关于点击下载文件的那些事
前言
通过点击下载部署在服务器上的文件,是B端的一个常见需求,但是为了获得良好的体验,其中还是有很多值得钻研的小知识点。笔者最近在开发个人云盘,在开发文件下载功能的过程中也接触到了这一领域(完成后也会发一篇博文,这里先占个坑)。网上有各种各样的实现,不过也有各种各样的问题,比如跨域下载不支持,需要另开浏览器tab或者图片等浏览器可以识别的内容直接打开等等影响体验的细节,这里就摊开讲讲。
常见方法
a标签内置下载
实现非常简单:
<a href='下载文件的url'>点我下载a>
相信这也是大多数人第一个想到的方法,通常情况下体验十分完美,但是如果遇到下载图片,pdf,txt等等浏览器能够直接解析出来并展示的文件,就会出现如下的结果:

浏览器发现该资源可以解析后,会直接跳转到下载资源的url并在窗口展示。这个体验想必是大多数人不能接受的,为此我们可以添加download参数,告诉浏览器我们想要的是下载这个资源,类似这样:
<a href='下载文件的url' download>点我下载a>
通过download还可以修改文件下载后的名字和类型:
<a href='下载文件的url' download='文件名.后缀名'>点我下载a>
如果不要求修改文件的类型,后缀名可以省略:
<a href='下载文件的url' download='文件名'>点我下载a>
download属性就是银弹吗?很遗憾让你失望了,亲测在chrome下,如果资源不是同源的,download属性是无效的,加与不加一个样,如果要解决这个问题,只有通过后端进行配合了。关于该属性的兼容性内容,有张鑫旭大神的总结贴了解HTML/HTML5中的download属性可以参考,这里不赘述。
window.open开启新tab下载
该方法通过winodw.open打开新的tab,利用浏览器无法解析的资源会变成下载的特性来实现功能,api也不复杂:
window.open('目标url')
我们看看在普通文件下的表现:

大家可以明显看到,这里有开一个tab的过程。浏览器发现该资源无法解析,浏览器会关闭该tab,走下载流程
大家肯定比较关心针对图片的表现,很遗憾跟a标签的下载一样不尽如人意:

针对浏览器可以直接解析出来的内容,浏览器会开启tab并显示内容。
通过提交表单
原理上是通过构造表单,通过submit方法向服务器请求资源:
export function downloadUrlFile(url) {
let tempForm = document.createElement('form')
tempForm.action = url
tempForm.method = 'get'
tempForm.style.display = 'none'
document.body.appendChild(tempForm)
tempForm.submit()
return tempForm
}
给form表单设置get方法,然后根据传入的url向服务器请求资源,按照先前的流程,我们看看正常文件的体验:

体验良好,也没有tab的闪动。接下来我们看看针对图片的体验:

很遗憾,针对图片等文件还是会打开tab直接展示内容。
全村的希望:download.js
这是国外一个大佬写的专门针对文件下载的脚本,功能非常丰富,不仅可以下载服务器上的内容,还可以针对base64等dataUrl形式的文件进行下载,使用方法非常丰富,此处是传送门download.js官方文档,这里贴上源码和笔者的简单注释(注意这里是html内嵌脚本的形式展现的,如有需要可以单独抠出来搞成一个模块供外部引用):
<script>//download.js v4.2, by dandavis; 2008-2016. [CCBY2] see http://danml.com/download.html for tests/usage
// v1 landed a FF+Chrome compat way of downloading strings to local un-named files, upgraded to use a hidden frame and optional mime
// v2 added named files via a[download], msSaveBlob, IE (10+) support, and window.URL support for larger+faster saves than dataURLs
// v3 added dataURL and Blob Input, bind-toggle arity, and legacy dataURL fallback was improved with force-download mime and base64 support. 3.1 improved safari handling.
// v4 adds AMD/UMD, commonJS, and plain browser support
// v4.1 adds url download capability via solo URL argument (same domain/CORS only)
// v4.2 adds semantic variable names, long (over 2MB) dataURL support, and hidden by default temp anchors
// https://github.com/rndme/download
(function (root, factory) {
// 兼容各种模块写法,在全局对象上挂载download方法
if (typeof define === 'function' && define.amd) {
// AMD. Register as an anonymous module.
// 针对AMD规范,注册一个匿名模块
define([], factory);
} else if (typeof exports === 'object') {
// 针对Node,环境,不支持严格模式
// Node. Does not work with strict CommonJS, but
// only CommonJS-like environments that support module.exports,
// like Node.
module.exports = factory();
} else {
// 浏览器全局变量支持
// Browser globals (root is window)
root.download = factory();
}
}(this, function () {
// 第一个参数是数据,第二个参数是文件名,第三个参数是mime类型
// 下载服务器上的文件直接第一个参数传入url即可,后两个不用传
return function download(data, strFileName, strMimeType) {
// 这里的脚本仅支持客户端
var self = window, // this script is only for browsers anyway...
// 默认的mime类型
defaultMime = "application/octet-stream", // this default mime also triggers iframe downloads
mimeType = strMimeType || defaultMime,
payload = data,
// 如果只传入第一个参数,则把其解析为下载url
url = !strFileName && !strMimeType && payload,
// 创建a标签,方便下载
anchor = document.createElement("a"),
toString = function(a){return String(a);},
// 根据浏览器兼容性,提取Blob
myBlob = (self.Blob || self.MozBlob || self.WebKitBlob || toString),
fileName = strFileName || "download",
blob,
reader;
myBlob= myBlob.call ? myBlob.bind(self) : Blob ;
// 调换参数的顺序,允许download.bind(true, "text/xml", "export.xml")这种写法
if(String(this)==="true"){ //reverse arguments, allowing download.bind(true, "text/xml", "export.xml") to act as a callback
payload=[payload, mimeType];
mimeType=payload[0];
payload=payload[1];
}
// 根据传入的url这一个参数下载文件(必须是同源的,因为走的是XMLHttpRequest)
if(url && url.length< 2048){ // if no filename and no mime, assume a url was passed as the only argument
// 解析出文件名
fileName = url.split("/").pop().split("?")[0];
// 设置a标签的href
anchor.href = url; // assign href prop to temp anchor
// 避免链接不可用
if(anchor.href.indexOf(url) !== -1){ // if the browser determines that it's a potentially valid url path:
// 构造一个XMLHttpRequest请求
var ajax=new XMLHttpRequest();
// 设置get方法
ajax.open( "GET", url, true);
// 设置响应类型为blob,避免浏览器直接解析出来并展示
ajax.responseType = 'blob';
// 设置回调
ajax.onload= function(e){
// 再次调用自身,相当于递归,把xhr返回的blob数据生成对应的文件
download(e.target.response, fileName, defaultMime);
};
// 发送ajax请求
setTimeout(function(){ ajax.send();}, 0); // allows setting custom ajax headers using the return:
return ajax;
} // end if valid url?
} // end if url?
//go ahead and download dataURLs right away
// 如果是dataUrl,则生成文件
if(/^data\:[\w+\-]+\/[\w+\-]+[,;]/.test(payload)){
// 如果满足条件(大于2m,且myBlob !== toString),直接通过dataUrlToBlob生成文件
if(payload.length > (1024*1024*1.999) && myBlob !== toString ){
payload=dataUrlToBlob(payload);
mimeType=payload.type || defaultMime;
}else{
// 如果是ie,走navigator.msSaveBlob
return navigator.msSaveBlob ? // IE10 can't do a[download], only Blobs:
navigator.msSaveBlob(dataUrlToBlob(payload), fileName) :
// 否则走saver方法
saver(payload) ; // everyone else can save dataURLs un-processed
}
}//end if dataURL passed?
blob = payload instanceof myBlob ?
payload :
new myBlob([payload], {type: mimeType}) ;
// 根据传入的dataurl,通过myBlob生成文件
function dataUrlToBlob(strUrl) {
var parts= strUrl.split(/[:;,]/),
type= parts[1],
decoder= parts[2] == "base64" ? atob : decodeURIComponent,
binData= decoder( parts.pop() ),
mx= binData.length,
i= 0,
uiArr= new Uint8Array(mx);
for(i;i<mx;++i) uiArr[i]= binData.charCodeAt(i);
return new myBlob([uiArr], {type: type});
}
// winMode 是否是在window上调用
function saver(url, winMode){
// 如果支持download标签,通过a标签的download来下载
if ('download' in anchor) { //html5 A[download]
anchor.href = url;
anchor.setAttribute("download", fileName);
anchor.className = "download-js-link";
anchor.innerHTML = "downloading...";
anchor.style.display = "none";
document.body.appendChild(anchor);
setTimeout(function() {
// 模拟点击下载
anchor.click();
document.body.removeChild(anchor);
// 如果在window下,还需要解除url跟文件的链接
if(winMode===true){setTimeout(function(){ self.URL.revokeObjectURL(anchor.href);}, 250 );}
}, 66);
return true;
}
// handle non-a[download] safari as best we can:
// 针对不支持download的safari浏览器,走window.open的降级操作,优化体验
if(/(Version)\/(\d+)\.(\d+)(?:\.(\d+))?.*Safari\//.test(navigator.userAgent)) {
url=url.replace(/^data:([\w\/\-\+]+)/, defaultMime);
if(!window.open(url)){ // popup blocked, offer direct download:
if(confirm("Displaying New Document\n\nUse Save As... to download, then click back to return to this page.")){ location.href=url; }
}
return true;
}
//do iframe dataURL download (old ch+FF):
// 针对老的chrome或者firefox浏览器,创建iframe,通过设置iframe的url来达成下载的目的
var f = document.createElement("iframe");
document.body.appendChild(f);
if(!winMode){ // force a mime that will download:
url="data:"+url.replace(/^data:([\w\/\-\+]+)/, defaultMime);
}
f.src=url;
// 移除工具节点
setTimeout(function(){ document.body.removeChild(f); }, 333);
}//end saver
// 针对ie10+ 走浏览器自带的msSaveBlob
if (navigator.msSaveBlob) { // IE10+ : (has Blob, but not a[download] or URL)
return navigator.msSaveBlob(blob, fileName);
}
// 如果全局对象下支持URL方法
if(self.URL){ // simple fast and modern way using Blob and URL:
// 根据blob创建指向文件的ObjectURL
saver(self.URL.createObjectURL(blob), true);
}else{
// handle non-Blob()+non-URL browsers:
// 针对不支持Blob和URL的浏览器,通过给saver传入dataUrl来保存文件
if(typeof blob === "string" || blob.constructor===toString ){
try{
return saver( "data:" + mimeType + ";base64," + self.btoa(blob) );
}catch(y){
return saver( "data:" + mimeType + "," + encodeURIComponent(blob) );
}
}
// Blob but not URL support:
// 支持Blob但是不支持URL方法的浏览器,通过构造文件阅读器来保存文件
reader=new FileReader();
reader.onload=function(e){
saver(this.result);
};
reader.readAsDataURL(blob);
}
return true;
}; /* end download() */
}));script>
通过分析源码我们可以发现,download.js是之前提到的那些方法的集大成者。为了解决最为让人头大的图片自动打开的问题,脚本内通过创建xhr请求,把响应类型改成blob,让浏览器无法识别从而避免直接打开,之后再把下载的到的blob文件重新拼装成我们需要的文件。针对不同浏览器的兼容性,使用了a标签下载,window.open等方法作为降级方案。我们先体验下这瓶万金油:

下载图片体验如丝般顺滑。但是问题还没完,注意官方的这句话:
// v4.1 adds url download capability via solo URL argument (same domain/CORS only)
啥意思呢?传入url作为参数时,只支持同源的资源或者服务器配置了CORS支持跨域(因为使用了xhr请求)。实测验证下:
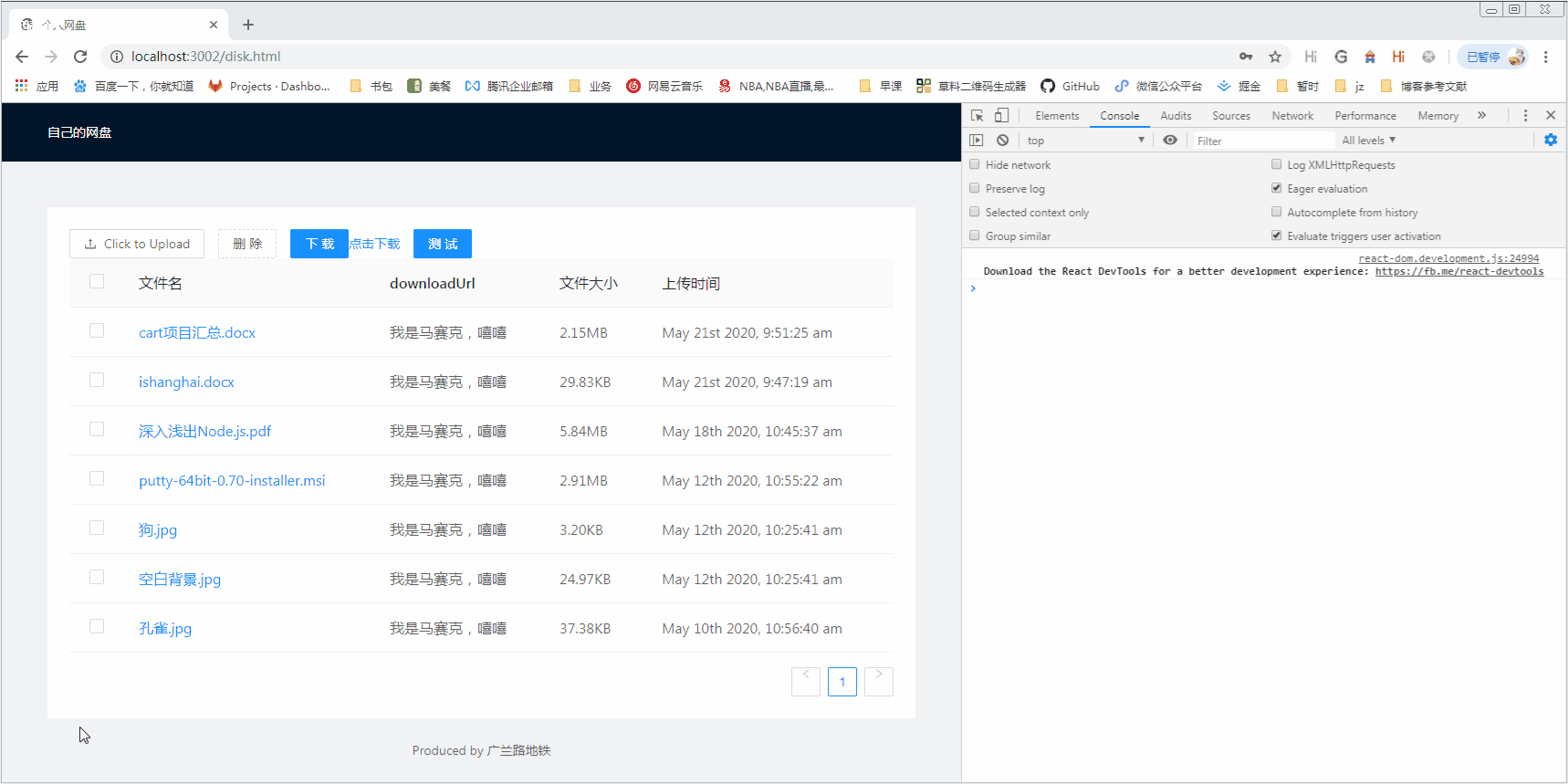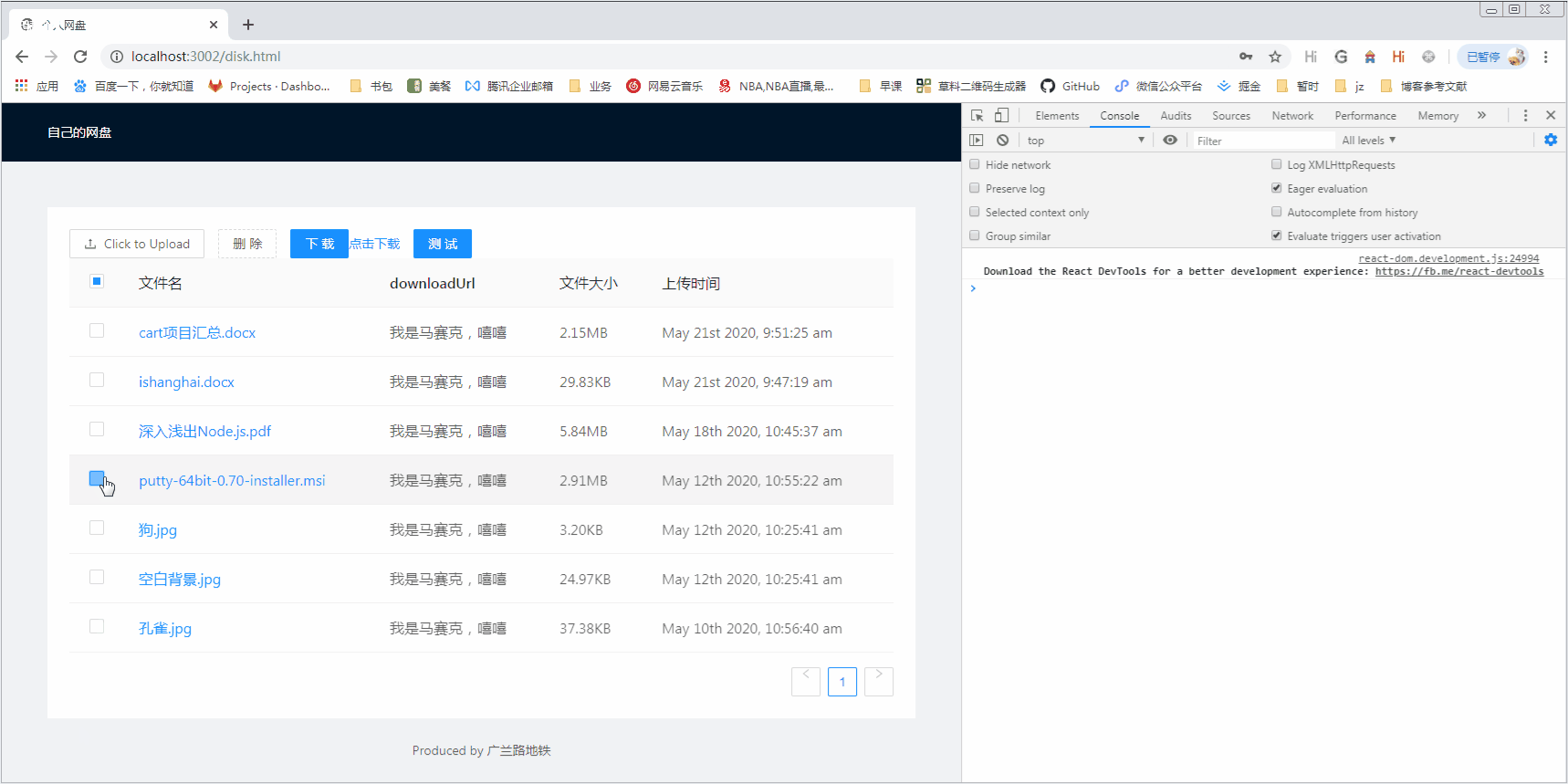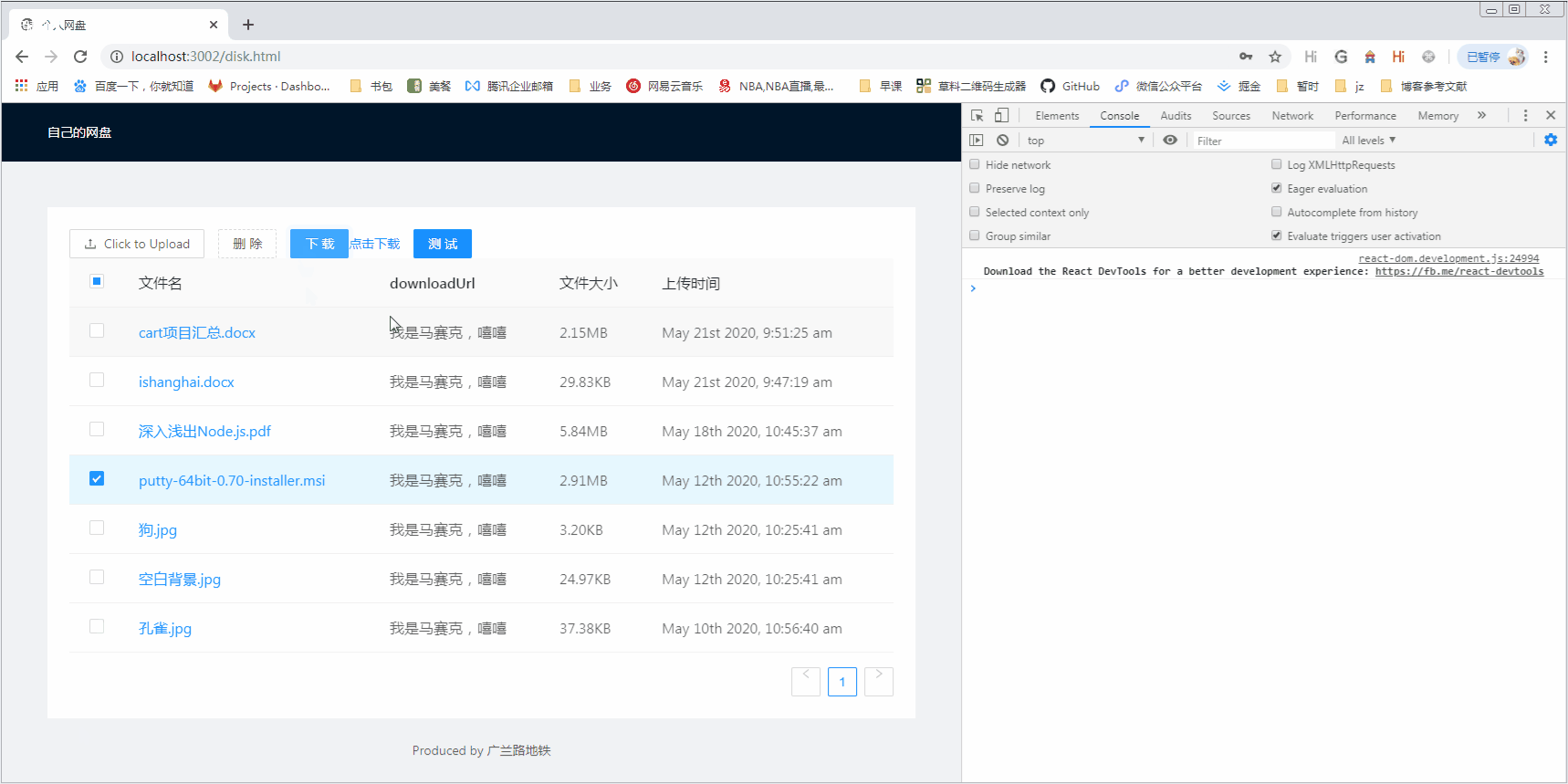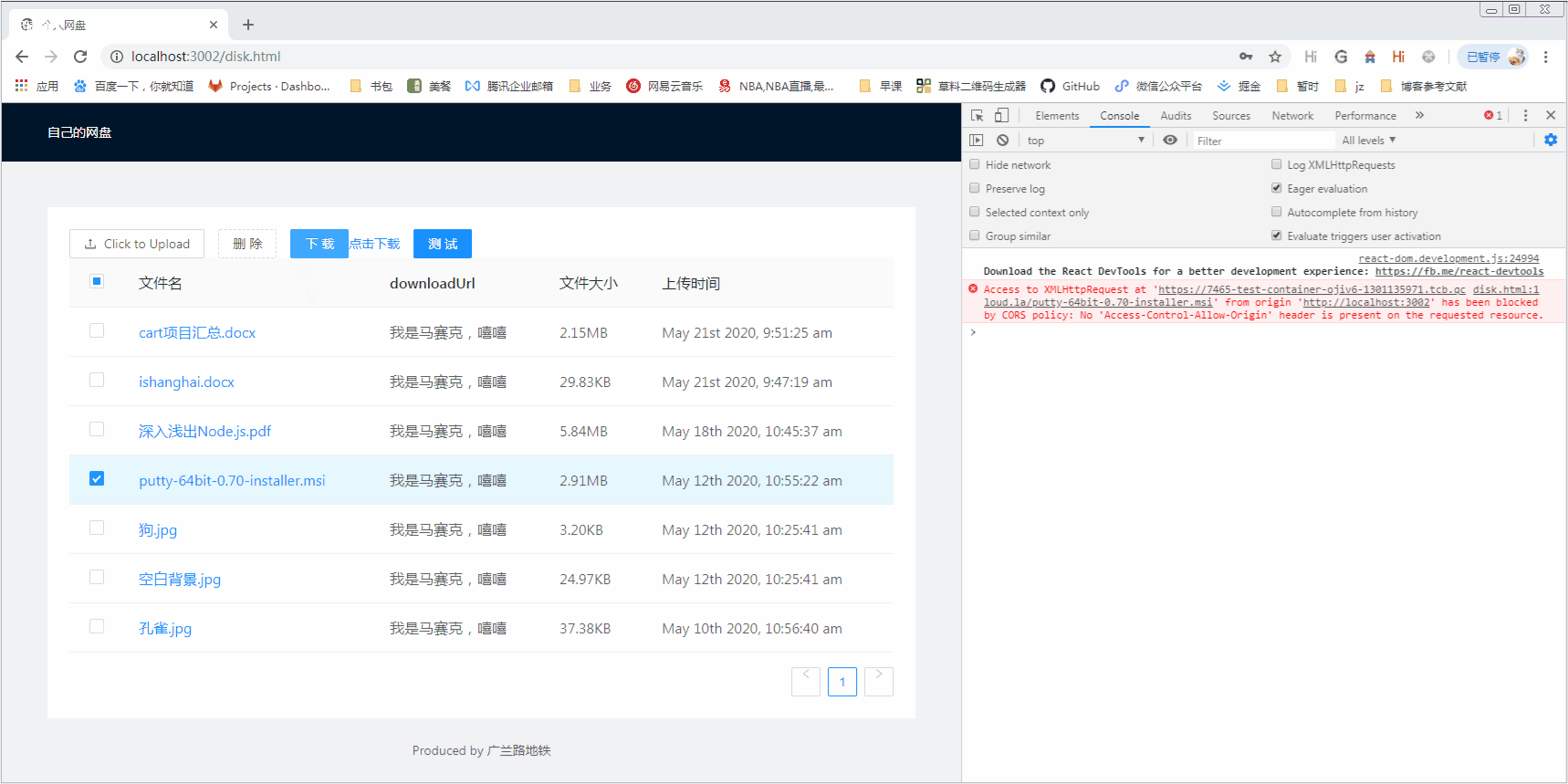
结果浏览器报跨域错误(这里解释下,笔者把一个msi文件上传到小程序云存储上,获取的下载链接。鹅厂针对msi,exe等比较敏感的文件设置了不同的跨域规则,导致这部分文件下载时会被拦截),针对这种情况,使用构造表单提交等方法可以获得完美的体验,不受跨域限制。
总结
比较了以上几种浏览器端文件下载方法之后,我们发现a标签下载体验最好,针对图片等资源,同源的情况下使用download属性可以获取比较好的效果,window.open则会打开新的tab,画面有跳跃。使用构造表单提交除了针对浏览器可以直接解析的文件体验不佳之外,没啥弊端,以上三种方法都不受跨域限制(这里的限制是说可以下载跨域资源,不考虑体验)。download.js除了在下载跨域资源时会报跨域error外,基本没有硬伤,结合之前的任意一种方法,可以组装出一个比较完美的解决方案。这里给一个笔者项目中的例子:
async function downloadFile() {
fileList.filter(item => chekcList.findIndex(sitem => item._id === sitem) >= 0)
.map(item => item.downloadUrl).map(item => {
// download是download.js抽出来的函数
const res = download(item);
if (res !== true) {
// 跨域错误无法捕获,如果返回不是true的话就走另外一个方法
// downloadUrlFile是简单封装的通过提交表单下载文件的方法
downloadUrlFile(item)
}
});
}
四种方法的比较:
| 方法 | 支持跨域 | 是否弹出tab | 是否支持直接下载浏览器可展示的资源 |
|---|---|---|---|
| a标签 | 是 | 否 | 同源可通过download属性支持 |
| window.open | 是 | 是 | 否 |
| 构造表单submit | 是 | 否 | 否 |
| download.js | 否 | 否 | 是 |
参考资源
了解HTML/HTML5中的download属性
download.js官方文档