卷积RBM源码解读
前言
卷积RBM相对RBM来说具有很多优势,详细的我也不说了,看文章就行。主要还是为了加深自己对细节部分的理解吧。
国际惯例,贴几个链接
卷积RBM的创始人Honglak Lee:http://web.eecs.umich.edu/~honglak/hl_publications.html#embc15
可以从他的主页上找到两篇与卷积RBM相关的文献,我也顺便传到CSDN上了,赚两个积分,嘿嘿:
第一篇:在2010年的那一栏的《Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations》
文章及代码下载:http://download.csdn.net/detail/zb1165048017/9683175
第二篇:在2010年的那一栏的《Unsupervised feature learning for audio classification using convolutional deep belief networks》
文章及代码下载:http://download.csdn.net/detail/zb1165048017/9683181
本片博客所解读的源码地址:https://github.com/lonl/CDBN
【注】此代码目前不支持步长大于1的卷积,因为matlab自带的conv卷积函数未提供对不同步长的卷积操作,需要自己修改。
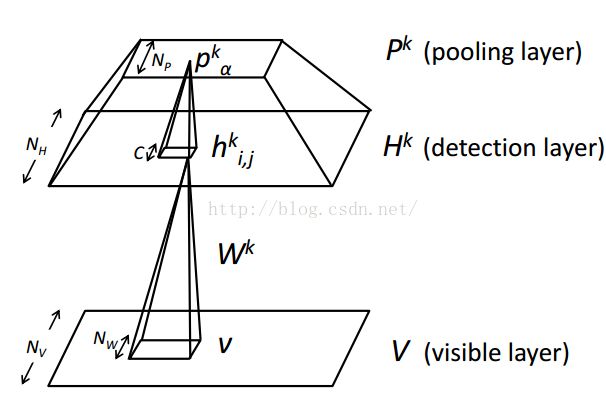
卷积RBM的模型与CNN的模型结构很类似:
第一步
分析主函数,主要是读取数据集,总共9张图片,这里训练的时候采用第一张图片,也可以同时读入两张图片进行重构。无需随机打乱图片,看到后面会发现有随机打乱zheyibuzhou
for i = 1:9
str = ['./data/MITcoast/image_000',num2str(i)];
str1 = strcat(str,'.jpg');
image = imread(str1);
image = double(image)/255;
train_data(:,:,i) = image;
end
train_data = reshape(train_data,[256,256,1,9]);
train_data = train_data(:,:,:,1:1);这里注意一下train_data的每个维度分别代表什么,前面两维表示输入图片的大小,第三个维度是通道数(比如彩色图片的通道就是3),第四个维度是输入的图片的个数(如果是输入两张,那么就可以写成"1:2")。然后初始化两层CRBM对应的参数(这里面重点注意n_map_v是指的通道数,而非图片个数):
layer{1} = default_layer2D(); % DEFAULT PARAMETERS SETTING,
% YOU CAN CHANGE THE PARAMETERS IN THE FOLLOWING LINES
layer{1}.inputdata = train_data;%输入数据
layer{1}.n_map_v = 1;%每张图片的通道数,可以根据train_data的第三个维度调整
layer{1}.n_map_h = 9;%卷积核个数
layer{1}.s_filter = [7 7];%卷积核大小
layer{1}.stride = [1 1]; %卷积步长,行方向和列方向
layer{1}.s_pool = [2 2];%池化
layer{1}.n_epoch = 10;%迭代次数
layer{1}.learning_rate = 0.05;%学习率
layer{1}.sparsity = 0.03;%稀疏化
layer{1}.lambda1 = 5;
layer{1}.lambda2 = 0.05;
layer{1}.whiten = 1;%是否进行白化处理
layer{1}.type_input = 'Gaussian'; % OR 'Gaussian' 'Binary'输入的是高斯还是二值数据
% SECOND LAYER SETTING
layer{2} = default_layer2D(); % DEFAULT PARAMETERS SETTING,
% YOU CAN CHANGE THE PARAMETERS IN THE FOLLOWING LINES
layer{2}.n_map_v = 9;
layer{2}.n_map_h = 16;
layer{2}.s_filter = [5 5];
layer{2}.stride = [1 1];
layer{2}.s_pool = [2 2];
layer{2}.n_epoch = 10;
layer{2}.learning_rate = 0.05;
layer{2}.sparsity = 0.02;
layer{2}.lambda1 = 5;
layer{2}.lambda2 = 0.05;
layer{2}.whiten = 1;
layer{2}.type_input = 'Gaussian';接下来便是根据设置的参数去训练卷积DBN
tic;
[model,layer] = cdbn2D(layer);
save('./model/model_parameter','model','layer');
toc;% THE FIRST LAYER POOLING MAPS
figure(1);
[r,c,n] = size(model{1}.output(:,:,:,1));
visWeights(reshape(model{1}.output(:,:,:,1),r*c,n)); colormap gray
title(sprintf('The first Pooling output'))
drawnow
% THE SECOND LAYER POOLING MAPS
figure(2);
[r,c,n] = size(model{2}.output(:,:,:,1));
visWeights(reshape(model{2}.output(:,:,:,1),r*c,n)); colormap gray
title(sprintf('The second Pooling output'))
drawnow
% ORIGINAL SAMPLE
figure(3);
imagesc(layer{1}.inputdata(:,:,:,1)); colormap gray; axis image; axis off
title(sprintf('Original Sample'));第二步
主函数中调用的的cdbn2D函数解读首先就是去训练第一层
layer{1} = preprocess_train_data2D(layer{1});
fprintf('layer 1:\n');
model{1} = crbm2D(layer{1});
str1 = sprintf('./model/model_%s_%s_%d',layer{1}.type_input,layer{1}.cpu,1);
save(str1,'model','layer'); for i = 2:length(layer)
fprintf('layer %d:\n',i);
layer{i}.inputdata = model{i-1}.output;
layer{i} = preprocess_train_data2D(layer{i});
model{i} = crbm2D(layer{i});
str1 = sprintf('./model/model_%s_%s_%d',layer{i}.type_input,layer{i}.cpu,i);
save(str1,'model','layer');
end第一部分是白化函数preprocess_train_data2D,第二部分是训练函数crbm2D
第三步
白化函数的解读:首先对输入数据进行裁剪,使得运动在经过卷积池化以后认为整数的大小,所以前面几行代码就是对图片长宽裁剪
mod_1 = mod((size(layer.inputdata,1)-layer.s_filter(1))/layer.stride(1)+1,layer.s_pool(1));
if mod_1~=0
layer.inputdata(1:floor(mod_1/2),:,:,:) =[];
layer.inputdata(end-ceil(mod_1/2)+1:end,:,:,:) =[];
end
mod_2 = mod((size(layer.inputdata,2)-layer.s_filter(2))/layer.stride(2)+1,layer.s_pool(2));
if mod_2~=0
layer.inputdata(:,1:floor(mod_2/2),:,:) =[];
layer.inputdata(:,end-ceil(mod_2/2)+1:end,:,:) =[];
endif layer.whiten
if strcmp(layer.type_input, 'Gaussian')
m = size(layer.inputdata,4);
n = size(layer.inputdata,3);
for i = 1 : m
for j =1 : n
layer.inputdata(:,:,j,i) = crbm_whiten(layer.inputdata(:,:,j,i));
end
end
end
endfunction im_out = crbm_whiten(im)
if size(im,3)>1
im = rgb2gray(im);
end
im = double(im);
im = im - mean(im(:));
im = im./std(im(:));
N1 = size(im, 1);
N2 = size(im, 2);
[fx fy]=meshgrid(-N1/2:N1/2-1, -N2/2:N2/2-1);
rho=sqrt(fx.*fx+fy.*fy)';
f_0=0.4*mean([N1,N2]);
filt=rho.*exp(-(rho/f_0).^4);
If=fft2(im);
imw=real(ifft2(If.*fftshift(filt)));
im_out = 0.1*imw/std(imw(:)); % 0.1 is the same factor as in make-your-own-images
end第四步
核心部分crbm2D函数的解读。跟RBM一样,首先一堆初始化
cpu = layer.cpu;
batchsize = layer.batchsize;
model.n_cd = layer.n_cd;
model.momentum = layer.momentum;
model.start_gau = layer.start_gau;
model.stop_gau = layer.stop_gau;
model.beginAnneal = Inf;
layer.s_inputdata = [size(layer.inputdata,1),size(layer.inputdata,2)];
% INITIALIZE THE WEIGHTS
model.W = 0.01*randn(layer.s_filter(1), layer.s_filter(2), layer.n_map_v, layer.n_map_h);%卷积核大小*卷积核个数*输入图个数
model.dW = zeros(size(model.W));
model.v_bias = zeros(layer.n_map_v, 1);%输入层偏置,就一个1*1的值
model.dV_bias = zeros(layer.n_map_v, 1);
model.h_bias = zeros(layer.n_map_h, 1);%隐藏层偏置是对每一个特征图都是1*1的值,所以总共是卷积核个数*1个偏置
model.dH_bias = zeros(layer.n_map_h, 1);
model.v_size = [layer.s_inputdata(1), layer.s_inputdata(2)];
model.v_input = zeros(layer.s_inputdata(1), layer.s_inputdata(2), layer.n_map_v,batchsize);%输入层大小是图片大小*输入图片个数*批大小
model.h_size = (layer.s_inputdata - layer.s_filter)./(layer.stride) + 1;
model.h_input = zeros(model.h_size(1), model.h_size(2), layer.n_map_h, batchsize);%隐层特征图大小*卷积核个数*每批数据个数
model.error = zeros(layer.n_epoch,1);
% ADD SOME OTHER PARAMETERS FOR TEST
model.winc = 0;
model.hinc = 0;
model.vinc = 0;
% NEED TO FIX THE STRIDE HERE
H_out = ((size(layer.inputdata,1)-layer.s_filter(1))/layer.stride(1)+1)/layer.s_pool(1);
W_out = ((size(layer.inputdata,2)-layer.s_filter(2))/layer.stride(2)+1)/layer.s_pool(2);
model.output = zeros([H_out, W_out,layer.n_map_h,size(layer.inputdata,4)]);%模型的输出就是特征图大小*卷积核个数*(所有批合起来的)总图片张数
% CREATING BATCH DATA
N = size(layer.inputdata,4);%总图片张数
numcases = size(layer.inputdata,4);
numbatches = ceil(N/batchsize);%分批以后的批数目
groups = repmat(1:numbatches, 1, batchsize);
groups = groups(1:N);
perm = randperm(N);
groups = groups(perm);%每次训练都会随机打乱输入图片
dW = zeros(size(model.dW));for i = 1:numbatches
batchdata{i} = layer.inputdata(:,:,:,groups == i);
end再对数据以及网络参数都进行预处理以后,就正式进入训练过程,正常训练方法:两个for循环,外层循环控制训练次数,内层循环控制每次训练所使用的分批数据集。而且这里我们只对matlab版本进行解读,有兴趣的也可以看看mex和cuda版本
for epoch = 1:layer.n_epoch
err = 0;
original_err=0;
sparsity = zeros(1,numbatches);
tic;
% FOR EACH EPOCH, ALL SAMPLES ARE COMPUTED
for i = 1:numbatches
batch_data = batchdata{i};
%-----------------------------------------------------------------%
switch cpu
case 'mex'
%----------------- HERE COMPLETE WITH MEX FUNCTION -----------%
[model_new] = crbm2D_batch_mex(model,layer,batch_data);
dW = model_new.dW;
model.v_sample = model_new.v_sample;
model.h_sample = model_new.h_sample;
model.h_sample_init = model_new.h_sample_init;
case 'cuda'
%-------------- HERE COMPLETE WITH CUDA FUNCTION ---------%
[model_new] = crbm2D_mex_cuda(model,layer,batch_data);
dW = model_new.dW;
model.v_sample = model_new.v_sample;
model.h_sample = model_new.h_sample;
model.h_sample_init = model_new.h_sample_init;
case 'matlab'
%-------------- HERE COMPLETE WITH MATLAB FUNCTION -------%
[model, dW] = calc_gradient2D(model,layer,batch_data);
end % switch第五步
前向推断部分,在RBM中经常称为positive phase,直白点就是利用可见层计算隐层的激活状态,函数名:crbm_inference2D
先回看一下model.h_input这个变量代表的是什么:
model.h_input = zeros(model.h_size(1), model.h_size(2), layer.n_map_h, batchsize);%隐层特征图大小*卷积核个数*每批数据个数首先是将所有的特征图初始化为0,并且记录下当前处理的批的数据量,也就是图片张数
model.h_input = zeros(size(model.h_input));
N = size(model.h_input,4);for k = 1:N
for i = 1 : layer.n_map_h
for j = 1 : layer.n_map_v
model.h_input(:,:,i,k) = model.h_input(:,:,i,k) + conv2(data(:,:,j,k),model.W(end:-1:1,end:-1:1,j,i),'valid');
end
model.h_input(:,:,i,k) = model.h_input(:,:,i,k) + model.h_bias(i);
end
end>> A=[1 2 3 4;5 6 7 8]
A =
1 2 3 4
5 6 7 8
>> A(end:-1:1,end:-1:1)
ans =
8 7 6 5
4 3 2 1
>> rot90(A,2)
ans =
8 7 6 5
4 3 2 1首先判断隐层是要求二值形式还是高斯形式,有不同的处理
if strcmp(layer.type_input, 'Binary')
h_input = exp(model.h_input);
else
h_input = exp(1.0/(model.start_gau^2).*model.h_input);
endfor k = 1:N
for i = 1:floor(row/y_stride)
offset_r = ((i-1)*y_stride+1):(i*y_stride);
if length(offset_r)==1 % for extreme size like [1,1]
offset_r = [offset_r, offset_r];
end
for j = 1:floor(col/x_stride)
offset_c = ((j-1)*x_stride+1):(j*x_stride);
if length(offset_c)==1
offset_c = [offset_c, offset_c];
endblock_val = squeeze(sum(sum(h_input(offset_r,offset_c,:,k)))); block_val = squeeze(sum(sum(h_input(offset_r,offset_c,:,k))));
block_val
block(offset_r,offset_c,:,k) = repmat(permute(block_val, [2,3,1]), numel(offset_r),numel(offset_c));
block(offset_r,offset_c,:,k)block_val =
3.9984
3.9621
4.0169
4.0007
3.9849
3.9979
3.9665
4.0175
3.9813
ans(:,:,1) =
3.9984 3.9984
3.9984 3.9984
ans(:,:,2) =
3.9621 3.9621
3.9621 3.9621
ans(:,:,3) =
4.0169 4.0169
4.0169 4.0169
ans(:,:,4) =
4.0007 4.0007
4.0007 4.0007
ans(:,:,5) =
3.9849 3.9849
3.9849 3.9849
ans(:,:,6) =
3.9979 3.9979
3.9979 3.9979
ans(:,:,7) =
3.9665 3.9665
3.9665 3.9665
ans(:,:,8) =
4.0175 4.0175
4.0175 4.0175
ans(:,:,9) =
3.9813 3.9813
3.9813 3.9813if strcmp(layer.type_input, 'Binary')
model.h_sample = exp(model.h_input)./(1+block);
else
model.h_sample = exp(1.0/(model.start_gau^2).*model.h_input)./(1+block);
end![]()
第六步
进入对比散度算法中的采样阶段。首先是利用隐层重构可见层crbm_reconstruct2D。
一开始就先计算一下隐层的激活状态
h_state = double(rand(size(model.h_sample)) < model.h_sample);model.v_input = zeros(size(model.v_input));
N = size(model.v_input,4);for k = 1:N
for i = 1:layer.n_map_v
for j = 1:layer.n_map_h
model.v_input(:,:,i,k) = model.v_input(:,:,i,k) + conv2(h_state(:,:,j,k),model.W(:,:,i,j),'full');
end
model.v_input(:,:,i,k) = model.v_input(:,:,i,k) + model.v_bias(i);
end
end最后就是如果我们需要二值的可见单元,就用sigmoid函数激活一下,如果是高斯单元,就是直接将反卷积的输出当做可见单元值即可
if strcmp(layer.type_input, 'Binary')
model.v_sample = sigmoid(model.v_input);
else
model.v_sample = model.v_input;
end第七步
就是反复进行吉布斯采样,简单点说就是不断重复第五步、第六步,知道达到设置的k步对比散度算法的值。至此我们能够得到第一次进入模型时候的模型状态和第k次采样以后的模型状态。利用这两种状态计算一下权重的更新梯度。需要注意的是计算的时候要先将隐单元的卷积核旋转180°,原因是在positive phase阶段,利用可见层推导隐藏层单元值的时候,对卷积核进行过旋转。
dW = zeros(size(model.W));
for i = 1 : layer.n_map_h
for j = 1 : layer.n_map_v
dW(:,:,j,i) = conv2(data(:,:,j,1),model.h_sample_init(end:-1:1,end:-1:1,i,1),'valid') ...
- conv2(model.v_sample(:,:,j,1),model.h_sample(end:-1:1,end:-1:1,i,1),'valid');
end
end第八步
更新模型参数,主要包含权重,可见层偏置,隐藏层偏置,对于高斯形式和二值形式都有不同的计算公式,先计算一下偏置更新梯度(权重更新梯度上一步计算了)
N = size(data,4);
dV_bias = squeeze(sum(sum(sum(data - model.v_sample,1),2),4));
dH_bias = squeeze(sum(sum(sum(model.h_sample_init - model.h_sample,1),2),4));可以发现,更新方法和RBM基本一模一样。来一个小插曲,先看看matlab的sum函数是如何对一个高维矩阵进行工作的。
A(:,:,1)=[1 2 3;4 5 6]
A(:,:,2)=[7 8 9;10 11 12]
A(:,:,3)=[13 14 15;16 17 18]sum(A)
ans(:,:,1) =
5 7 9
ans(:,:,2) =
17 19 21
ans(:,:,3) =
29 31 33>> sum(A,2)
ans(:,:,1) =
6
15
ans(:,:,2) =
24
33
ans(:,:,3) =
42
51>> sum(A,3)
ans =
21 24 27
30 33 36回到程序中偏置的更新,都是对四维矩阵加和,对dV_bias分析一下(对于dH_bias的分析是一样的):
假设输入的data是256*256*3*10,意思是输入了10张图片,每张图片大小是256*256,且为三通道RGB彩色图像
首先是计算一下原始图与重构图的差值,并进行加和,得到的矩阵应该是256*1*3*10:
sum(data - model.v_sample,1)sum(sum(data - model.v_sample,1),2)sum(sum(sum(data - model.v_sample,1),2),4)接下来看看对于二值情况的更新方法:
if strcmp(layer.type_input, 'Binary')
dW = dW/N;
dH_bias = dH_bias/N;
dV_bias = dV_bias/N;
model.dW = model.momentum*model.dW + (1-model.momentum)*dW;
model.W = model.W + layer.learning_rate*(model.dW - layer.lambda2*model.W);
penalty = 0;
model.dV_bias = model.momentum*model.dV_bias + (1-model.momentum)*dV_bias;
model.v_bias = model.v_bias + layer.learning_rate*(model.dV_bias - penalty*model.v_bias);
model.dH_bias = model.momentum*model.dH_bias + (1-model.momentum)*dH_bias;
model.h_bias = model.h_bias + layer.learning_rate*(model.dH_bias - penalty*model.h_bias);
model.h_bias = model.h_bias + layer.learning_rate*layer.lambda1*...
(squeeze(layer.sparsity-mean(mean(mean(model.h_sample_init,1),2),4)));
end①计算完毕加和以后,除以每批样本总数
②针对权重和偏置需要更新的梯度都是利用“动量项*①中的梯度+(1-动量项)*①中的梯度”进行计算的
③然后计算最终投入到下次迭代的模型参数:
首先是权重(有梯度惩罚项),计算方法是:
下次迭代需要的权重=当前迭代使用的权重+学习率*(上一步计算的权重梯度 - 梯度惩罚率*当前迭代使用的权重)
然后是可见层偏置(简单计算),计算方法是:
下次迭代的可见层偏置=当前迭代使用的可见层偏置+学习率*(上一步计算的可见偏置梯度)
最后是隐藏层偏置(有稀疏项),计算方法是:
中间变量=当前迭代使用的隐藏层偏置+学习率*(上一步计算的隐层偏置梯度)
下次迭代的隐藏层偏置=中间变量+学习率*稀疏惩罚*(稀疏项-原始输入重构得到的隐层单元值的均值)
最后看看对于高斯输入的梯度更新
if strcmp(layer.type_input, 'Gaussian')
N = size(model.h_sample_init,1) * size(model.h_sample_init,2) * layer.batchsize;
dW = dW/N - 0.01*model.W;
%dh = (squeeze(sum(sum(model.h_sample_init,1),2)) - squeeze(sum(sum(model.h_sample,1),2)))/N - 0.05*(squeeze(mean(mean(model.h_sample_init,1),2)) - 0.002);
dh = (squeeze(sum(sum(sum(model.h_sample_init,1),2),4)) - squeeze(sum(sum(sum(model.h_sample,1),2),4)))/N;
dv = 0;
model.winc = model.winc*model.momentum + layer.learning_rate*dW;
model.W = model.winc + model.W;
model.hinc = model.hinc*model.momentum + layer.learning_rate*dh;
model.h_bias = model.hinc + model.h_bias;
model.vinc = model.vinc*model.momentum + layer.learning_rate*dv;
model.v_bias = model.vinc + model.v_bias;
endN= size(model.h_sample_init,1) * size(model.h_sample_init,2) * layer.batchsize;权重的更新也同样是先计算被惩罚以后的梯度,然后直接计算被更新的最终权重
dW= dW/N - 0.01*model.W;
model.winc= model.winc*model.momentum + layer.learning_rate*dW;
model.W= model.winc + model.W;dh= (squeeze(sum(sum(sum(model.h_sample_init,1),2),4)) - squeeze(sum(sum(sum(model.h_sample,1),2),4)))/N;
model.hinc= model.hinc*model.momentum + layer.learning_rate*dh;
model.h_bias= model.hinc + model.h_bias;dv = 0;
model.vinc = model.vinc*model.momentum + layer.learning_rate*dv;
model.v_bias = model.vinc + model.v_bias;第九步
输出每次迭代的信息看看,包括稀疏程度、重构误差
sparsity(i) = mean(model.h_sample_init(:));
err1= (batch_data - model.v_sample).^2;
err= err + sum(sum(sum(sum(err1))));layer.start_gau = 0.2; % GAUSSIAN START
layer.stop_gau = 0.1; % GAUSSIAN END if (model.start_gau > model.stop_gau)
model.start_gau = model.start_gau*0.99;
end第十步
完成第一层卷积RBM的参数更新以后,计算一下进入下一层卷积RBM的输入值。同样只关注"matlab"部分,利用函数crbm_forward2D
很简单就是,与crbm_inference2D处理方法类似,都是利用positive phase的计算流程,唯一不同的是,这里需要考虑到批数据的批数,而在crbm_inference2D中每次迭代已经选定批数了。
先初始化相关参数,记录一下所有训练集的数量大小,当前层池化大小,以及隐层的特征大小。
n = size(data,4);
x_stride = layer.s_pool(2);
y_stride = layer.s_pool(1);
row = size(model.h_sample,1);
col = size(model.h_sample,2);output = zeros(floor(row/y_stride),floor(col/x_stride),layer.n_map_h,n);初始化完毕以后就需要进行计算了,按照彩色图像的计算方法,对每个通道卷积,然后求和
for i = 1:layer.n_map_h
for j =1:layer.n_map_v
model.h_input(:,:,i,1) = model.h_input(:,:,i,1) + conv2(batch_data(:,:,j,1),model.W(end:-1:1,end:-1:1,j,i),'valid');
end
model.h_input(:,:,i,1) = model.h_input(:,:,i,1) + model.h_bias(i);
end
block = crbm_blocksum2D(model,layer);
h_sample = 1-(1./(1+block));
output(:,:,:,k) = h_sample(1:y_stride:row, 1:x_stride:col,:);再后面就是DemoCDBN_Gaussian_2D.m主函数对每一层得到的特征图可视化的方法啦,与卷积RBM关系不大,就不写咯。
其实个人感觉这个第十步的核心部分(隐单元计算和池化层计算就是下面附录介绍的最大池化方法)
附录概率最大池化的理解
关于大牛Honglak Lee 提出的论文主要采用了一种概率最大池化的方法,表示看了代码以后和原文可能有点对不上号,按照代码说一下吧
主要函数就是multrand2.m,比较短,可以去开头提供的地址下载,我这里也直接粘贴出来
function [S P] = multrand2(P)
% P is 2-d matrix: 2nd dimension is # of choices概率最大池化的方法
%P是除以均值了
%S是进行激活以后的值,为0或者1
% sumP = row_sum(P);
sumP = sum(P,2);
P = P./repmat(sumP, [1,size(P,2)]);
cumP = cumsum(P,2);%计算各行累加值
% rand(size(P));
unifrnd = rand(size(P,1),1);
temp = cumP > repmat(unifrnd,[1,size(P,2)]);%输出0,1
%发现很神奇的地方,Sindx每一行4个单元至多有一个为1
Sindx = diff(temp,1,2);%对列求一阶偏导diff(A,m,n)对A按照n(1为列,2为行)求m阶导数
S = zeros(size(P));
S(:,1) = 1-sum(Sindx,2);%sum(A,2)是对行求和,得到一列数据
S(:,2:end) = Sindx;
%最终得到的S矩阵每一行有且仅有一个1
end
一般来说高层特征的检测需要逐步包含逐步增大的输入区域的信息。现有的转移不变性表示方法比如卷积神经网络经常包含两个步骤:
“检测层“”对之前层进行卷积得到一个特征检测器
“池化层”通过常数因子缩小检测层的表示。
具体来说就是,每个池化层单元计算的是检测层的一个小区域的最大激活值。利用最大池化方法可以使得高层的特征表示对于输入的小变动具有不变性,并且降低了计算负担。
最大池化一般用于前馈网络。相反这里对一个图片的生成模型比较感兴趣,支持从上往下和从下往上的推断。因此设计了一个生成模型,利用类似最大池化的推断方法。
假设可见层是V,检测层是H,池化层是P。那么H和P都有k个单元组,每个池化单元组大小是![]() 大小。
大小。
探测层的被池化块和对应的池化单元有一个潜在约束:探测层至多有一个单元被打开(激活),池化单元当且仅当一个探测单元激活的时候被激活。
另一种等价说法就是,我们可以考虑有![]() 个单元(被池化单元+对应的池化单元)作为一个独立随机变量:一个值代表所有探测单元被开启,还有一个值代表所有的单元被关闭。
个单元(被池化单元+对应的池化单元)作为一个独立随机变量:一个值代表所有探测单元被开启,还有一个值代表所有的单元被关闭。
简单地创建最大池化CRBM的能量函数就是:
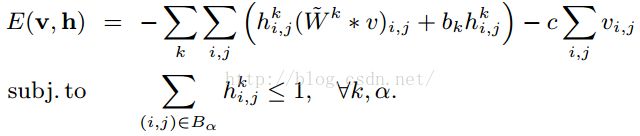
约束条件里面的![]() 代表的是在探测层H中被池化的一个小块,至多只有一个被激活为1。
代表的是在探测层H中被池化的一个小块,至多只有一个被激活为1。
探测层的第k组接受的输入是从V由下往上的输入信号,其实就是v乘以权重加上隐层偏置,没啥好理解的:
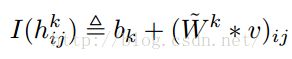
然后就是对这个隐层单元分块进行池化,假设![]() 是一个包含在块α中的隐单元,条件概率就是这样计算的
是一个包含在块α中的隐单元,条件概率就是这样计算的

第一个公式就是利用可见层得到隐层的激活概率,第二个是计算对应的池化单元被抑制的概率。其实这个第二个公式很好理解,按照可见层被池化块的几个单元有任意一个单元没激活的概率来计算。也就是说,第一个公式计算了其中一个单元被激活的概率,那么整个被池化块的探测层单元至少有一个被激活的概率就是

这样就计算出来了池化层被激活的概率,看看这个式子和上面第二个式子的和是等于1吧,代表被激活的概率加上被抑制的概率的和是1,因为只存在被激活和被抑制两种状态嘛。
然后看看代码,发现,好像并没有第一个公式提到的分母加1的情况。代码先将隐单元均值化,然后依次计算累加值,这样最后一行值就是1了,
sumP = sum(P,2);
P = P./repmat(sumP, [1,size(P,2)]);
cumP = cumsum(P,2);%计算各行累加值这个累加函数cumsum类似于这样
>> B=[1 2 3;4 5 6]
B =
1 2 3
4 5 6
>> cumsum(B,2)
ans =
1 3 6
4 9 15
>> 回到cump就会发现,每行的值都是依次增大的,然后在每一行利用一个概率去激活,可以得到在某个位置左边的值全是0,右边全是1,因为数值是依次增大。然后计算梯度,刚好在分界处得到一个1,其它地方都是0。
还是利用上面这个cumsum的例子,假设我们对结果的第一行用阈值2激活,第二行用阈值10激活,得到的结果就是
0 1 1
0 0 11 0
0 1最后问题又来了,按照文章描述,隐层至少有一个单元为1的时候,池化单元才被激活,也就是说在这个包含C*C的被池化部分和对应的池化单元的![]() 个单元里面,要么有两个1,要么全0,然而按照代码
个单元里面,要么有两个1,要么全0,然而按照代码
S(:,1) = 1-sum(Sindx,2);%sum(A,2)是对行求和,得到一列数据
S(:,2:end) = Sindx;用一个实例来体现这个最大池化函数multrand2的效用
>> A=rand(10,5)
A =
0.9604 0.3956 0.2853 0.3660 0.0691
0.7845 0.4872 0.2348 0.0293 0.3241
0.0900 0.3473 0.8310 0.2054 0.8044
0.5143 0.5906 0.9595 0.4494 0.6429
0.3923 0.7827 0.4778 0.3040 0.4732
0.9238 0.5114 0.5506 0.7581 0.0027
0.2364 0.5663 0.1936 0.4560 0.0749
0.2861 0.0362 0.5895 0.5049 0.2997
0.2368 0.1295 0.7861 0.6929 0.8848
0.3697 0.6487 0.8074 0.0170 0.7988
>> S=multrand2(A)
S =
1 0 0 0 0
0 1 0 0 0
0 0 0 1 0
0 0 0 0 1
0 1 0 0 0
1 0 0 0 0
0 0 0 1 0
0 0 0 1 0
0 0 1 0 0
0 0 0 0 1
>>