DarkRank: Accelerating Deep Metric Learning via Cross Sample Similarities
论文地址 论文翻译的博客
2018 AAAI,图森
针对问题
探讨现有知识蒸馏方法中监督信息soft target忽略的“知识”
all these methods miss another valuable treasure – the relationships (similarities or distances) across different samples.
本文创新点:
(1)提出了一种新的知识——cross sample similarities ;知识从哪来?deep metric learning model(度量学习,主要用于无监督(聚类)中对样本距离进行度量);
(2)怎么迁移知识?learning to rank思想,利用teacher网络和student网络所提取特征的排序的相似性构建损失函数
网络结构示意图
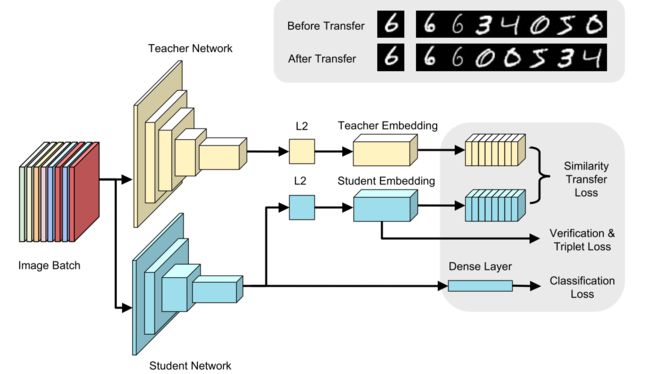
达到的效果:
在度量学习任务上进行测试,包括行人重新识别,图像检索和图像聚类。在baseline上提升明显,并且与其他现有的方法(例如基于soft target的知识蒸馏)结合也会带来提升
局限性:还是在最后一层上加损失函数的方法,可能会比较难训
Related works
1. Deep Metric Learning 度量学习
流程:先通过深度神经网络提取特征,再计算特征的欧式距离
关键:增大类间距离,减小类内距离,常用于聚类
常用实现手段:设计损失函数,Classification loss,Verification loss,Triplet loss,center loss
2. Knowledge Transfer 知识迁移
最早2006,first proposed to approximate an ensemble of classifiers with a single neural network
Hinton 2014:软标签比one-hot标签包含更多信息
挖掘其他知识:(1) 隐藏在feature map 中:FitNets(Romero 2015), Attention Transfer(Zagoruyko and Komodakis 2017) and Neuron Selectivity Transfer(Huang and Wang 2017),(2)利用梯度2017NIPS_Sobolev training for neural networks
3. Learning to Rank 排序学习
问题定义:given a query, rank a list of samples according to their similarities
方法分类:pointwise,pairwise,listwise
本文利用 listwise: teacher network和student network分别提取特征(维度不一定相等),计算打分函数和相似性转移损失函数,老师网络的知识替代传统排序学习中的ground truth。
注意:并没有真实的排序label,而是用网络的特征来计算相似性score
Background
参考排序学习中的两种方法设置损失函数:
ListNet Learning to rank: from pairwise approach to listwise approach. 2007. In ICML.
ListMLE Listwise approach to learning to rank: theory and algorithm. 2008. In ICML
给定query q和一系列candidate x,对每一种可能的排序分配概率。
排序pai={4,3,1,2}表示第4个样本x排在第一位,第3个样本x排在第2位…
X维度p*n,第i列xi维度为p(特征维度),则每一种排序的概率为
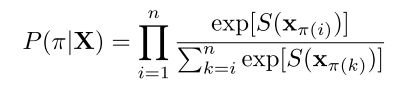
S(x)表示样本x与q之间距离的分数。
ListNet 损失函数:
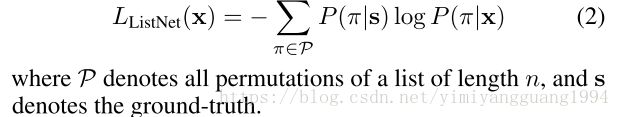
ListMLE 损失函数:

本文用老师网络的知识替代ground truth构成损失函数。
Our Method
1. Similarity Score Function Based on Embedded Features
在传统的图像分类中,卷积神经网络倒数第二层的输出通常连接到具有 Softmax 激活的完全连接层,用于预测图像所属的类或类别。如果剥离掉这个分类层的网络,那么就只剩下一个网络,为每个样本输出一个特征向量,通常每个样本有 512 或 1024 个特征。这就是所谓的embedding features。
similarity score function ——基于embedding features的欧式距离,增加两个超参数(后面有实验分析了超参数作用)
![]()
2. Soft and Hard Transfer
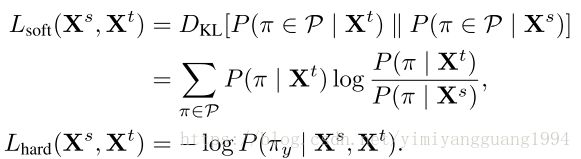
对比:soft transfer 考虑了所有可能的排序,hard transfer 只需要老师网络的最大可能的排序,速度更快,性能也跟soft transfer差不多。
梯度计算:Si表示前面的S(x_pai(i))_
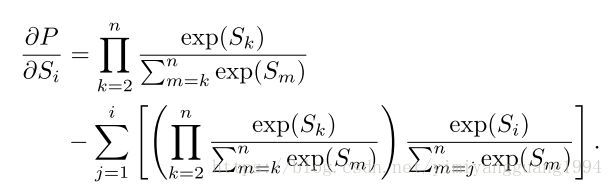
实验
应用场景:行人重新识别,图像检索和图像聚类
数据集:
(1) CUHK03,包含1360个身份的13164张图片,每个身份由两个不同视角的摄像头捕获
(2) Market1501, 1501个身份的32668张图片,这些图像是从六个不同的相机收集的
(3) CUB-200-2011, 11788 images of 200 bird species, 在前100类上训练网络,后100类上测试image retrieval和clustering
网络:
teacher network: Inception-BN
student network: NIN-BN
损失函数:
(1)训练teacher baseline和student baseline的时候都用到了large margin softmax loss,verification loss and triplet loss。目的:尽可能增大类间距离,减小类内距离,度量学习得到更好的特征。
(2)然后,针对darkrank或其他拿来比较的网络,添加不同知识构成的损失函数。比较对象:(1)KD:Hinton 2014提出的soft target with T=4;(2)Match: 直接对query和sample的特征计算欧式距离,teacher与student网络分别计算的距离之间作差即为损失函数。
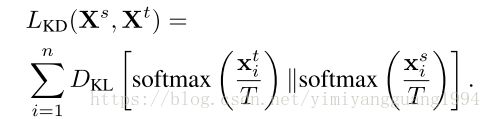
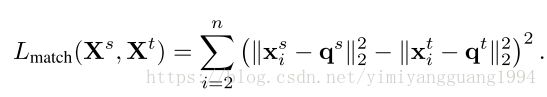
说明:Match 与本文DarkRank 损失函数的区别包括,(1)本文在特征距离的基础上增加了两个参数作为score(后面的Ablation Analysis分析了参数的作用);(2)本文并不要求teacher和student特征距离相等,而是考虑它们从大到小的排序,即顺序是否一致。感觉这里是考虑到了teacher和student的距离可能是不同量级的大小,放松了对特征维度的要求?
具体实现:
加载在Imagenet LSVRC数据集上预训练的网络,首先移除特定预训练任务的fc层(不经过分类),对特征图进行全局平均池化,输出接入一个fc层再加上L2正则化层,生成最后的embeddings(也就是learning to rank的输入特征)。具体参见网络结构示意图。
结论:
单独用 DarkRank 并没有比KD方法好,但与之结合起来可以提高精度,说明本文所关注的不同样本之间的similarity or distance的确包含soft target忽略的知识
与teacher网络对比,测试速度提升了3倍
Ablation Analysis
分析三个超参数的作用:
1. Contrast β
动机:If the distances of candidates and the query are close, the associated probabilities for the permutations are also close, which makes it hard to distinguish from a good ranking to a bad ranking.So we introduce the contrast parameter β to sharpen the differences of the scores.
结果:β = 3最好,欧式距离的三次方,作用同样是拉大样本之间的距离。
2. Scaling factor α
动机:While constraining embeddings on the unit hyper-sphere is the standard setting for metric learning methods in person ReID, a recent work(Ranjan, Castillo, and Chellappa 2017) shows that small embedding norm may hurt the representation power of embeddings.
结论:α = 3 最好, 目的是获得更好的特征。
3. Loss weight λ
作用: balance the transfer loss and the original training loss
结论: λ取不同值时结果基本稳定。We set the loss weight of our transfer loss to 2.0.
再次强调本文优点:非监督学习中,缺乏class level supervision,监督信号来自于pairwise similarity,KD不适用。本文利用instance level supervision(?), 适用于监督/非监督学习。同时,FitNet 利用的监督信息同样是instance level supervision,单独使用的效果也差不多,两者结合有一定提升。说明了本文知识的不可代替性。
代码运行结果 Github代码
1. 原reid.py代码第136行:
lmnn = mx.sym.Custom(data=dropout, epsilon=0.1, threshd=0.9, op_type='LMNN', name='lmnn')查阅了MXnet中如何定义新的operator 点击打开链接
如果想使用自定义操作符,需要创建 mx.sym.Custom 符号。其中,使用新操作符的注册名字来设置参数 op_type:
op_type名字写错,查看PYOP目录下的lmnn.py, 第75行的注册声明为@mx.operator.register("LMNNLoss"),因此改为
op_type='LMNNLoss'2. 按照代码测试soft transform (即输入参数loss_weight_listnet = 16.0),成功运行。
3. 测试比较对象1,Hinton的soft target,设置输入参数 kd_temperature = 4.0 ,代码运行报错。
原reid.py第113行,symbol = importlib.import_module('symbol.symbol_' + network_name).get_symbol(num_id)
错误:get_symbol() takes no arguments (1 given)
解决方法:去掉括号中的num_id
继续报错:UserWarning: You created Module with Module(..., label_names=['lsoftmax_label']) but input with name 'lsoftmax_label' is not found in symbol.list_arguments().
KeyError: 'lsoftmax_label'
原因:原reid.py第318,319行,设置了t_label_names = ['lsoftmax_label'] 和t_label_shapes,但实际上将t_symbol结构打印出来发现没有lsoftmax相关结构。
解决:将这两句注释掉,并将后面326,327行包含这两项的两句话改为
t_module = mx.module.Module(symbol=t_symbol, context=devices, label_names=[])
t_module.bind(data_shapes=data_shapes, for_training=False, grad_req='null')顺利运行。
这里因为不了解代码的思想,走了一些弯路,并且目前只是算法调通了,不知道是不是改变了作者的原意。
返回来看reid.py的第113行上下文:
if mode == 'kd':
symbol = importlib.import_module('symbol.symbol_' + network_name).get_symbol(num_id)
else:
symbol = importlib.import_module('symbol.symbol_' + network_name).get_symbol()
if mode == 'student':
symbol = build_network(symbol, num_class=num_id)最后简单粗暴地去掉了num_id使得程序顺利运行,但同时也失去了第一个判断语句的意义。
20180711更新:发现了一个问题 https://blog.csdn.net/shuzfan/article/details/50037273
/example/image-classification/train_imagenet.py中,
net = importlib.import_module('symbol_' + args.network).get_symbol(args.num_classes)
get_symbol()是可以有传入参数的,为什么程序会报错:get_symbol() takes no arguments (1 given)
之前尝试了去掉num_id之后,同时将kd相关层的网络结构加入到symbol中:
symbol = build_network(symbol, num_class=num_id)
根据报错修改了传入的label相关参数,最后出现了各种维度不匹配问题。
与跑通的listnet进行对比之后,发现t_symbol只继承了原始teacher network的symbol和params,并没有在网络结构后面加上与知识蒸馏相关的结构。但s_symbol除了继承student network的网络和参数之外,还通过build_network函数增加了新的层包括lsoftmax, softmax, lmnn, kd, listnet等)。
猜测t_module的输出只是特征,需要结合s_module的网络结构计算kd或者listnet损失函数。
listnet_loss.py中的forward函数:
s_features = in_data[0].asnumpy().astype(float) # type: np.ndarray
s_features *= np.sqrt(self.scale)
t_features = in_data[1].asnumpy().astype(float) # type: np.ndarray
t_features *= np.sqrt(self.scale)Q:怎么确保in_data中同时含有来自student和teacher的特征?对应embedding features,也就是softmax前面层的输出,正好是t_module的输出。
kd损失计算需要teacher_logit,怎么计算和流动?
再来看一下知识迁移模块kt_module的数据流动:
kt_module代码:
第132到140行
if isinstance(self._teacher_module, list):
for mod in self._teacher_module:
mod.forward(data_batch=data_batch, is_train=False)
transfer_label = mod.get_outputs()
data_batch.label += transfer_label
else:
self._teacher_module.forward(data_batch=data_batch, is_train=False)
transfer_label = self._teacher_module.get_outputs()
data_batch.label = data_batch.label + transfer_label