Google搜索引擎建立至今已经快20年了,之后全球各类大大小小类似的搜索引擎也陆续出现、消亡。国内目前以百度为大,搜狗、360、必应等也势在必争。搜索引擎技术也发展的相当成熟,同时也就出现了很多开源的搜索引擎系统。比如,Solr、Lucene、Elasticsearch、Sphinx等。
本文以sphinx search为例来介绍如何打造自己的搜索引擎。该搜索引擎的架构大致如下:
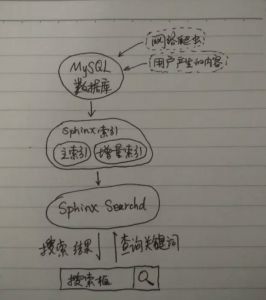
Sphinx search
Sphinx search 是俄罗斯人用C++写的,速度很快,可以非常容易的与SQL数据库和脚本语言集成,内置MySQL和PostgreSQL 数据库数据源的支持。其官方网站是: http://sphinxsearch.com/
可以说Sphinx支持包括英文、中文等所有语言的搜索。英文是以空格、标点符号来分割单词的,很容易切分。而中文词汇之间是没有空格的,很难区分,所以才有了自然语言处理中的“中文分词”技术的研究。Sphinx默认把中文按字拆分的,但这样就会产生搜索出不相干的内容来。比如,搜索“中国”,它会把同时包含“中”和“国”但不包含“中国”的文档搜出来。因此,有人就给Sphinx打了中文分词的补丁。
如果没有搞错的话,最早添加中文分词的是Coreseek,好像也是中文圈用得最广的支持中文分词的Sphinx,其它还有sphinx-for-chinese。然而这二者基于的Sphinx版本都太低了,有好多年没有更新。其中存在的一些Sphinx的bug也没有解决。
github上有一个基于Sphinx 2.2.9版本的代码库添加了中文分词: https://github.com/eric1688/sphinx 经测试,该版本稳定性和速度都要好于coreseek。当然它依然支持英文等其它语言的搜索,只是对中文搜索更加准确了。
Sphinx 安装
gitclonehttps://github.com/eric1688/sphinxcdsphinx#编译(假设安装到/usr/local/sphinx目录,下文同) ./configure --prefix=/usr/local/sphinx# 说明: --prefix 指定安装路径 --with-mysql 编译mysql支持 --with-pgsql 编译pgsql支持make sudo make install
安装好后,在/usr/local/sphinx目录下有以下几个子目录:
etc/ sphinx配置文件,不同的索引可以写不同的配置文件
bin/ sphinx程序,其中有建立索引的程序:indexer, 搜索守护进程:searchd
var/ 一般用了放置indexer索引好的文件
Sphinx索引的建立
MySQL数据库表结构
从上面的架构图可以看出来,我们要搜索的数据都存放在MySQL数据库中。假设我们的数据库名称叫blog_data,其中有个表叫article,表结构如下:
字段名说明
id文章唯一id(主键)
title文章标题
content文章内容
created_time文章创建时间
该article表可以是你本身网站的文本内容存放的表格,也可以是你的网络爬虫抓取到的数据存储表。
还有建立另外一个表sph_counter用来存储indexer已经索引的最大doc id
字段名说明
counter_id标记是对哪个表做记录
max_doc_id被索引表的最大ID
note注释,可以是表名
update_at更新时间
建立索引配置文件:
新建或修改/usr/local/sphinx/etc/blog.conf 配置文件:
source blog_main{ type = mysql sql_host = localhost sql_user = reader sql_pass = readerpassword sql_db = blog_data sql_port = 3306 sql_query_pre = SET NAMES utf8mb4 sql_query_pre = REPLACE INTO sph_counter SELECT 1, MAX(id), 'article', NOW() FROM article sql_query = SELECT id, title, content, \ UNIX_TIMESTAMP(created_time) AS ctime, \ FROM article \ WHERE id<=(SELECTmax_doc_idfromsph_counterWHEREcounter_id=1)sql_attr_timestamp=ctime#从SQL读取到的值必须为整数,作为时间属性}indexblog_main{source=blog_main#对应的source名称path=/user/local/sphinx/var/data/blog_maindocinfo=externmlock=0morphology=nonemin_word_len=1html_strip=0charset_type=utf-8chinese_dictionary=/user/local/sphinx/etc/xdict#中文分词的词典ngram_len=0stopwords=/user/local/sphinx/etc/stop_words.utf8}#全局index定义indexer{mem_limit=512M}#searchd服务定义searchd{listen=9900listen=9306:mysql41# 实时索引监听的端口read_timeout=5max_children=90max_matches=100000max_packet_size=32Mread_buffer=1Msubtree_docs_cache=8Msubtree_hits_cache=16M#workers=threads•dist_threads=2seamless_rotate=0preopen_indexes=0unlink_old=1pid_file=/usr/local/sphinx/var/log/blog_searchd_mysql.pidlog=/usr/local/sphinx/var/log/blog_searchd_mysql.logquery_log=/usr/local/sphinx/var/log/blog_query_mysql.log}
编辑好以上配置文件,就可以开始建立索引了:
cd/usr/local/sphinx/bin./indexer -c ../etc/blog.conf# 如果已经有searchd在运行了,就要加 --roate 来进行索引
索引建立后,就会在var/data/下面有名称前缀为blog_main.XXX的索引文件生成。
建立实时索引
上面的配置文件是建立一个静态索引,把当时数据库里面的所有数据进行索引。但是,你的数据库往往是不断增加新数据的。为了及时索引并搜索到最新加入的数据,就需要配置实时索引了。
index rt_weixin { type = rt path =/usr/local/sphinx/var/data/rt_blog rt_field = title rt_field = content rt_attr_timestamp = pubtime ngram_chars = U+3000..U+2FA1F#为了支持中文ngram_len =1}
该仓库代码的作者可能是忘了给实时索引加中文分词,如果不配置ngram_chars 参数就不能搜到中文,添加后搜索是按单字匹配的,可见作者确实是忘了给实时索引部分加中文分词。
添加以上实时索引后并不能搜索到实时数据。实时索引的更新/添加只能通过SphinxQL(一个类似MySQL的协议),所以还要写一个Python脚本,从数据库读取最新的数据并通过SphinxQL更新到实时索引。
import MySQLdb# 连接实时索引db_rt = MySQLdb.connect('127.0.0.1','nodb',# 对于实时索引来说,db,user,password都是不需要的,随便写。'noname','nopass', port=9306,# 实时索引监听的端口)# 向实时索引更新数据的函数def into_rt(index_name, item): cursor = db_rt.cursor() fields = item.keys()values= item.values() fieldstr =','.join(fields) valstr =','.join(["'%s'"] * len(item))fori in xrange(len(values)):ifisinstance(values[i], unicode):values[i] =values[i].encode('utf8') elif isinstance(values[i], datetime): try:values[i] =int(time.mktime(values[i].timetuple())) except: traceback.print_exc()printvalues[i]values[i] =int(time.time()) sql ='INSERT INTO %s (%s) VALUES(%s)'% (index_name, fieldstr, valstr)# print sqlsql = sql % tuple(values) try: cursor.execute(sql) db_rt.commit() except Exception, e:ife[0] ==1064:# ignore duplicated id errorpasselse: traceback.print_exc() raise'realtime index error'finally: cursor.close()
以上是及时建立实时索引的python程序的主要部分。可以把它设置成后台一直运行的守护程序,也可以在crontab里面配置每隔几分钟运行一次。
索引的更新
静态的主索引如果只建立一次,实时索引的数据量会越积越多,对实时索引的搜索带来很大压力,所以我们要定时重新建立主索引,清理实时索引。
清理实时索引的程序可以参考上面建立实时索引的python程序。
crontab 设置每天凌晨1点运行 indexer
crontab 设置indexer运行完毕后清理实时索引,并从新的max_doc_id开始建立实时索引
以上就是建立一个自己的搜索引擎的过程。更多配置细节可到官方网站参考文档。
文章来源于:猿人学网站的python教程。
***版权申明:若没有特殊说明,文章皆是猿人学原创,没有猿人学授权,请勿以任何形式转载。***
