写在前面
最近工作转到Android 性能优化方向,刚转过来,相关经验缺乏,纪录一个目前让人恼火的问题。非常遗憾,本文到目前为止还未能提供解决问题的优化方案,也没有明确定位到导致性能问题的瓶颈所在。就像解数学题一样,花费了大把时间,然并卵。之所以写它,两个目的:
- 这个过程中,自己还是有一定收获的,且做纪录。
- 抛出问题,希望能与更多人一起讨论性能优化的方法。
问题描述
冷启动email应用相对于参考机慢。
参考机OS: AndroidM
问题机OS: AndroidN
参考机平均耗时:1.7s
问题机平均耗时:2.0s
问题分析
Email应用版本自身的影响
先查看email版本是否相同,使用命令:
adb shell dumpsys package com.tct.email|grep version
得到问题机email版本---> versionName=v7.0.4.1.0312.0_0228
参考机email版本---> versionName=v5.2.10.3.0214.0
参考机与对比机email版本不同.因平台Email应用与Exchange应用联系紧密,一并查看Exchange版本。
问题机exchange版本---> versionName=v7.0.4.1.0312.0_0228
参考机exchange版本--->versionName=v5.2.10.3.0214.0
使用用命令:
adb shell am start -W -S com.tct.email/.activity.Welcome
查看Email的启动时间
为了方便统计,编写一个简单的脚本封装上述命令。脚本简短,在此贴出。
#!/usr/bin/env python
'''
@author: [email protected]
@summary: this script use to test launch activity time
'''
from commands import getoutput
from time import sleep
from __builtin__ import int
LAUNCH_PACKAGE = 'com.tct.email'
LAUNCH_ACTIVITY = 'com.tct.email/.activity.Welcome'
TEST_COUNT = 5 #测试次数
SLEEP_TIME = 10 #每次启动的时间间隔
LOG_LINE = "**************************************************"
def getVerInfo():
getVerCmd = "adb shell dumpsys package %s | grep version" % (LAUNCH_PACKAGE)
verinfo = getoutput(getVerCmd)
print LOG_LINE
print "Test APK version info is:"
print verinfo.strip()
print LOG_LINE
def getLaunchTime():
getLaunchTimeCmd = "adb shell am start -W -S %s |grep TotalTime|awk '{print $2}'" % (LAUNCH_ACTIVITY)
totalTime = 0
for i in range(1, TEST_COUNT + 1):
time = getoutput(getLaunchTimeCmd)
print "%s lunch time is %s" % (i, time)
totalTime += int(time)
if (i < TEST_COUNT):
sleep(SLEEP_TIME)
i = i + 1
average = totalTime / TEST_COUNT
print "%s launch time average is %s" % (TEST_COUNT, average)
def main():
getVerInfo()
getLaunchTime()
if __name__ == '__main__':
main()
其输出结果如下:
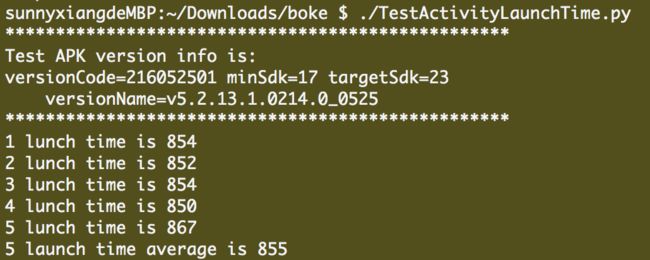 脚本运行结果图
脚本运行结果图
| 问题机 | 参考机 | |
|---|---|---|
| 1 | 750 | 674 |
| 2 | 782 | 649 |
| 3 | 770 | 649 |
| 4 | 754 | 633 |
| 5 | 781 | 671 |
从结果看对比机明显好于问题机,那么这种差异是否由apk自身版本不一致导致呢?
为了回答这个问题,将问题机的emal安装到参考机再次测试。
使用命令:
adb shell pm path com.tct.email
找到email的apk路径
使用命令:
adb pull /system/app/Email/Email.apk
将问题机的Email拉出来。
使用命令:
adb install -r Email.apk
将刚拉出来的Email安装至参考机,此时再次测试得到如下表格:
| 问题机 | 参考机 | 参考机+问题机的Email | |
|---|---|---|---|
| 1 | 750 | 674 | 783 |
| 2 | 782 | 649 | 785 |
| 3 | 770 | 649 | 783 |
| 4 | 754 | 633 | 801 |
| 5 | 781 | 671 | 777 |
| 均值 | 767 | 655 | 786 |
为了直观表述,根据上述数据生成柱状图如下:
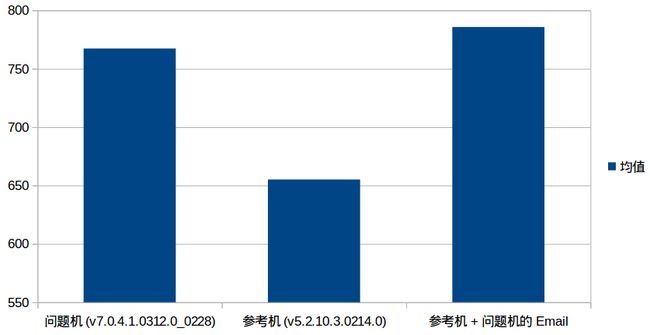
从上述柱状图看Email应用的版本对最终测试数据的影响很大,本以为可以确定是APK版本差异导致的问题,然而最后测试“问题机+参考机Email”的组合发现启动依然慢,数据没有整理,就不贴出来了。
由于无法确定是APK版本差异导致的问题,因此该问题就划归在平台侧分析。
平台影响
cpu差异
通过命令:
adb shell getprop ro.product.cpu.abi
可以看系统是32还是64位
问题机:armeabi-v7a,armeabi
参考机:armeabi-v7a
通过命令:
adb shell cat /proc/cpuinfo
查看cpu信息,二者cup一样均为4核:
```
Hardware : Qualcomm Technologies, Inc MSM8909
Revision : 0000
Serial : 0000000000000000
Processor : ARMv7 Processor rev 5 (v7l)
```
排除CPU影响。
内存差异:
通过命令:
adb shell getprop dalvik.vm.heapstartsize
查看系统分配给应用冷启动的初始堆空间
问题机:16m
参考机:8m
排除该项。
通过命令:
adb shell cat /proc/meminfo
查看系统总体的内存设置情况,得到下图:
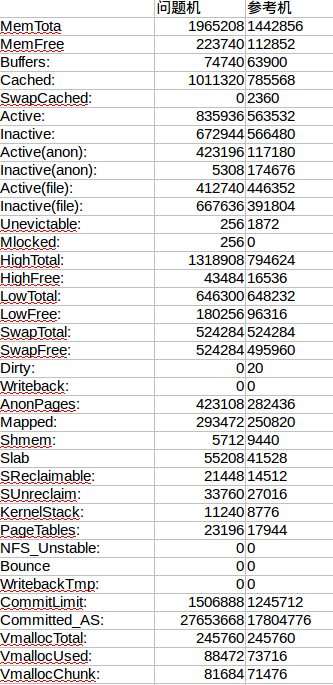
利用excel生成柱状图直观的看看各项值的差异,内容较多,只截取差异最大的一部分。

可以很直观的看到参考机和问题机上Committed_AS差异较大,其他各项二者相当,问题机都略高于参考机。尤其总内存大小问题机还比参考机高。好多项的具体含义我也不清楚,直观感觉差异项最大的最可能包含着潜在的问题。
那么这个 Committed_AS是表征什么的呢?
原来Committed_AS 表示所有进程已经申请的内存总大小,(注意是已经申请的,不是已经分配的),如果 Committed_AS 超>过 CommitLimit 就表示发生了 overcommit,超出越多表示 overcommit 越严重。Committed_AS 的含义换一种说法就是,如果要绝对保证不发生OOM (out of memory) 需要多少物理内存。
在打个比方,餐馆有10张餐桌,假设1张餐桌只能接纳1组客人。那么一下来了100组客人,Committed_AS的含义餐馆至少需要100张餐桌才能保证这些客人都能及时用餐。透过它能看到餐馆的忙碌程度。
因为问题机的MemTot是大于参考机的,因此该项的差异不太可能是平台侧影响性能的主因,故而排除。
通过命令
adb shell getprop|grep dalvik
查看问题机dalvik默认配置
[dalvik.vm.appimageformat]: [lz4]
[dalvik.vm.dex2oat-Xms]: [128m]
[dalvik.vm.dex2oat-Xmx]: [512m]
[dalvik.vm.heapgrowthlimit]: [128m]
[dalvik.vm.heapmaxfree]: [8m]
[dalvik.vm.heapminfree]: [512k]
[dalvik.vm.heapsize]: [256m]
[dalvik.vm.heapstartsize]: [32m]
[dalvik.vm.heaptargetutilization]: [0.75]
[dalvik.vm.image-dex2oat-Xms]: [128m]
[dalvik.vm.image-dex2oat-Xmx]: [128m]
[dalvik.vm.isa.arm.features]: [default]
[dalvik.vm.isa.arm.variant]: [cortex-a7]
[dalvik.vm.stack-trace-file]: [/data/anr/traces.txt]
[dalvik.vm.usejit]: [false]
[dalvik.vm.usejitprofiles]: [false]
[dalvik.vm.zygotemaxfailedboots]: [5]
[persist.sys.dalvik.vm.lib.2]: [libart.so]
[ro.dalvik.vm.native.bridge]: [0
这里各项默认值跟参考机相比也没发现异常。
猜测因内存差异导致的问题到这一步未找到有效证据。
I/O 读写速度差异
利用命令
adb shell vmstat -n 1
查看Email启动瞬间系统层的变化。得到如下输出。关于vmstat的信息,可以点击这里
===================================问题机=====================================
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 269536 70424 1009964 0 0 0 0 0 388 1 1 99 0
*2 0 0 271228 70432 1009956 0 0 0 104 0 2653 14 17 68 0
*6 0 0 252056 70444 1010004 0 0 0 160 0 8102 35 23 42 0
0 0 0 248168 70444 1010004 0 0 0 0 0 2487 11 3 86 0
===================================参考机=====================================
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 29596 89580 55240 781332 0 0 0 0 0 829 2 2 97 0
*6 0 29596 90784 55268 781304 0 0 0 800 0 4580 0 0 0 0
*1 0 29596 74996 55268 781316 0 0 0 128 0 5332 33 12 55 0
0 0 29596 76220 55268 781368 0 0 0 0 0 2118 0 0 100 0```
以上输出开头加\*的行是启动Email时对应的变化(\*是为了方便描述,自行添加的)。
下面来挨个过一遍。
procs栏里的r(running),它表示运行队列中的进程数,即多少个进程分配到了CPU. 二者相差不大,看不出问题。
b(blocked) 被阻塞的进程数,二者均为0,表示没有进程被阻塞。
memory栏里的swpd。
特意在[linux论坛](http://www.linuxquestions.org/questions/linux-general-1/vmstat-shows-swpd-as-0-a-300148/)查了下其含义,看看其中某段解释:
>Note that a swap usage rate of zero is highly desirable because it means that your existing RAM can handle the load that's being put on it without resorting to writing memory pages to disk. In other words, anytime your system has to access swap, you will be taking a *huge* performance hit -- access times in RAM are measured in nanoseconds; access times on hard drives are measured in milliseconds. That's about 6 orders of magnitude worse, and you should avoid it if at all possible.
>To say it another way, Linux treats swap space as a resource of last resort. If the demands you are putting on your machine are such that RAM is overloaded and cannot handle it, then your system will write out memory pages to disk, but as mentioned this is only done when RAM is entirely overloaded. Back in the days were 64Mg was considered leading edge, it was pretty common for swap to be called into service, but these days, where 256Mg if not 512Mg of RAM is standard, it's increasingly infrequent that swap gets used.
Overall, I'd consider zero swap usage to be a compliment to how you've set up your system. That being said, reserving some swap space (256Mg max, regardless of the RAM) is a useful thing, just in case. -- J.W.
swpd表示已经使用的虚拟内存大小. 如果大于0,表示手机物理内存不足,需要将部分内存内容转移到磁盘上。如果不是应用内存泄漏的原因,就是当前后台执行的任务过多了。问题机为0,这个是个好的现象,说明问题机至少不存在内存吃紧的情况。
memory栏里的free表示空闲内存大小,同样问题机大于参考机,这也是好现象。
memory栏里的buff/cache两台机器也没有异常值排除。
swap栏里的si,表示每秒从磁盘(disk)读入的内存大小(/s). 如果这个值大于0,表示物理内存不足或者内存泄漏,需要查找耗内存的进程。
swap栏里的so,表示每秒从内存写入磁盘的内存大小,他的数据不为0,表示当前内存不够用,需要将部分内存的内容腾出来到磁盘空间。
上述两项值在问题机和参考机上都为0.说明这里不是问题所在,故而排除。
io栏里的bi表示手机里块设备每秒接收的块数量,对应写操作。而bo正好相反表示每秒发送的块数量,对应读操作。这里看到bi均为0,表示问题机和参考机在启动Email的阶段都没有写入操作,但bo值参考机明显大于问题机。这里可能是个问题,想象这样一个场景,启动Email时需要读取执行的code段,而问题机一次读取的code段少于参考机,那么相应的问题机在这段时间可执行的code段也就少于参考机,进而有可能影响最终的启动速度。
为了验证该猜想,调整I/O读写速度在来看该问题。
使用命令:
>adb shell echo 1024 > /sys/block/mmcblk0/queue/max_sectors_kb
将max_sectors_kb扩大一倍,之前是512. max_sectors_kb值代表发送到磁盘的请求数。然而结果依然没有提升。想不通为何。
system栏里的in(interrupts) 表示在delay的时间内(默认为1秒)系统产生的中断数,二者均为0,排除
system栏里的cs (context switch) 表示在delay的时间内(默认为1秒)系统上下文切换的次数. 例如进程切换,要进行上下文切换;线程的切换,要进行上下文切,代码执行进入内核空间,上下文也要切换。这个值越小越好,太大了要考虑降低线程或者进程数目。因为上下文切换很耗资源,次数过多表示CPU大部分浪费在上下文切换而不是执行程序内容,CPU没有充分利用。该项数据参考机是好于问题机的。
cpu栏里的us表示用户空间执行任务所占CPU的时间百分比。看不出问题排除。
cpu栏里的sy表示kernel空间执行任务占用的CPU时间比 , 如果太高,表示系统调用时间过长,例如IO操作频繁。这里问题机明显高于参考机,提示存在问题。
cpu栏里的id表示空闲CPU占用的时间比。一般来说,id + us + sy 接近 100%
cpu栏里的wa表示CPU等待IO完成的时间占比,该值若大,对系统的流程性冲击大。问题机和参考机都为0,看不出问题。
## 写在最后
问题还在持续分析中,如果看到这篇文章的你,有什么好的排查方向,或者排查方法,欢迎一起讨论。