一文读懂自监督学习

公众号关注 “视学算法”
设为 “星标”,DLCV消息即可送达!


来自 | 知乎
作者丨Sherlock
来源丨https://zhuanlan.zhihu.com/p/108625273
仅作学术交流,如有侵权,请联系删文
导读:最近 self-supervised learning 变得非常火,首先是 kaiming 的 MoCo 引发一波热议,然后最近 Yann 在 AAAI 上讲 self-supervised learning 是未来。所以觉得有必要了解一下 SSL,也看了一些 paper 和 blog,最后决定写这篇文章作为一个总结。

一、什么是 Self-Supervised Learning
首先介绍一下到底什么是 SSL,我们知道一般机器学习分为监督学习,非监督学习和强化学习。而 self-supervised learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务。其主要的方式就是通过自己监督自己,比如把一段话里面的几个单词去掉,用他的上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的 patch。
根据我看的文章,现在 self-supervised learning 主要分为两大类:1. Generative Methods;2. Contrastive Methods。下面我们分别简要介绍一下这这两种方法。
二、Generative Methods
首先我们介绍一下 generative methods。这类方法主要关注 pixel space 的重建误差,大多以 pixel label 的 loss 为主。主要是以 AutoEncoder 为代表,以及后面的变形,比如 VAE 等等。对编码器的基本要求就是尽可能保留原始数据的重要信息,所以如果能通过 decoder 解码回原始图片,则说明 latent code 重建的足够好了。

这种直接在 pixel level 上计算 loss 是一种很直观的做法,除了这种直接的做法外,还有生成对抗网络的方法,通过判别网络来算 loss。
对于 generative methods,有一些问题,比如:
基于 pixel 进行重建计算开销非常大;
要求模型逐像素重建过于苛刻,而用 GAN 的方式构建一个判别器又会让任务复杂和难以优化。
从这个 blog 中我看到一个很好的例子来形容这种 generative methods。对于一张人民币,我们能够很轻易地分辨其真假,说明我们对其已经提取了一个很好的特征表达,这个特征表达足够去刻画人民币的信息, 但是如果你要我画一张一模一样的人民币的图片,我肯定没法画出来。通过这个例子可以明显看出,要提取一个好的特征表达的充分条件是能够重建,但是并不是必要条件,所以有了下面这一类方法。

三、Contrasive self-supervised learning
除了上面这类方法外,还有一类方法是基于 contrastive 的方法。这类方法并不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨,就像上面美元的例子。
这类方法有如下的特点:1. 在 feature space 上构建距离度量;2. 通过特征不变性,可以得到多种预测结果;3. 使用 Siamese Network;4. 不需要 pixel-level 重建。正因为这类方法不用在 pixel-level 上进行重建,所以优化变得更加容易。当然这类方法也不是没有缺点,因为数据中并没有标签,所以主要的问题就是怎么取构造正样本和负样本。
目前基于 contrastive 的方法已经取得了很好的紧张,在分类任上已经接近监督学习的效果,同时在一些检测、分割的下游任务上甚至超越了监督学习作为 pre-train的方法。
下面是这两类方法的总结图片。

四、为什么需要 self-supervised learning
上面我们讲了什么是 self-supervised learning,那么为什么我们需要自监督学习呢,以及它能够给我们带来哪些帮助?
在目前深度学习发展的情况下,对于监督学习,我们希望使用更少的标注样本就能够训练一个泛化能力很好的模型,因为数据很容易获取,但是标注成本却是非常昂贵的。而在强化学习中,需要大量的经验对 agent 进行训练,如果能搞减少 agent 的尝试次数,也能够加速训练。除此之外,如果拿到一个好的特征表达,那么也有利于做下游任务的 fintuen和 multi-task 的训练。
最后我们总结一下监督学习和自监督学习的特点,其中 supervised learning 的特点如下:
对于每一张图片,机器预测一个 category 或者是 bounding box
训练数据都是人所标注的
每个样本只能提供非常少的信息(比如 1024 个 categories 只有 10 bits 的信息)
于此对比的是,self-supervised learning 的特点如下:
对于一张图片,机器可以预任何的部分
对于视频,可以预测未来的帧
每个样本可以提供很多的信息
所以通过自监督学习,我们可以做的事情可以远超过监督学习,也难怪 Yann 未来看好 self-supervised learning。目前出现的性能很好的文章主要是基于 contrastive 的方法,所以下面我们介绍几篇基于 contrastive 方法的文章。
五、Contrastive Predictive Coding
第一篇文章是 Representation Learning with Contrastive Predictive Coding(https://arxiv.org/abs/1807.03748)。这篇文章主要是通过 contrastive 的方式在 speech, images, text 和 在reinforcement learning 中都取得了很好的效果。
从前面我们知道,由一个原始的 input 去建模一个 high-level representation 是很难的,这也是自监督学习想做的事情。其中常用的策略是:future,missing 和 contextual,即预测未来的信息,比如 video 中当前帧预测后面的帧;丢失的信息或者是上下文的信息,比如 NLP 里面的 word2vec 和 BERT。
对于一个目标 x 和他的上下文 c 来说,直接去建模输出 p(x|c) 会损失很多信息,将 target x 和 context c 更合适的建模方式是最大化他们之间的 mutual information,即下面的公式:
优化了他们之间的互信息,即最大化 ,说明 要远大于 ,即在给定 context c 的情况下, 要找到专属于 c 的那个 x,而不是随机采样的 x。
基于这个观察,论文对 density ratio 进行建模,这样可以保留他们之间的互信息
对于这个 density ratio,可以构建左边的函数 f 去表示它,只要基于函数 f 构造下面的损失函数,优化这个损失函数就等价于优化这个 density ratio,下面论文会证明这一点。
而这个损失函数,其实就是一个类似交叉熵的函数,分子是正样本的概率,分母是正负样本的概率求和。
下面我们证明如果能够最优化这个损失函数,则等价于优化了 density ratio,也就优化了互信息。
首先将这个 loss 函数变成概率的形式,最大化这个正样本的概率分布,然后通过 bayesian 公式进行推导,其中 X 是负样本,和 以及 c 都无关。
通过上面的推导,可以看出优化这个损失函数其实就是在优化 density ratio。论文中把 f 定义成一个 log 双线性函数,后面的论文更加简单,直接定义为了 cosine similarity。
有了这个 loss,我们只需要采集正负样本就可以了。对于语音和文本,可以充分利用了不同的 k 时间步长,来采集正样本,而负样本可以从序列随机取样来得到。对于图像任务,可以使用 pixelCNN 的方式将其转化成一个序列类型,用前几个 patch 作为输入,预测下一个 patch。
 source: [blog]
source: [blog]
(https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html)

六、Deep InfoMax
通过上面的分析和推导,我们有了这样一个通用的框架,那么 deep infomax 这篇文章就非常好理解了,其中正样本就是第 i 张图片的 global feature 和中间 feature map 上个的 local feature,而负样本就是另外一张图片作为输入,非常好理解。
 source: [Learning deep representations by mutual information estimation and maximization]
(https://arxiv.org/abs/1808.06670)
source: [Learning deep representations by mutual information estimation and maximization]
(https://arxiv.org/abs/1808.06670)
七、Contrastive MultiView Coding
除了像上面这样去构建正负样本,还可以通过多模态的信息去构造,比如同一张图片的 RGB图 和 深度图。CMC 这篇 paper 就是从这一点出发去选择正样本,而且通过这个方式,每个 anchor 不仅仅只有一个正样本,可以通过多模态得到多个正样本,如下图右边所示。
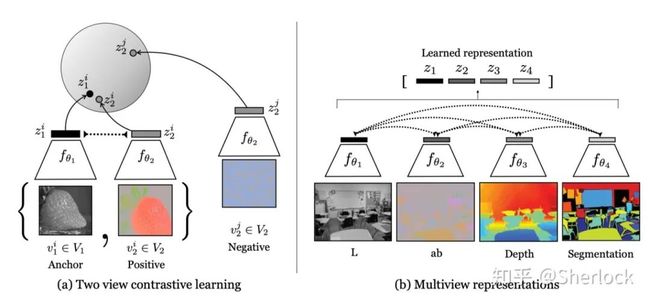
现在我们能够拿到很多正样本,问题是怎么获得大量的负样本,对于 contrastive loss 而言,如何 sample 到很多负样本是关键,mini-batch 里面的负样本太少了,而每次对图片重新提取特征又非常的慢。虽然可以通过 memory bank 将负样本都存下来,但是效果并不好,所以如何节省内存和空间获得大量的负样本仍然没有很好地解决。
八、MoCo
有了上面这么多工作的铺垫,其实 contrastive ssl 的大框架已经形成了,MoCo 这篇文章也变得很好理解,可以把 target x 看成第 i 张图片的随机 crop,他的正样本通过一个 model ema 来得到,可以理解为过去 epochs 对这张图片的 smooth aggregation。而负样本则从 memory bank 里面拿,同时 memory bank 的 feature 也是通过 model ema 得到,并且通过队列的形式丢掉老的 feature。
 source: [Momentum Contrast for Unsupervised Visual Representation Learning](https://arxiv.org/abs/1911.05722)
source: [Momentum Contrast for Unsupervised Visual Representation Learning](https://arxiv.org/abs/1911.05722)
MoCo 通过工程的方式,和一些 trick,比如 model ema 和 shuffleBN 来解决之前没法很好 sample 负样本的问题。
九、SimCLR
最近,hinton 组也放了一篇做 ssl 的 paper,其实都是用的同一套框架,也没有太多的 novelty。虽然摘要里面说可以抛弃 memory bank,不过细看论文,训练的 batchsize 需要到几千,要用32-128 cores 的 TPU,普通人根本用不起。
不过这篇文章系统地做了很多实验,比如探究了一下数据增强的影响,以及的 projection head 的影响等,不过也没有从理论上去解释这些问题,只是做了实验之后获得了一些结论。
十、Results
 source: [A Simple Framework for Contrastive Learning of Visual Representations] (https://arxiv.org/abs/2002.05709)
source: [A Simple Framework for Contrastive Learning of Visual Representations] (https://arxiv.org/abs/2002.05709)
最后展示了不同方法的结果,可以看到在性能其实已经逼近监督学习的效果,但是需要 train 4x 的时间,同时网络参数也比较大。
虽然性能没有超过监督学习,不过我认为这仍然给了我们很好的启发,比如训练一个通用的 encoder 来接下游任务,或者是在 cross domain 的时候只需要少量样本去 finetune,这都会给实际落地带来收益。
Reference
contrastive self-supervised learning,https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
deep infomax 和 深度学习中的互信息,https://zhuanlan.zhihu.com/p/46524857