RabbitMQ,RocketMQ,AMQ 这么多选择,到底用哪个?
作者 | 张帆

热爱技术的老油条
一、常见可实现消息队列的协议
讲到消息队列不得不讲一下消息队列的协议,常见消息队列协议也并不是多如牛毛。
开始正题之前,先列举一下常见的协议与基本概念
AMQP(Advance Message Queuing Protocol)
AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,[应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
MQTT( Message Queuing Telemetry Transport)
MQTT 全称为 Message Queuing Telemetry Transport(消息队列遥测传输)是一种基于发布/订阅范式的“轻量级”消息协议,由 IBM 发布。
MQTT 可以被解释为一种低开销,低带宽占用的即时通讯协议,可以用极少的代码和带宽的为连接远程设备提供实时可靠的消息服务,它适用于硬件性能低下的远程设备以及网络状况糟糕的环境下,因此 MQTT 协议在 IoT(Internet of things,物联网),小型设备应用,移动应用等方面有较广泛的应用。
IoT 设备要运作,就必须连接到互联网,设备才能相互协作,以及与后端服务协同工作。而互联网的基础网络协议是 TCP/IP,MQTT 协议是基于 TCP/IP 协议栈而构建的,因此它已经慢慢的已经成为了 IoT 通讯的标准。
XMPP(eXtensible Messageing and Presence Protocol)
可扩展通讯和表示协议 (XMPP) 可用于服务类实时通讯、表示和需求响应服务中的XML 数据元流式传输。XMPP 以 Jabber 协议为基础,而 Jabber 是 IM 应用中常用的开放式协议。
JMS(Java Message Service)
JMS 即 Java 消息服务(Java Message Service)应用程序接口是一个 Java 平台中关于面向消息中间件(MOM)的 API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java 消息服务是一个与具体平台无关的 API,绝大多数MOM 提供商都对 JMS 提供支持
STOMP(Streaming Text Orientated Message Protocol)
它提供了一个可互操作的连接格式,允许 STOMP 客户端与任意 STOMP 消息代理(Broker)进行交互。STOMP 协议由于设计简单,易于开发客户端,因此在多种语言和多种平台上得到广泛地应用。
以上内容均摘自网络,主要介绍了常见的可以说得出名字的协议,但是某些产品使用了自身独特的协议,不一一例举
| 基本特征 | 使用环境与场景 | |
|---|---|---|
| AMQP | 订阅,发布,事务 | 标准网络环境,高可靠性要求场合 |
| MQTT | 订阅,发布,事务,小型传输 | 低功耗网络环境,高可靠性要求场合 |
| XMPP | 客户端,服务端、网关 | 标准网络环境,P2P流式数据传输,数据架空存储 |
| STOMP | 订阅,发布,自定义事件 | 伴随WEBSOCKET使用,主要弥补HTTP协议无状态问题 |
| JMS | 高度抽象,平台无关 | 通用化场景 |
二、常见基础设施与协议支持
| AMQP | MQTT | XMPP | STOMP | JMS | |
|---|---|---|---|---|---|
| ActiveMQ | Y | Y | N | Supported By ActiveMQ-CPP | Y |
| RabbitMQ | Y | Y | N | Y(by pl) | Y |
| RocketMQ | N | N | N | N | N |
| ActiveMQ Artemis | Y | Y | N | Y | Y |
| OpenFire | N | N | Y | N | N |
| Tigase XMPP Server | N | N | Y | N | Y |
| NSQ | N | N | N | N | N |
| MSMQ(微软) | N | N | N | N | N |
| Kafka/Jafka | Y | N | N | N | Y(Feature but not Supported) |
由上表可知,同样是消息组件,消息队列和点对点流式信息传输,属于两个不同的领域,应用的场景也完全不同,如果发生了不匹配场景的误用,不一定会产生多严重的后果,但是一定会让使用者感到无力,因为与场景匹配的特性越少,在某些功能实现上越是麻烦。
消息队列的主要应用场景:解耦、消峰、广播、最终一致性
点对点消息的主要应用场景:数据架空存储、点对点数据传输
三、选用消息队列基础设施带来的思考
常见件的各类 MQ 参数列表,具体的评测数据,此处不列举,不做比较,数据很多,有兴趣的还可自行测试。
| ActiveMq / Artemis | RabbitMq | RocketMq | Kafka | |
|---|---|---|---|---|
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 时效性 | 微秒级 | 微秒级 | 微秒级 | 微秒级 |
| 可靠性 | 低概率丢失数据 | 低概率丢失数据 | 优化后可0丢失 | 优化后可0丢失 |
| 可用性 | 高,主从架构 | 高,主从架构 | 高+,分布式 | 高+,分布式,副本集 |
| 消息消费方式 | At least once At most once Exactly once |
At least once At most once Exactly once |
At least once At most once Exactly once |
At least once At most once Exactly once |
以上是常见于一般博客对 MQ 基础设施的比较,此类表格随处可见,很多人看了多认为哪个设施吞吐量高,哪个设施可靠性高,但是这些只是账面上的数据,不代表设施复合真实的消费场景,以下划出重点
以往对于 kafka 的吞吐量,是以at most once 投递策略为测试基准的,这种策略下,不保证可靠性,大多数组件使用此策略,吞吐量都有大幅度提升
kafka 使用事务语义实现,并不直接支持 amqp 事务,这个特性体现在客户端程序中
多个消费者同时消费 kafka 时,根据其机制,需要确保 offset 的一致性,这时候需要引入其他设施来保证
RocketMq 事务支持完整,但是不支持 Amqp,使用过程中,代码移植较麻烦
对于 RocketMq 的部署,有云服务,必须是有云服务,此类设置是不建议实用云主机搭建的,因为云主机基于内核虚拟化技术,I/O 受制于 cgroup,因此性能与物理主机相比,是大打折扣的,无法保证设施的最大性能
RabbitMq 缺乏消息对账机制,而使用事务和双向确认时,吞吐量无保证(换其他 Mq 也有同样问题)
ActiveMq 的集群,使用的是 LevelDB 数据库作为集群,而不是常见的 mysql
对于一些设施细节的另类理解
kafaka 并不全面支持 Amqp 事务,对 JMS 支持也不是完整的。
ActiveMQ 是这些竞品中,性能最差的,但是也是功能最完整的。
Rocket MQ 的 API 和 AMQP 没什么联系,消费端生产端,同时也是所有 MQ中部署成本最高的。
RabbitMQ 部署简单,只是缺了消息对账。
基于上述四点,其实不难看出,在 MQ 选取方面,也并不是看 MQ 特性那么简单,那么我再以 RocketMQ 为例,进行展开。
我们先看下 RocketMQ 的部署结构。
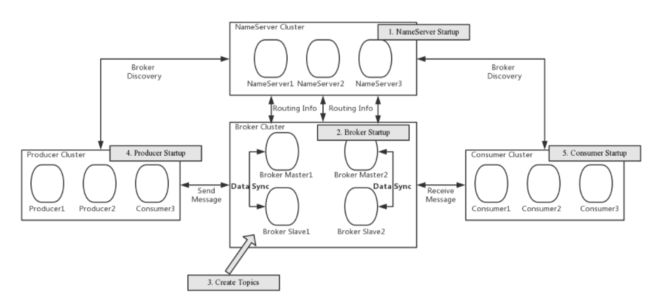
NameServer 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
Broker 部署相对复杂,Broker 分为 Master 与 Slave,一个 Master 可以对应多个 Slave,但是一个 Slave 只能对应一个 Master,Master 与 Slave 的对应关系通过指定相同的 BrokerName,不同的 BrokerId 来定义,BrokerId为0 表示 Master,非 0 表示 Slave。Master 也可以部署多个。每个 Broker 与 NameServer 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 NameServer。注意:当前RocketMQ 版本在部署架构上支持一 Master 多 Slave,但只有 BrokerId=1的从服务器才会参与消息的读负载。
Producer 与 NameServer 集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Master 建立长连接,且定时向 Master 发送心跳。Producer 完全无状态,可集群部署。
Consumer 与 NameServer 集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Master、Slave建立长连接,且定时向 Master、Slave 发送心跳。Consumer 既可以从 Master订阅消息,也可以从 Slave 订阅消息,消费者在向Master拉取消息时,Master服务器会根据拉取偏移量与最大偏移量的距离(判断是否读老消息,产生读I/O),以及从服务器是否可读等因素建议下一次是从 Master 还是 Slave 拉取。
以上内容,摘自 RocketMq 的 github 代码库。从上图来看,不难得出一个结论,RocketMq 的集群化部署和维护成本其实并不低,因为还需要维护 NameServer Clust,当然如果需 RocketMQ 10万级的吞吐量,这些都是可接受的,但是事情远没有大家的想像的那么简单。
由于云服务普及,因此大部分公司使用云主机而非自建 IDC 使用物理主机,即使使用物理主机,也是切分成虚拟机使用
有 RocketMQ 脱胎于阿里,因此腾讯云,百度云等,没有 RocketMq 的服务。
在云服务上部署 RocketMq 与直接购买 RocketMq 的服务,有着巨大的性能差异,可能会有数百倍的差距。
如果使用的非阿里云,而购买了 RocketMQ 的云服务,那么就等于把自身应用和 MQ 应用,部署在了两个不同的网段内,实际性能只有经过测试才知道
很多人看了以上三点,并没有特别的概念,这里不得不讲一下云主机部署基础设施和直接购买云服务的差别
直接购买的云服务有某些优化,这个毋庸置疑
得益于 Cgroup 技术,云虚拟主机实际上,会被此技术限制资源的使用,关于此技术,参见《CGroup 介绍、应用实例及原理描述》
基于上述两点,想要得到某个基础设施的标称性能的话,已经远远不是大量的优化技巧可以可以解决的。
基于上述三点,同样的情况也会发生于 kafka,ActiveMq 等设施
斟酌以上某些特征后,其实不难得出结论,设施的性能高低并不是某些场景下选用某些设施的理由,因为任何基础的使用,都不能超出对设施的保有能力。
四、另类的维度
此处,全篇已经接近尾声。其实对于 MQ 选择,可以另外划分为下面5个维度:
可靠性:即基础设施无障碍运行时数和消息可靠性。易用性:即学习成本和代码复用成本 部署成本:这个需要结合基础设施的实际性能瓶颈来综合考虑,花费低的如云主机,未必表示部署成本低,因为其自身瓶颈会妨碍MQ设施性能的发挥。
从部署成本由高到低:一定是云服务、自建 IDC、云主机。从性能由高到底:云服务、自建 IDC、云主机
吞吐量:吞吐量其实可以分为 理论吞吐量和实际吞吐量,实际吞吐量取决于部署方式和优化配置方式
场景匹配度:既 MQ 提供的功能特征,是否满足项目所需的场景需要,并且能满足未来可能出现的部分场景(注意,任何前期技术选型,场景都视作一个变量来看待)。
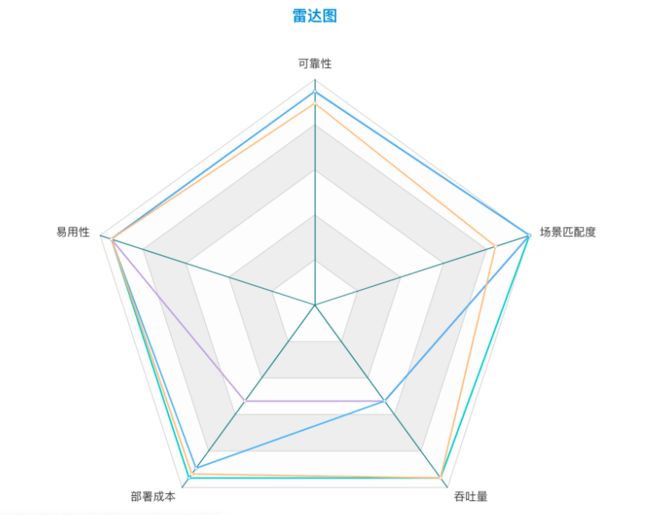
如果给定的某一个场景后,画出雷达图,那么四种不同 MQ 的实际情况可能类似上图,此时具体选择什么,就无需再纠结了。根据项目中的实际需求对上述维度进行排序即可。但是前提一定以满足场景匹配度和吞吐量为前提。
假设上述图表满足 80%的场景,那么我可以进行以下举例。
举例1:假设某个场景,以数据收集为主,要求10万以上吞吐量,要求确保消息数据存储的可靠性。那么根据上述图表,大概率是在 kafka 和 RocketMq 中进行选择。
举例2:假设某个场景,以异步化为主,对单机吞吐量不作要求,要求兼顾可靠性同时,减少部署和维护成本。那么根据上述图表,大概率是在 RabbitMQ 和 ActiveMQ 中进行选择。
五、写在结尾
不管如何选择,场景匹配度一定是第一位的,要避免出现人云亦云的情况,很多设施的账面参数,都是有前提的。充分了解了前提,才能更好的选择合适的MQ基础设施,否则就会出现很多莫名奇妙的情况,比如特征功能一大堆,仅需要某个特征时,发觉基础设施居然无法提供。很多看不见的东西都在细节里,做出判断之前,尽可能多的了解某些技术细节,有利于得出最合理的判断。
全文完
以下文章您可能也会感兴趣:
逻辑思维:理清思路,表达自己的技巧
Actor 模型及 Akka 简介
从零搭建一个基于 lstio 的服务网格
单元测试 -- 工程师 Style 的测试方法
理解 RabbitMQ Exchange
技术选型的艺术
Apache Common Pool2 对象池应用浅析
函数扩展
Linux 的 IO 通信 以及 Reactor 线程模型浅析
浅谈 BI 与数据分析的可视化
捋一捋 App 性能测试中的几个重要概念
所谓 Serverless,你理解对了吗?
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 [email protected] 。
