云原生存储系列文章:云原生应用的基石

作者| 郡宝 阿里云技术专家
参与文末留言互动,即有机会获得赠书福利!
导读:存储服务支撑了应用的状态、数据的持久化,是计算机系统中的重要组成部分,也是所有应用得以运行的基础,其重要性不言而喻。在存储服务演进过程中,每一种业务类型、新技术方向都会对存储的架构、性能、可用性、稳定性等提出新的要求,而在当今技术浪潮走到云原生技术普及的时代,存储服务需要哪些特性来支持应用呢?
从本文开始,我们将用一个系列文章对云原生存储进行方方面面的探析,该系列文章将从云原生存储服务的概念、特点、需求、原理、使用、案例等方面,和大家一起探讨云原生存储技术新的机遇与挑战,欢迎大家讨论:
"There is no such thing as a 'stateless' architecture" - Jonas Boner云原生存储系列文章(一):云原生应用的基石
云原生存储系列文章(二):容器存储与K8S存储卷
云原生存储系列文章(三):Kubernetes存储架构
云原生存储系列文章(四):K8S存储实践-Flexvolume
云原生存储系列文章(五):K8S存储实践-CSI
云原生存储系列文章(六):存储卷高可用方案
云原生存储系列文章(七):存储调度与容量感知
云原生存储系列文章(八):数据卷扩缩容能力
云原生存储系列文章(九):云原生存储安全
云原生存储系列文章(十):高性能计算场景的存储优化
本节会介绍云原生存储的基本概念和常用的存储方案。
云原生存储
1.概念
要理解云原生存储,我们首先要了解云原生技术的概念,CNCF 对云原生定义如下:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
简言之:云原生应用和传统应用并没有一个标准的划分界限,其描述的是一种技术倾向,即越符合以下特征的应用越云原生:
- 应用容器化
- 服务网格化
- 声明式 API
- 运行可弹性扩展
- 自动化的 DevOps
- 故障容忍和自愈
- 平台无关,可移植的
云原生应用是一簇应用特征能力的集合,而实现了这些能力的应用在可用性、稳定性、扩展性、性能等核心能力都会有大幅的优化。优异的能力代表了技术的方向,云原生应用正在引领各个应用领域实现云原生化,同时也在深刻改变着应用服务的方方面面。存储作为应用运行的基石,也在服务云原生化过程中提出了更多的需求。
云原生存储的概念来源于云原生应用,顾名思义:一个应用为了满足云原生特性的要求,其对存储所要求的特性是云原生存储的特性,而满足这些特性的存储方案,可以称其为倾向云原生的存储。
2.云原生存储特征
1)可用性
存储系统的可用性定义了在系统故障情况下访问数据的能力,故障可以是由存储介质、传输、控制器或系统中的其他组件造成的。可用性定义系统故障时如何继续访问数据,以及在部分节点不可用时如何将对数据的访问重新路由到其他的可访问节点。
可用性定义了故障的恢复时间目标(RTO),即故障发生与服务恢复之间的时长。可用性通常计算为应用运行时间中的可用时间的百分比(例如 99.9%),以及以时间单位度量的 MTTF(平均故障时间)或 MTTR(平均修复时间)来度量。
2)可扩展性
存储的可扩展性主要衡量以下参数指标:
- 扩展可以访问存储系统的客户端数量的能力,例如:一个 NAS 存储卷同时支持多少客户端挂载使用;
- 扩展单个接口的吞吐量和 IO 性能;
- 扩展存储服务单实例的容量能力,例如:云盘的扩容能力。
3)性能
衡量存储的性能通常有两个标准:
- 每秒支持的最大存储操作数 - IOPS;
- 每秒支持的最大存储读写量 - 吞吐量;
云原生应用在大数据分析、AI 等场景得到广泛应用,在这些重吞吐 / IO 场景中对存储的需求也非常高,同时云原生应用的快速扩容、极致伸缩等特性也会考验存储服务在短时间内迎接峰值流量的能力。
4)一致性
存储服务的一致性是指在提交新数据或更新数据后,访问这些新数据的能力;根据数据一致性的延迟效果,可以将存储分为:“最终一致”和“强一致”存储。
不同的服务对存储一致性的敏感度是不一样的,像数据库这类对底层数据准确性和时效性要求非常高的应用,对存储的要求是具有强一致性的能力。
5)持久性
多个因素应用数据的持久性:
- 系统冗余等级;
- 存储介质的耐久性(如:SSD 或 HDD);
- 检测数据损坏的能力,以及使用数据保护功能重建或恢复损坏数据的能力。
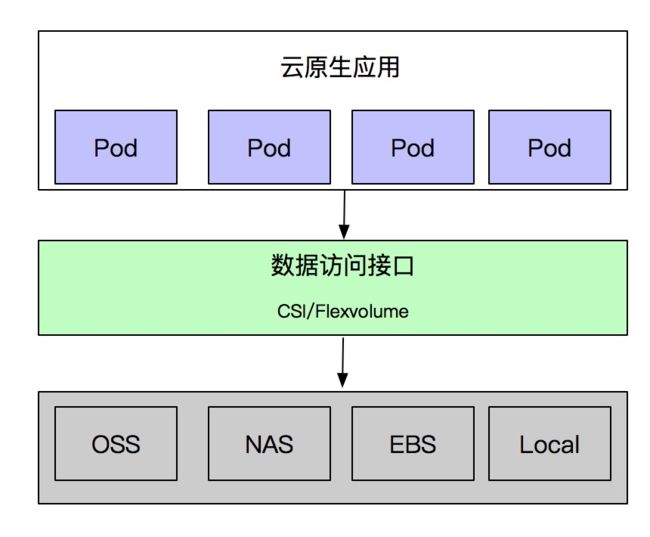
3.数据访问接口
在云原生应用系统中,应用访问存储服务有多种方式。从访问接口类型上可以分为:数据卷方式、API 方式。
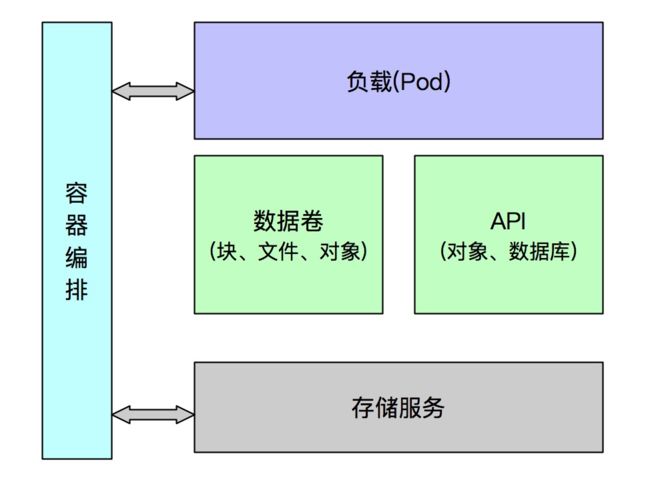
数据卷:将存储服务映射为块或文件系统方式共应用直接访问,使用方式类似于应用在操作系统中直接读写本地目录文件。例如:可以将块存储、文件存储挂载到本地,应用可以像访问本地文件一样对数据卷进行访问;
API:有些存储类型并不能使用挂载数据卷的方式进行访问,而需要通过调用 API 的方式进行。例如:数据库存储、KV 存储、对象存储,都是通过 API 的方式进行数据的读写。
需要说明的是对象存储类型,其标准使用方式是通过 Restful API 对外提供了文件的读写能力,但也可以使用用户态文件系统的方式进行存储挂载,使用方式模拟了块、文件存储数据卷挂载的方式。
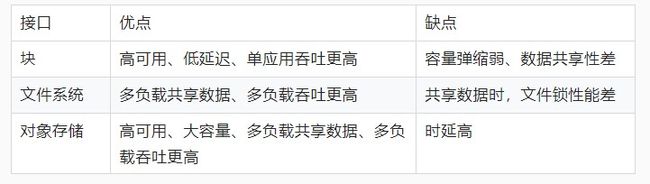
下面表格列举了各种存储接口的优缺点:
4.云原生存储分层
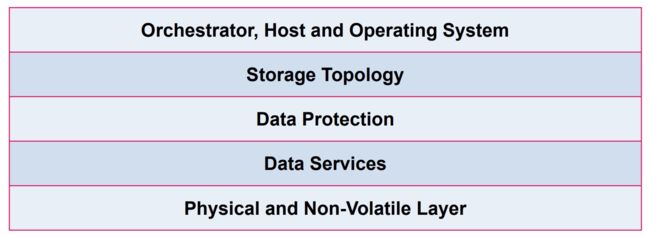
1)编排和操作系统层
这一层定义了存储数据的对外访问接口,即应用访问数据时存储所表现的形式。同上节所述,可以分为数据卷方式和 API 访问方式。这一层是容器服务存储编排团队关注的重点,云原生存储对敏捷性、可操作性、扩展性等方面的需求都在这一层集成、实现。
2)存储拓扑层
这一层定义了存储系统的拓扑结构和架构设计,定义了系统不同部分是如何相互关联和连接的(如存储设备、计算节点和数据)。拓扑结构在构建时影响存储系统的许多属性,因此必须加以考虑。
存储拓扑可以是集中式的、分布式的、或超融合的。
3)数据保护层
定义如何通过冗余的方式对数据进行保护。在存储系统出现故障时,如何通过数据冗余对数据进行保护、恢复非常重要。通常有以下几种数据保护方案:
- RAID(独立磁盘冗余阵列):用于在多个磁盘之间的分发数据技术,同时考虑到冗余;
- 擦除编码:数据被分成多个片段,这些片段被编码,并与多个冗余集合一起存储,保证数据可恢复;
- 副本:将数据分布在多个服务器上,实现数据集的多个完整副本。
4)数据服务
数据服务补充了核心存储功能以外的存储能力,例如可以提供存储快照、数据恢复、数据加密等服务。
数据服务所提供的补充能力也正是云原生存储所需要的,云原生存储正是通过集成丰富数据服务来实现其敏捷、稳定、可扩展等能力。
5)物理层
这一层定义了存储数据的实际物理硬件。物理硬件的选择影响系统的整体性能和存储数据的持续性。
5.存储编排
云原生意味着容器化,而容器服务场景中通常需要某种管理系统或者应用编排系统。这些编排系统与存储系统的交互可以实现工作负载与存储数据的关联。
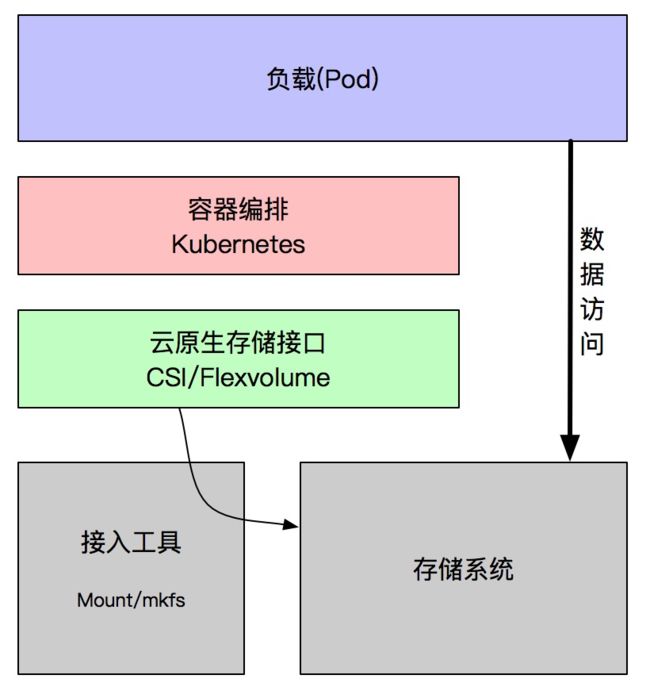
如上图所示:
- 负载:表示应用实例,会消费底层存储资源;
- 编排系统:类似于 K8s 一样的容器编排系统,负责应用的管理和调度;
- 控制平面接口:指编排系统调度、运维底层存储资源的标准接口,例如 K8s 里面的 Flexvolume,已经容器存储通用的 CSI 接口;
- 工具集:指控制平面接口运维存储资源时所依赖的三方工具、框架;
- 存储系统:分为控制平台数据数据平面。控制台平面对外暴露接口,提供存储资源的接入、接出能力。数据平面提供数据存储服务。
当应用负载定义了存储资源需求时,编排系统会为应用负载去准备这些存储资源。编排系统通过调用控制平面接口,进而实现对存储系统控制平面的调用,这样就实现了应用负载对存储服务的接入、接出操作。当实现了存储系统接入后,应用负载可以直接访问存储系统的数据平面,即可以直接访问数据。
常见的云原生存储方案
1.公有云存储
每个公有云服务提供商都会提供各种云资源,其中也包含了各种云存储服务。以阿里云为例,其几乎提供了能够满足所有业务需要的存储类型,包括:对象存储、块存储、文件存储、数据库等等。公有云存储的优势是规模效应,足够大的体量实现了巨大研发、运维投入的同时,提供低廉的价格优势。而且公有云存储在稳定性、性能、扩展性方面都能轻松满足您的业务需求。
随着云原生技术的发展,各个公有云厂商都开始对其云服务进行云原生化改造或适配,提供更加敏捷、高效的服务来适应云原生应用的需求。阿里云存储服务也在云原生应用适配做了很多优化,阿里云容器服务团队实现的 CSI 存储驱动无缝的衔接了云原生应用和存储服务之间的数据接口。实现了用户使用存储资源时对底层存储无感知,而专注于自己的业务开发。
优点如下所示:
- 高可靠性:多数云厂商都可以提供服务稳定性、数据可考虑下都非常优异的服务,例如:阿里云ebs提供了9个9的可靠性服务,为您的数据安全提供了强有力的基础保障能力;
- 高性能:公有云对不同的服务提供了不同等级的存储性能适配,几乎可以满足所有应用类型对存储性能的需求。阿里云 EBS 可以提供百万级别的 IOPS 能力,接近本地盘的访问性能。NAS 服务最大提供每秒数十 G 的吞吐能力,在数据共享的应用场景满足您的高性能需求。而 CPFS 高性能并发文件系统最高可以提供近 TB 级别的吞吐能力,更是可以满足一些极端高性能计算对存储的需求;
- 扩展性好:公有云存储服务一般都提供了容量扩容能力,让您在应用对存储的需求增加的时候可以动态的实现容量伸缩,且实现应用的无感知;
- 安全性高:不同的云存储服务都提供了数据安全的保护机制,通过 KMS、AES 等加密技术实现数据的加密存储,同时也实现了客户端到服务的链路加密方案,让数据传输过程中也得到加密保护;
- 成熟的云原生存储接口:提供了兼容所有存储类型的云原生存储接口,让您的应用无缝的接入不同存储服务。阿里云容器服务提供的 CSI 接口驱动已经支持了:云盘、OSS、NAS、本地盘、内存、LVM等多种存储类型,可以让应用无感知的访问任何的存储服务类型;
- 免运维:相对于自建存储服务来说,公有云存储方案省去了运维的难度
缺点如下所示:
- 定制化能力差:由于公有云存储方案需要服务所有用户场景,其能力主要集中在一些通用需求,而对某些用户个性化需求很难满足。
2.商业化云存储
在很多私有云环境中,业务方为了实现数据的高可靠性通常会购买商业化的存储服务。这种方案为用户提供了高可用、高效、便捷的存储服务,且运维服务、后期保障等也都有保证。私有云存储提供商也意识到云原生应用的普及,也会为用户提供完善的、成熟的云原生存储接口实现方案。
优点如下所示:
- 安全性好:私有云部署,可以从物理上实现数据的安全隔离;
- 高可靠、高性能:很多云存储提供商都是在存储技术上深耕多年,具有优异的技术能力和运维能力,其商业化存储服务可以满足多数应用的性能、可靠性的需求;
- 云原生存储接口:从多家存储服务提供商开源的项目可以看出,其对云原生应用的支持已经实现或者展开。
缺点如下所示:
- 贵:商业化的存储服务加个多数都很昂贵;
- 云原生存储接口兼容性:商业化的云原生存储接口都是针对其一家的存储类型。多数用户会使用不同的存储类型,而使用了不同家的存储服务,很难实现统一的存储接入能力。
3.自建存储服务
对于一些 SLA 要是不是很高的业务数据,很多公司都会选择使用自建的方式提供存储服务。业务方需要通过当前的开源的存储方案,并结合自建的业务需求进行方案选择。
- 文件存储:考虑 CephFS、GlusterFS、NFS 等方案。其中 CephFS,GlusterFS 在技术的成熟度上还需要进一步验证,且在高可靠、高性能场景上也存在不足。而 NFS 虽然已经成熟,但是自建集群在性能上很难达到高性能应用的需求。
- 块存储:例如 RBD、SAN 等是常见的块存储方案,技术也相对比较成熟,已经有较多的公司将其应用在自己的业务上。但其复杂度也相对很高,需要有专业的团队来运维支持。
优点如下所示:
- 业务匹配度高、灵活性好:可以在众多开源方案中选择最适合自己业务的方案,且可以在原生代码的基础上进行二次开发来优化业务场景;
- 安全性好:如果搭建在公司内部使用,则具有物理隔离的安全性;
- 云原生存储接口:常用的开源存储方案都可以在社区找到云原生存储接口的实现,且可以在其基础上进行开发、优化。
缺点如下所示:
- 性能欠佳:多数开源的存储方案其原生的性能表现并不是很好。当然您可以通过架构设计、物理硬件升级、二次开发等方案进行优化;
- 可靠性差:开源存储方案在可靠性方面无法和商业化的存储比较,所以更多场景是应用在 SLA 低的数据存储场景;
- 云原生存储插件鱼龙混杂:目前网上开源的云原生存储驱动版本众多,且质量参差不齐,有些项目存在 bug,且长期无人维护,所以使用时需要更多的甄别和调测工作;
- 专业的团队支撑:自己搭建的服务需要自己负责,面对并不是十分成熟的开源方案,需要组建一个具有较强技术能力的专业团队来运维、开发存储系统。
4.本地存储
一些业务类型不需要高可用分布式存储服务,而会选择使用性能表现更优的本地存储方案。
数据库类服务:对存储的 IO 性能、访问时延有很多的要求,一般的块存储服务并不能很好的满足这方面的需求。且其应用本身已经实现了数据的高可用设计,不再需要底层实现多副本的能力,即分布式存储的多副本设计对这类应用是一种浪费。
存储作为缓存:部分应用期望保存一些不重要的数据,数据在程序执行完成即可以丢掉,且对存储的性能要求较高,其本质是将存储作为缓存使用。云盘的高可用能力对这样的业务并没有太大的意义,且云盘在 IO 性能、价格方面的表现(相对本地盘)也没有优势。
所以本地盘存储在很多关键能力上要比分布式块存储弱很多,但在特定场景下仍然有其使用的优势。阿里云存储服务提供了基于 NVMe 的本地盘存储方案,以更好的性能表现和更低的价格优势,在特定的应用场景得到了用户的青睐。
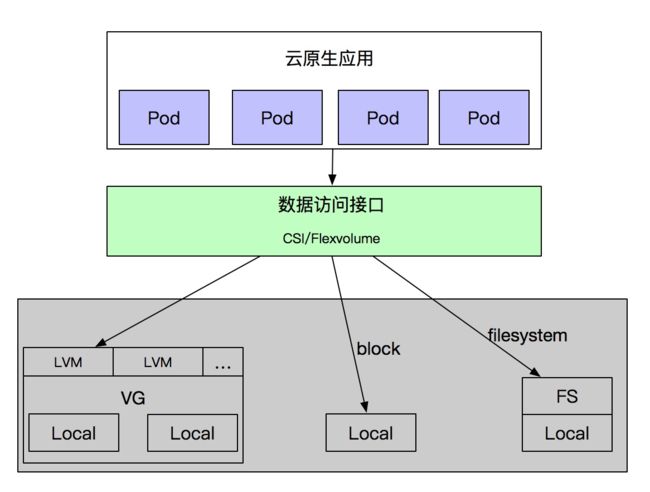
阿里云 CSI 驱动供了云原生应用使用本地存储的接入实现,支持:lvm 卷、本地盘裸设备、本地目录映射等多种接入形式,实现数据的高性能访问、quota、iops 配置等众多适配能力。
优点如下所示:
- 性能高:提供相对分布式存储更优的 IOPS、吞吐能力;
- 低价:通过物理裸设备直接提供本地盘,在价格上相对于多副本的分布式存储具有优势。
缺点如下所示:
- 数据可靠性差:本地盘保存的数据丢失后不能找回,需要从应用层实现数据的高可用设计;
- 灵活性差:不能像云盘一样实现数据迁移到其他节点使用。
5.开源容器存储
随着云原生技术的发展,社区提供了一些开源的云原生存储方案。
1)Rook
Rook 作为第一个 CNCF 存储项目,是一个集成了 Ceph、Minio 等分布式存储系统的云原生存储方案,意图实现一键式部署、管理方案,且和容器服务生态深度融合,提供适配云原生应用的各种能力。从实现上,可以认为 Rook 是一个提供了 Ceph 集群管理能力的 Operator。其使用 CRD 方式来对 Ceph、Minio 等存储资源进行部署和管理。
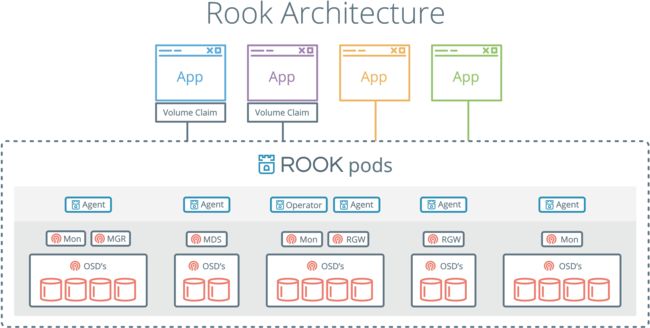
Rook 组件:
- Operator:实现自动启动存储集群,并监控存储守护进程,并确保存储集群的健康;
- Agent:在每个存储节点上运行,并部署一个 CSI / FlexVolume 插件,和 Kubernetes 的存储卷控制框架进行集成。Agent 处理所有的存储操作,例如挂载存储设备、加载存储卷以及格式化文件系统等;
- Discovers:检测挂接到存储节点上的存储设备。
Rook 将 Ceph 存储服务作为 Kubernetes 的一个服务进行部署,MON、OSD、MGR 守护进程会以 pod 的形式在 Kubernetes 进行部署,而 rook 核心组件对 ceph 集群进行运维管理操作。
Rook 通过 ceph 可以对外提供完备的存储能力,支持对象、块、文件存储服务,让你通过一套系统实现对多种存储服务的需求。同时 rook 默认部署云原生存储接口的实现,通过 CSI / Flexvolume 驱动将应用服务与底层存储进行衔接,其设计之初即为 Kubernetes 生态所服务,对容器化应用的适配非常友好。
Rook 官方文档参考:https://rook.io/
2)OpenEBS
OpenEBS 是一种模拟了 AWS 的 EBS、阿里云的云盘等块存储实现的开源版本。OpenEBS 是一种基于 CAS 理念的容器解决方案,其核心理念是存储和应用一样采用微服务架构,并通过 Kubernetes 来做资源编排。其架构实现上,每个卷的 Controller 都是一个单独的 Pod,且与应用 Pod 在同一个 Node,卷的数据使用多个 Pod 进行管理。
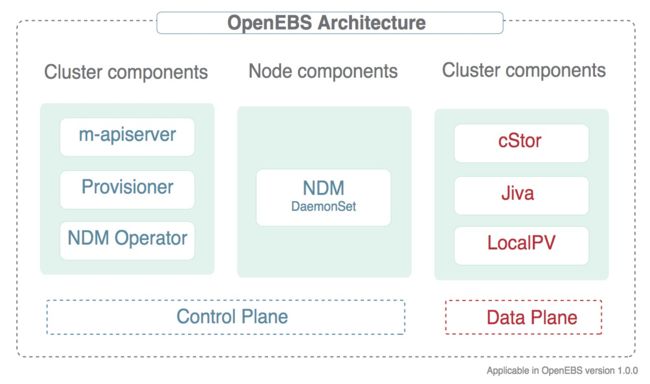
架构上可以分为数据平面(Data Plane)和控制平面(Control Plane)两部分:
- 数据平面:为应用程序提供数据存储;
- 控制平面:管理 OpenEBS 卷容器,通常会用到容器编排软件的功能;
数据平面:
OpenEBS 持久化存储卷通过 Kubernetes 的 PV 来创建,使用 iSCSI 来实现,数据保存在 node 节点上或者云存储中。OpenEBS 的卷完全独立于用户的应用的生命周期来管理,和 Kuberentes 中 PV 的思路一致。
OpenEBS 卷为容器提供持久化存储,具有针对系统故障的弹性,更快地访问存储,快照和备份功能。同时还提供了监控使用情况和执行 QoS 策略的机制。
控制平面:
OpenEBS 控制平面 maya 实现了创建超融合的 OpenEBS,并将其挂载到如 Kubernetes 调度引擎上,用来扩展特定的容器编排系统提供的存储功能;
OpenEBS 的控制平面也是基于微服务的,通过不同的组件实现存储管理功能、监控、容器编排插件等功能。
更多关于 OpenEBS 的介绍可以参考:https://openebs.io/
3)Heketi
类似于 Rook 是 Ceph 开源存储系统在云原生编排平台(Kubernetes)的一个落地方案,Glusterfs 同样也有一个云原生实践方案。Heketi 提供了一个 Restful 管理接口,可用于管理 Gluster 存储卷的生命周期。使用 Heketi,Kubernetes 可以动态地为 Gluster 存储卷提供任何支持的持久性类型。Heketi 将自动确定集群中 brick 的位置,确保在不同的故障域中放置 brick 及其副本。Heketi 还支持任意数量的 Gluster 存储集群,为云服务提供网络文件存储。
使用 Heketi,管理员不再管理或配置块、磁盘或存储池。Heketi 服务将为系统管理所有硬件,使其能够按需分配存储。任何在 Heketi 注册的物理存储必须以裸设备方式提供,然后 Heketi 在提供的磁盘上使用 LVM 进行管理。
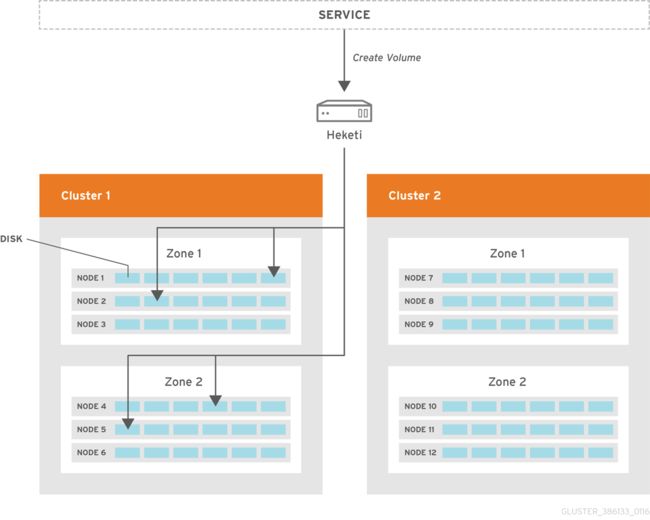
更多详解参考:https://github.com/heketi/heketi)
6. 优势
- 上述几种云原生存储方案其设计之初既充分考虑了存储与云原生编排系统的融合,具有很好的容器数据卷接入能力;
- 在 Quota 配置、QoS 限速、ACL 控制、快照、备份等方面有较好的云原生集成实现,云原生应用使用存储资源时更加灵活、便利;
- 开源方案,社区较为活跃,网络资源、使用方案丰富,让您更容易入手。
7. 劣势
- 成熟度较低,目前上述方案多在公司内部测试环境或者 SLA 较低的应用中使用,很少存储关键应用数据;
- 性能差:和公有云存储、商业化存储相比,上述云原生存储方案在 IO 性能、吞吐、时延等方面都表现欠佳,很难应用在高性能服务场景;
- 后期维护成本高:虽然上面方案部署、入门都很简单,但一旦运行中出现问题解决起来非常棘手。上述项目属于初期阶段,并不具备生产级别的服务能力,如果使用此方案需要有强有力的技术团结加以保障。
现状和挑战
1.敏捷化需求
云原生应用场景对服务的敏捷度、灵活性要求非常高,很多场景期望容器的快速启动、灵活的调度,这样即需要存储卷也能敏捷的根据 Pod 的变化而调整。
需求表现在:
- 云盘挂载、卸载效率提高:可以灵活的将块设备在不同节点进行快速的挂载切换;
- 存储设备问题自愈能力增强:提供存储服务的问题自动修复能力,减少人为干预;
- 提供更加灵活的卷大小配置能力。
2.监控能力需求
多数存储服务在底层文件系统级别已经提供了监控能力,然后从云原生数据卷角度的监控能力仍需要加强,目前提供的PV监控数据维度较少、监控力度较低;
具体需求:
提供更细力度(目录)的监控能力;
提供更多维度的监控指标:读写时延、读写频率、IO 分布等指标;
3.性能要求
在大数据计算场景同时大量应用访问存储的需求很高,这样对存储服务带来的性能需求成为应用运行效率的关键瓶颈。
具体需求:
- 底层存储服务提供更加优异的存储性能服务,优化 CPFS、GPFS 等高性能存储服务满足业务需求;
- 容器编排层面:优化存储调度能力,实现存储就近访问、数据分散存储等方式降低单个存储卷的访问压力。
4.共享存储的隔离性
共享存储提供了多个 Pod 共享数据的能力,方便了不同应用对数据的统一管理、访问,但在多租的场景中,不同租户对存储的隔离性需求成为一个需要解决的问题。
底层存储提供目录间的强隔离能力,让共享文件系统的不同租户之间实现文件系统级别的隔离效果。
容器编排层实现基于名词空间、PSP 策略的编排隔离能力,保证不同租户从应用部署侧即无法访问其他租户的存储卷服务。
- 赠书福利 -

6 月 12 日 17:00 前在“阿里巴巴云原生”公众号留言区欢迎大家讨论交流云原生存储新的机遇与挑战,精选留言点赞第 1 名即可免费获得此书!
课程推荐
为了更多开发者能够享受到 Serverless 带来的红利,这一次,我们集结了 10+ 位阿里巴巴 Serverless 领域技术专家,打造出最适合开发者入门的 Serverless 公开课,让你即学即用,轻松拥抱云计算的新范式——Serverless。
点击即可免费观看课程:https://developer.aliyun.com/learning/roadmap/serverless
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”
原文链接
本文为云栖社区原创内容,未经允许不得转载。