Linux下利用Valgrind工具进行内存泄露检测和性能分析
Valgrind通常用来成分析程序性能及程序中的内存泄露错误
一 Valgrind工具集简绍
Valgrind包含下列工具:
1、memcheck:检查程序中的内存问题,如泄漏、越界、非法指针等。
2、callgrind:检测程序代码的运行时间和调用过程,以及分析程序性能。
3、cachegrind:分析CPU的cache命中率、丢失率,用于进行代码优化。
4、helgrind:用于检查多线程程序的竞态条件。
5、massif:堆栈分析器,指示程序中使用了多少堆内存等信息。
6、lackey:
7、nulgrind:
这几个工具的使用是通过命令:valgrand --tool=name 程序名来分别调用的,当不指定tool参数时默认是 --tool=memcheck
二 Valgrind工具详解
1.Memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc、free、new、delete的调用都会被捕获。所以,它能检测以下问题:
1、对未初始化内存的使用;
2、读/写释放后的内存块;
3、读/写超出malloc分配的内存块;
4、读/写不适当的栈中内存块;
5、内存泄漏,指向一块内存的指针永远丢失;
6、不正确的malloc/free或new/delete匹配;
7、memcpy()相关函数中的dst和src指针重叠。
这些问题往往是C/C++程序员最头疼的问题,Memcheck能在这里帮上大忙。
例如:
- #include
- #include
- #include
- void test()
- {
- int *ptr = malloc(sizeof(int)*10);
- ptr[10] = 7; // 内存越界
- memcpy(ptr +1, ptr, 5); // 踩内存
- free(ptr);
- free(ptr);// 重复释放
- int *p1;
- *p1 = 1; // 非法指针
- }
- int main(void)
- {
- test();
- return 0;
- }
输出结果如下:
- ==4832== Memcheck, a memory error detector
- ==4832== Copyright (C) 2002-2010, and GNU GPL'd, by Julian Seward et al.
- ==4832== Using Valgrind-3.6.1 and LibVEX; rerun with -h for copyright info
- ==4832== Command: ./tmp
- ==4832==
- ==4832== Invalid write of size 4 // 内存越界
- ==4832== at 0x804843F: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== Address 0x41a6050 is 0 bytes after a block of size 40 alloc'd
- ==4832== at 0x4026864: malloc (vg_replace_malloc.c:236)
- ==4832== by 0x8048435: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832==
- ==4832== Source and destination overlap in memcpy(0x41a602c, 0x41a6028, 5) // 踩内存
- ==4832== at 0x4027BD6: memcpy (mc_replace_strmem.c:635)
- ==4832== by 0x8048461: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832==
- ==4832== Invalid free() / delete / delete[] // 重复释放
- ==4832== at 0x4025BF0: free (vg_replace_malloc.c:366)
- ==4832== by 0x8048477: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== Address 0x41a6028 is 0 bytes inside a block of size 40 free'd
- ==4832== at 0x4025BF0: free (vg_replace_malloc.c:366)
- ==4832== by 0x804846C: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832==
- ==4832== Use of uninitialised value of size 4 // 非法指针
- ==4832== at 0x804847B: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832==
- ==4832==
- ==4832== Process terminating with default action of signal 11 (SIGSEGV) //由于非法指针赋值导致的程序崩溃
- ==4832== Bad permissions for mapped region at address 0x419FFF4
- ==4832== at 0x804847B: test (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832== by 0x804848D: main (in /home/yanghao/Desktop/testC/testmem/tmp)
- ==4832==
- ==4832== HEAP SUMMARY:
- ==4832== in use at exit: 0 bytes in 0 blocks
- ==4832== total heap usage: 1 allocs, 2 frees, 40 bytes allocated
- ==4832==
- ==4832== All heap blocks were freed -- no leaks are possible
- ==4832==
- ==4832== For counts of detected and suppressed errors, rerun with: -v
- ==4832== Use --track-origins=yes to see where uninitialised values come from
- ==4832== ERROR SUMMARY: 4 errors from 4 contexts (suppressed: 11 from 6)
- Segmentation fault
从valgrind的检测输出结果看,这几个错误都找了出来。
2.Callgrind
和gprof类似的分析工具,但它对程序的运行观察更是入微,能给我们提供更多的信息。和gprof不同,它不需要在编译源代码时附加特殊选项,但加上调试选项是推荐的。Callgrind收集程序运行时的一些数据���建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
生成可视化的图形需要下载gprof2dot:http://http://jrfonseca.googlecode.com/svn/trunk/gprof2dot/gprof2dot.py
这是个python脚本,把它下载之后修改其权限chmod +7 gprof2dot.py ,并把这个脚本添加到$PATH路径中的任一文件夹下,我是将它放到了/usr/bin目录下,这样就可以直接在终端下执行gprof2dot.py了。
Callgrind可以生成程序性能分析的图形,首先来说说程序性能分析的工具吧,通常可以使用gnu自带的gprof,它的使用方法是:在编译程序时添加-pg参数,例如:
- #include
- #include
- void test()
- {
- sleep(1);
- }
- void f()
- {
- int i;
- for( i = 0; i < 5; i ++)
- test();
- }
- int main()
- {
- f();
- printf("process is over!\n");
- return 0;
- }
再执行gprof ./tmp | gprof2dot.py |dot -Tpng -o report.png,打开 report.png结果:
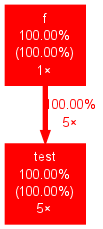
显示test被调用了5次,程序中耗时所占百分比最多的是test函数。
再来看 Callgrind的生成调用图过程吧,执行:valgrind --tool=callgrind ./tmp,执行完成后在目录下生成"callgrind.out.XXX"的文件这是分析文件,可以直接利用:callgrind_annotate callgrind.out.XXX 打印结果,也可以使用:gprof2dot.py -f callgrind callgrind.out.XXX |dot -Tpng -o report.png 来生成图形化结果:

它生成的结果非常详细,甚至连函数入口,及库函数调用都标识出来了。
3.Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
作一下广告:valgrind自身利用该工具在过去几个月内使性能提高了25%-30%。据早先报道,kde的开发team也对valgrind在提高kde性能方面的帮助表示感谢。
它的使用方法也是:valgrind --tool=cachegrind 程序名,
4.Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验阶段。
首先举一个竞态的例子吧:
- #include
- #include
- #define NLOOP 50
- int counter = 0; /* incremented by threads */
- void *threadfn(void *);
- int main(int argc, char **argv)
- {
- pthread_t tid1, tid2,tid3;
- pthread_create(&tid1, NULL, &threadfn, NULL);
- pthread_create(&tid2, NULL, &threadfn, NULL);
- pthread_create(&tid3, NULL, &threadfn, NULL);
- /* wait for both threads to terminate */
- pthread_join(tid1, NULL);
- pthread_join(tid2, NULL);
- pthread_join(tid3, NULL);
- return 0;
- }
- void *threadfn(void *vptr)
- {
- int i, val;
- for (i = 0; i < NLOOP; i++) {
- val = counter;
- printf("%x: %d \n", (unsigned int)pthread_self(), val+1);
- counter = val+1;
- }
- return NULL;
- }
这段程序的 竞态在30~32行,我们想要的效果是3个线程分别对全局变量累加50次,最后全局变量的值为150,由于这里没有加锁,很明显竞态使得程序不能达到我们的目标。我们来看Helgrind是如何帮我们检测到竞态的。 先编译程序:gcc -o test thread.c -lpthread ,然后执行:valgrind --tool=helgrind ./ test 输出结果如下:
49c0b70: 1
49c0b70: 2
==4666== Thread #3 was created
==4666== at 0x412E9D8: clone (clone.S:111)
==4666== by 0x40494B5: pthread_create@@GLIBC_2.1 (createthread.c:256)
==4666== by 0x4026E2D: pthread_create_WRK (hg_intercepts.c:257)
==4666== by 0x4026F8B: pthread_create@* (hg_intercepts.c:288)
==4666== by 0x8048524: main (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666==
==4666== Thread #2 was created
==4666== at 0x412E9D8: clone (clone.S:111)
==4666== by 0x40494B5: pthread_create@@GLIBC_2.1 (createthread.c:256)
==4666== by 0x4026E2D: pthread_create_WRK (hg_intercepts.c:257)
==4666== by 0x4026F8B: pthread_create@* (hg_intercepts.c:288)
==4666== by 0x8048500: main (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666==
==4666== Possible data race during read of size 4 at 0x804a028 by thread #3
==4666== at 0x804859C: threadfn (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666== by 0x4026F60: mythread_wrapper (hg_intercepts.c:221)
==4666== by 0x4048E98: start_thread (pthread_create.c:304)
==4666== by 0x412E9ED: clone (clone.S:130)
==4666== This conflicts with a previous write of size 4 by thread #2
==4666== at 0x80485CA: threadfn (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666== by 0x4026F60: mythread_wrapper (hg_intercepts.c:221)
==4666== by 0x4048E98: start_thread (pthread_create.c:304)
==4666== by 0x412E9ED: clone (clone.S:130)
==4666==
==4666== Possible data race during write of size 4 at 0x804a028 by thread #2
==4666== at 0x80485CA: threadfn (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666== by 0x4026F60: mythread_wrapper (hg_intercepts.c:221)
==4666== by 0x4048E98: start_thread (pthread_create.c:304)
==4666== by 0x412E9ED: clone (clone.S:130)
==4666== This conflicts with a previous read of size 4 by thread #3
==4666== at 0x804859C: threadfn (in /home/yanghao/Desktop/testC/testmem/a.out)
==4666== by 0x4026F60: mythread_wrapper (hg_intercepts.c:221)
==4666== by 0x4048E98: start_thread (pthread_create.c:304)
==4666== by 0x412E9ED: clone (clone.S:130)
==4666==
49c0b70: 3
......
55c1b70: 51
==4666==
==4666== For counts of detected and suppressed errors, rerun with: -v
==4666== Use --history-level=approx or =none to gain increased speed, at
==4666== the cost of reduced accuracy of conflicting-access information
==4666== ERROR SUMMARY: 8 errors from 2 contexts (suppressed: 99 from 31)
5. Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
Massif对内存的分配和释放做profile。程序开发者通过它可以深入了解程序的内存使用行为,从而对内存使用进行优化。这个功能对C++尤其有用,因为C++有很多隐藏的内存分配和释放。
此外,lackey和nulgrind也会提供。Lackey是小型工具,很少用到;Nulgrind只是为开发者展示如何创建一个工具。我们就不做介绍了。
三 使用Valgrind
Valgrind使用起来非常简单,你甚至不需要重新编译你的程序就可以用它。当然如果要达到最好的效果,获得最准确的信息,还是需要按要求重新编译一下的。比如在使用memcheck的时候,最好关闭优化选项。
valgrind命令的格式如下:
valgrind [valgrind-options] your-prog [your-prog options]
一些常用的选项如下:
| 选项 |
作用 |
| -h --help |
显示帮助信息。 |
| --version |
显示valgrind内核的版本,每个工具都有各自的版本。 |
| -q --quiet |
安静地运行,只打印错误信息。 |
| -v --verbose |
打印更详细的信息。 |
| --tool=<toolname> [default: memcheck] |
最常用的选项。运行valgrind中名为toolname的工具。如果省略工具名,默认运行memcheck。 |
| --db-attach= |
绑定到调试器上,便于调试错误。 |
