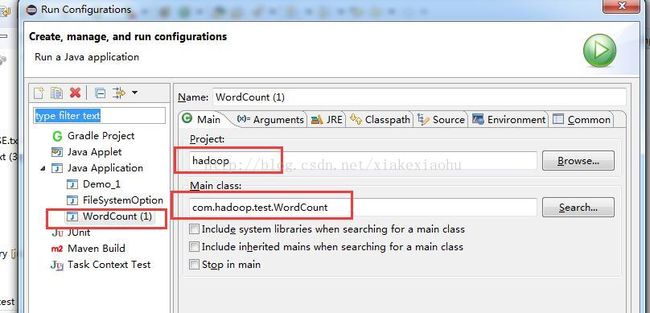
6、右键点击Eclipse中的wordcount程序(源码在文章最末尾贴出来),选择Run as->Run Configurations
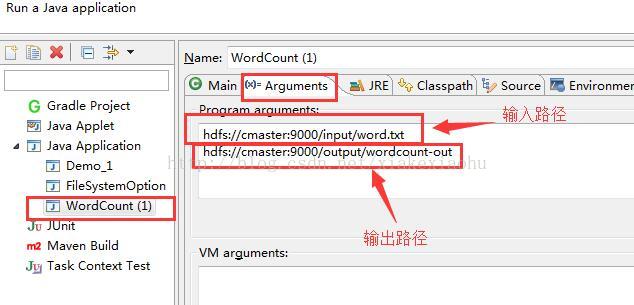
最后点击Run即可,可以看到左侧DFS Locations目录下的\output\word-count-out中会出现结果:
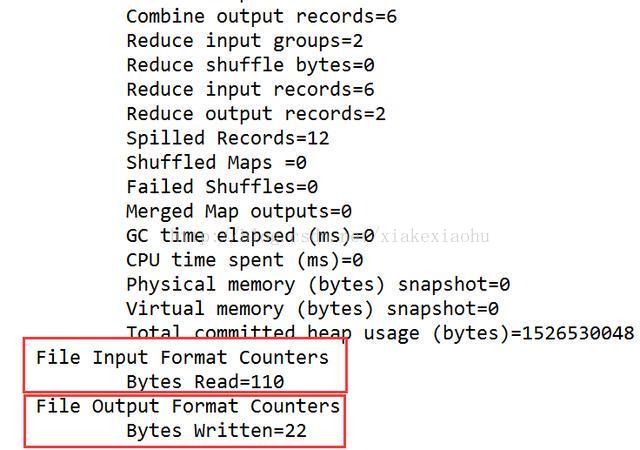

ps:
如果上面的Wordcount程序能正常运行,那么我们后面开发运行MapReduce程序就轻松多了。 当然大家的Eclipse不使用hadoop插件也可以,MapReduce程序可以读取本地文件直接运行。Hadoop插件只不过是方便我们查看在hdfs上面的运行结果。
常见错误及解决办法
1.错误:java.io.IOException: Could not locate executable nullbinwinutils.exe in the Hadoop binaries.
错误原因:未正确配置环境变量
解决办法:配置环境变量HADOOP_HOME为D:hadoop-2.2.0,另在Path变量后添加;%HADOOP_HOME%bin
2.错误:Could not locate executable D:hadoop-2.2.0binwinutils.exe in the Hadoop binaries.
错误原因:本地Hadoop运行目录的bin目录下中没有winutils.exe或者32位/64位版本不匹配
解决办法:下载相应的winutils.exe和hadoop.dll放到Hadoop运行目录的bin文件夹下,注意选择正确的32位/64位版本
3.错误:Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
错误原因:本地Hadoop运行目录的bin目录下中没有hadoop.dll或者32位/64位版本不匹配
解决办法:下载相应的hadoop.dll放到Hadoop运行目录的bin文件夹下,注意选择正确的32位/64位版本
4.错误:DEBUG org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: HADOOP_HOMEbinhadoop.dll: Can't load AMD 64-bit .dll on a IA 32-bit platform
错误原因:本地Hadoop运行目录的bin目录下中没有hadoop.dll版本不匹配,有32位和64位版
解决办法:下载正确的32位/64位版本的hadoop.dll放到Hadoop运行目录的bin文件夹下
5.错误:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
解决办法:其实这个错误的原因很容易看出来,用户在hadoop上执行写操作时被权限系统拒绝。有以下几种解决办法,可以分别试一试。
1)在系统的环境变量里面,添加一个的用户变量:HADOOP_USER_NAME,它的值为HADOOP环境下的用户名,比如hadoop(修改完重启eclipse,不然可能不生效)
2)将当前Windows系统的登录帐号修改为hadoop环境下的用户名,比如hadoop。
3)使用HDFS的命令行接口修改相应目录的权限: 比如要上传的文件路径为hdfs://djt002:9000/user/xxx.txt,则使用hadoop fs -chmod 777 /user 修改权限。 如果要上传的文件路径为hdfs://djt002:9000/java/xxx.txt,则要使用hadoop fs -chmod 777 /java或者hadoop fs -chmod 777 / 修改权限,此时需要先在HDFS里面建立Java目录。
4)关闭hadoop环境下的防火墙。
6.错误:Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
解决办法 :下载正确的32位/64位版本的hadoop.dll和winutils.exe拷贝到C:WindowsSystem32目录下即可。
1.7 如果还有问题怎么办?
我们可以通过以下步骤来排查:
1)首先确保Windows下,系统位数、jdk位数、hadoop安装包位数保持一致,否则肯定会报错。 比如,64位的Windows系统,需要安装64位的jdk以及下载64位的hadoop安装包(课程中有下载)。
如果不知道hadoop位数是否正确,可以双击下面的文件。
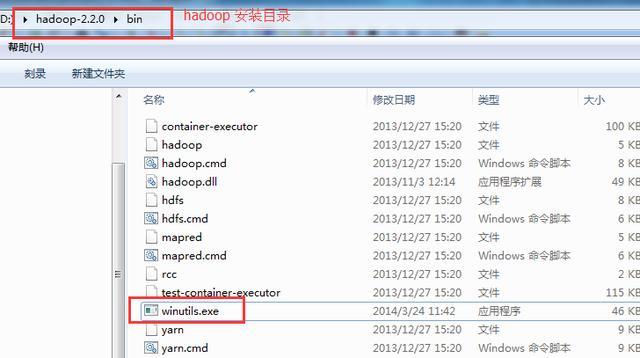
如果不出错,说明文件没有问题。如果hadoop的bin目录下没有hadoop.dll、winutils.exe这两个文件,在课程中下载。
2)确保jdk以及hadoop的环境变量配置正确(前面已经讲解)
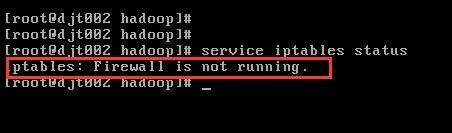
3)确保Linux下的防火墙已经关闭。
4)如果出现Eclipse访问不了hdfs,可以按照上面第5个问题的解决办法。
5)检查C:WindowsSystem32目录下是否存在hadoop.dll和winutils.exe文件。
6)如果以上方法还是有错误,可能是系统或者Eclipse版本的原因造成的,最糟糕的情况可能需要换一个干净的Windows系统了。
好了,是不是已经搞定了,那就让我们一起Hadoop吧!
2.WordCount源码
package com.hadoop.test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import sun.util.locale.StringTokenIterator;
public class WordCount {
public static class WordCountMap extends Mapper{
private final IntWritable one=new IntWritable(1);
private Text word=new Text();
public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
String line=value.toString();
StringTokenizer token=new StringTokenizer(line);
while(token.hasMoreTokens()){
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends Reducer{
public void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
Job job=new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}