Linux学习--内存分配算法
一、Buddy算法
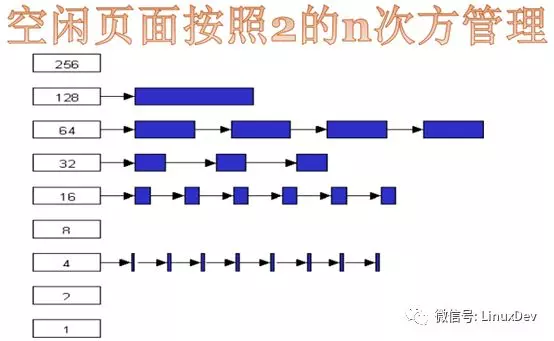
DMA(Direct Memory Access,直接内存存取)、常规、高端内存这3个区域都采用buddy算法进行管理,把空闲的页以2的n次方为单位进行管理,因此Linux最底层的内存申请都是以2n 为单位的。Buddy算法最主要的的特点任何时候区域里的空闲内存都能以2的n次方进行拆分或合并。
例如,假设ZONE_NORMAL有16页内存(24),此时有人申请一页内存,Buddy算法会把剩下的15页拆分成8+4+2+1,放到不同的链表中去。此时再申请4页,直接给4页,若再申请4页,则从8页中给4页,正好剩下4页。Buddy算法的精髓在于任何正整数都可以拆分成2的n次方之和。
通过/proc/buddyinfo可以看到内存空闲的一些情况:
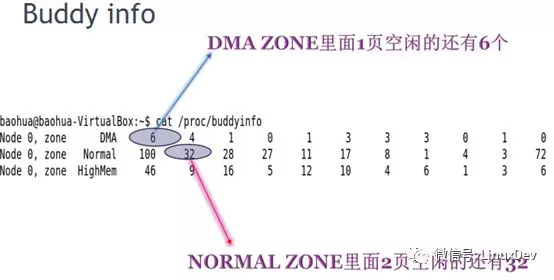
Buddy算法的优点是避免了内存的外部碎片,但是长期运行后,大片的内存会比较少,而1页,2页,4页这种内存会非常多,当我们分配大片连续内存的时候就会出问题。换句话说就是以产生内部碎片为代价来避免外部碎片的产生。 Linux针对大内存的物理地址分配,采用Buddy伙伴算法,如果是针对小于一个page的内存,频繁的分配和释放,则不宜用Buddy伙伴算法。
注:
“内部碎片”,是指系统已经分配给用户使用、用户自己没有用到的那部分存储空间;
“外部碎片”,是指系统无法把它分配出去供用户使用的那部分存储空间。
二、CMA算法
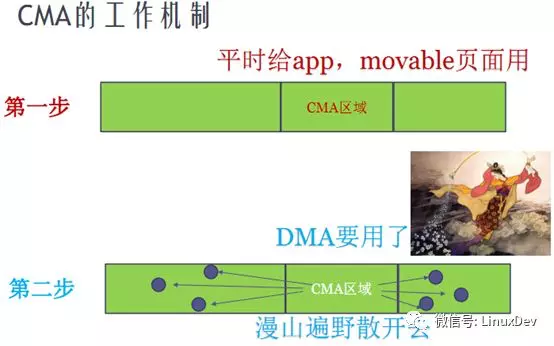
应用程序中申请一块内存,在应用程序看来是连续的,因为虚拟地址本身是连续的,但实际的内存空间中,所申请的这片内存未必是连续的,不过这对应用程序来说是没关系的,因为应用程序不需要关心实际的内存情况,只要MMU把物理地址映射成虚拟地址就好了。但是如果没有MMU的情况呢,我们又需要一片连续的内存空间,比如设备通过DMA直接访问内存,这种情况下应该怎么办呢?
CMA机制就是为了解决上面提到的问题而产生的。DMA zone并不是DMA专属,其它的程序也可以申请该zone的内存,如果当设备要申请DMA zone空间的一大片连续的内存时候,已经没有连续的大片内存了,只有1页,2页,4页的这种连续的小内存。解决办法就是我们标记某一片连续区域为CMA区域,这部分区域在没有大片连续内存申请的时候只给moveable的程序使用,当大片连续内存请求来的时候,我们去这片区域,把所有moveable的小片内存移动到其它的非CMA区域,更改对应的程序的页表,然后再把空出来的CMA区域给设备,从而实现了DMA大片连续内存的分配。
CMA机制并不是单独存在的,它通常服务于DMA设备,在设备调用dma_alloc_coherent函数申请一块内存后,为了得到一片连续的内存,CMA机制被调用,它保证了申请的内存的连续性。
另外CMA区域通常被分配在高端内存。
三、slab算法
前面我们了解了:Linux的最底层,由Buddy算法管理着所有的空闲页面,最小单位是2的0次方页,就是1页,4K,但是很多时候,我们为一个结构分配空间,也只需要几十个字节,按页分配无疑是浪费空间;另外,当我们频繁的分配和释放一个结构,我们希望在释放的时候,这部分内存不要立刻还给Buddy,而是提供一种类似C库的管理机制,在下一次在分配的时候还可以拿到同一块内存且保留着基本的数据结构。基于上面两点,Slab应运而生。总结一下,Slab主要提供以下两个功能:
-
对从Buddy拿到的内存进行二次管理,以更小的单位进行分配和回收(注意,是回收而不是释放),防止了空间的浪费。
-
让频繁使用的对象尽量分配在同一块内存区间并保留基本数据结构,提高程序效率。
那么,Slab是如何工作的呢?
如果某个结构被频繁的使用,内核源码就可以针对这个结构建立一个或者多个Slab分区(姑且这么叫),每一个Slab分区从Buddy拿到1页或者多页内存,并把这些内存划分为多个等分的这个结构大小的小块内存,这些Slab分区只用于分配给这个结构,通常称这个结构为object,每一次当有该object的分配请求,内核就从对应的Slab分区拿一小块内存给object,这样就实现了在同一片内存区间为频繁使用的object分配内存。请看下图
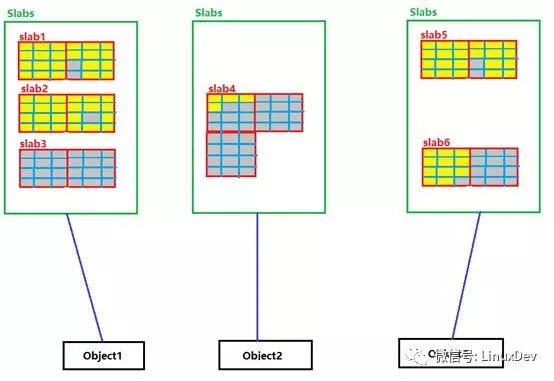
黑框表示频繁使用的结构;红框表示slab分区,一个结构内核可能为它分配一个或多个Slab;每个Slab分区有可能包含多个page,被分隔开的多个红框表示Slab分区的多个pages;蓝框表示Slab分区为对应的Object划分的一个一个的小内存块。填充黄色的框表示active的object,灰色填充的框表示未active的object,如果整个Slab分区的所有蓝框都是灰色的,表示这个Slab分区是未active的。
Linux为用户提供了Slab的文件查看接口,和命令接口,比如:
cat /proc/slabinfo:

slab主要分为两类:一类是内核里常用的数据结构,如TCPv6,UDPv6等,由于内核经常要申请和释放这类数据结构,所以就针对这些数据结构做一个slab,然后再次申请这类结构体时就总是从这个slab里来申请一个object(使用kmem_cache_alloc()申请)。另一类是一些小粒度的内存申请,如slabinfo中的kmalloc-16,kmalloc-32等(使用kmalloc()申请)。
上图所示为slabinfo文件的内容,针对表头解释下:
| 表头 | 解释 |
|---|---|
| Name | Object名字 |
| Active_objs | 已经激活的投入使用的object个数 |
| Num_objs | 为这个object分配的小内存块个数 |
| Objsize | 每一个内存块的大小 |
| Objperslab | 每一个Slab分区包含的object个数 |
| Pagesperslab | 每个Slab分区包含的page的个数 |
| Active_slabs | 已经激活的投入使用的Slab分区个数 |
| Num_slabs | 为这个object分配的Slab分区个数 |
最后再说一句,slab只用于分配低端内存,所分配的内存也只会被映射到物理内存映射区,所以vmalloc跟slab一毛钱关系都没有。
四、Slab与Buddy的关系
- slab与Buddy都是内存分配器。
- slab的内存来自Buddy
- slab与Buddy在算法上级别对等。Buddy把内存条当作一个池子来管理,slab是把从Buddy拿到的内存当作一个池子来管理的。
参考:
https://blog.csdn.net/jus3ve/article/details/80028731
https://blog.csdn.net/juS3Ve/article/details/80035753