【caffe-Windows】关于LSTM的简单小例子
前言
这里主要是看到了一个简单的LSTM例子,比上一个coco简单很多,所以在这里记录一下,便于后续的分析,参考博客在上一篇文章的末尾提到过:Recurrent neural nets with Caffe
需要说明的是这个例子也并非原原本本的使用caffe自带的LSTM,而是加入了一些东西,所以我们还是得新增层
国际惯例,代码链接:
作者提供GitHub:https://github.com/christopher5106/last_caffe_with_stn
博主提供云盘:链接:http://pan.baidu.com/s/1i474Dd7 密码:31x8
第一步
首先对比一下两个proto,看看我们的caffe-Windows少了哪几个层。一般而言,操作多了就会发现,我们的第一反应去看看message LayerParameter这里面登记的ID,可以发现作者添加了以下几层:
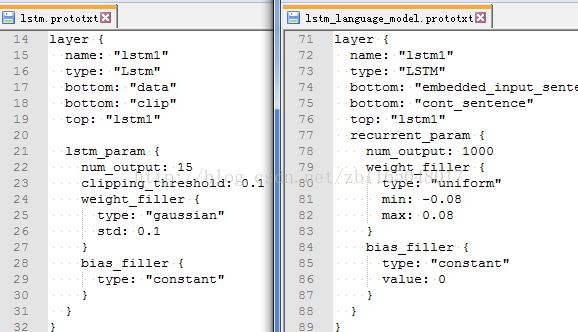
①LSTM层:对应lstm_layer.hpp和lstm_layer.cpp注意这个地方由于上一篇博客配置过LSTM,而且此处的LSTM与上一篇博客实现不同,所以最好是重新解压一个caffe-Windows执行添加层的操作
添加ID为
optional LSTMParameter lstm_param = 201;message LSTMParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
optional float clipping_threshold = 2 [default = 0.0];
optional FillerParameter weight_filler = 3; // The filler for weight
optional FillerParameter bias_filler = 4; // The filler for the bias
optional uint32 batch_size = 5 [default = 1];
}②Repeat层:对应repeat_layer.hpp和repeat_layer.cpp
添加ID为
optional RepeatParameter repeat_param = 202;message RepeatParameter {
optional uint32 num_repeats = 1; // The number of outputs for the layer
optional int32 axis = 2 [default = 1];
}添加ID为
optional PowerFileParameter power_file_param = 146;添加参数为
// added by Kaichun Mo
message PowerFileParameter {
optional string shift_file = 1;
}
添加ID为
optional LocLossParameter loc_loss_param = 147;message LocLossParameter {
required double threshold = 1;
}添加ID为
optional SpatialTransformerParameter st_param = 148;⑥STLoss层:对应st_loss_layer.hpp和st_loss_layer.cpp
添加ID为
optional STLossParameter st_loss_param = 145;message STLossParameter {
// Indicate the resolution of the output images after ST transformation
required int32 output_H = 1;
required int32 output_W = 2;
}无ID无参数
这一步的主要问题在于:
①新拷贝一个caffe-Windows再添加层,因为我第一次是将lstm_layer.hpp和lstm_layer.cpp都换了个名字,但是一直编译不成功出错。有C++大牛的话可以尝试一下,也算是一种挑战。
②添加层的方法没有写详细,强烈建议大家一层一层添加,否则很容易出错,而且你不知道错误原因何在。而且每一层添加完成测试的方法在上上篇博客有说明,就是单独对这个cpp编译会显示成功。
多句嘴:仔细、仔细、仔细
第二步
很多人在使用matlab接口的时候会说:“哎呀,咋有崩溃了啊”,“哎呀,又闪退了”,“又未响应了”。这种情况我的解决方法是使用exe调试,当然每个人有每个人的调试方法,都靠自己探索的。
所以第二步,先不在MATLAB中进行使用,而是测试一下我们书写的LSTM的prototxt文件是否正确,新手一般都会出现什么parameterfailed什么的错误,反正大概意思就是不存在这个层。那么你就得回到第一步再检查一遍了,提示的是谁,就检查谁
废话说多了,下面开始测试。使用的模型来源于参考博客,先看看网络结构
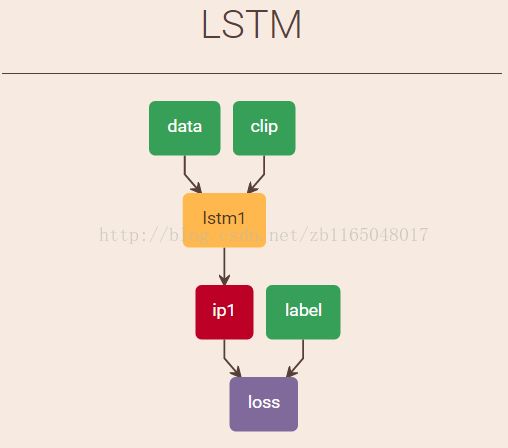
看着挺简单的,先介绍一下输入(从原始博客翻译过来):
data:是T*N*I维度,其中I代表序列每一步中数据的维度(例子中为1),T*N代表序列长度,其中N是batchsize批大小。约束是数据大小必须是N的整数倍
clip:是T*N维度,如果clip=0,隐状态和记忆单元就会被初始化为0,如果不是的话,之前的值将会被使用
label:每一步的预测输出
根据模型搭建网络(lstm.prototxt)如下:
name: "LSTM"
input: "data"
input_shape { dim: 320 dim: 1 }
input: "clip"
input_shape { dim: 320 dim: 1 }
input: "label"
input_shape { dim: 320 dim: 1 }
layer {
name: "Silence"
type: "Silence"
bottom: "label"
include: { phase: TEST }
}
layer {
name: "lstm1"
type: "Lstm"
bottom: "data"
bottom: "clip"
top: "lstm1"
lstm_param {
num_output: 15
clipping_threshold: 0.1
weight_filler {
type: "gaussian"
std: 0.1
}
bias_filler {
type: "constant"%偏置初始化为0
}
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "lstm1"
top: "ip1"
inner_product_param {
num_output: 1
weight_filler {
type: "gaussian"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "EuclideanLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
include: { phase: TRAIN }
}net: "lstm.prototxt"
test_iter: 1
test_interval: 2000000
base_lr: 0.0001
momentum: 0.95
lr_policy: "fixed"
display: 200
max_iter: 100000
solver_mode: CPU
average_loss: 200
#debug_info: trueE:\CaffeDev2\caffe-windows\Build\x64\Release\caffe.exe train -solver=solver.prototxt
pause看看我的目录结构,主要还是为了强调路径问题

如果这一步出错,请重新操作第一步
第三步
既然模型没问题了,那么就可以添加数据进行预测了。采用参考博文中的输入函数进行测试。
在此之前,参考前面的配置MATLAB接口的博文,确保自带的classification.m能够正常运行。
之后我们来测试一下模型预测效果:
①添加环境变量
clear
clc
addpath('../..')
caffe.reset_all
caffe.set_mode_cpusolver=caffe.Solver('solver.prototxt');>> solver
solver =
Solver (具有属性):
net: [1x1 caffe.Net]
test_nets: [1x1 caffe.Net]③创建数据集
a=0:0.01:32;
a=a(1:end-1);
d=0.5 * sin(2*a) - 0.05 * cos( 17*a + 0.8 ) + 0.05 * sin( 25 * a + 10 ) - 0.02 * cos( 45 * a + 0.3);
d = d / max(max(d), -min(d));
d = d - mean(d);niter=5000;
solver.net.blobs('clip').set_data(solver.net.blobs('clip').get_data*0+1);
train_loss =zeros(1,niter);
for i=1:niter
if mod(i,1000)==0
fprintf('iter=%d\n',i);
end
seq_idx = mod(i ,(length(d) / 320));
mid=solver.net.blobs('clip').get_data();
solver.net.blobs('clip').set_data([seq_idx > 0,mid(2:end)]);
solver.net.blobs('label').set_data(d( seq_idx * 320+1 : (seq_idx+1) * 320 ));
solver.step(1)
train_loss(i)= solver.net.blobs('loss').get_data();
endplot(1:niter,train_loss)
再测试一下
preds=zeros(length(d));
solver.test_nets.blobs('clip').set_data(solver.test_nets.blobs('clip').get_data*0+1)
for i=1:length(d)
mid2=solver.test_nets.blobs('clip').get_data();
solver.test_nets.blobs('clip').set_data([i>0,mid2(2:end)]);
solver.test_nets.forward_prefilled()
mid2=solver.test_nets.blobs('ip1').get_data();
preds(i)=mid2(1);
end
figure
plot(preds)
hold on
plot(d)
hold off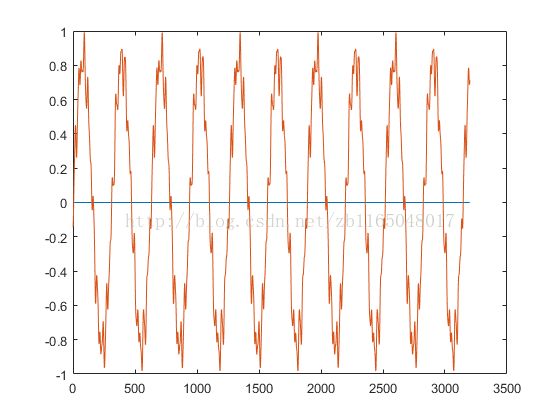
第四步
感觉和参考博文中的结果差距很大啊,去Python中测试一下
import caffe
solver = caffe.SGDSolver('solver.prototxt')
solver.net.params['lstm1'][2].data[15:30]=5
import numpy as np
a = np.arange(0,32,0.01)
d = 0.5*np.sin(2*a) - 0.05 * np.cos( 17*a + 0.8 ) + 0.05 * np.sin( 25 * a + 10 ) - 0.02 * np.cos( 45 * a + 0.3)
d = d / max(np.max(d), -np.min(d))
d = d - np.mean(d)
niter=5000
train_loss = np.zeros(niter)
solver.net.params['lstm1'][2].data[15:30]=5
solver.net.blobs['clip'].data[...] = 1
for i in range(niter) :
seq_idx = i % (len(d) / 320)
solver.net.blobs['clip'].data[0] = seq_idx > 0
solver.net.blobs['label'].data[:,0] = d[ seq_idx * 320 : (seq_idx+1) * 320 ]
solver.step(1)
train_loss[i] = solver.net.blobs['loss'].data
import matplotlib.pyplot as plt
plt.plot(np.arange(niter), train_loss)
solver.test_nets[0].blobs['data'].reshape(2,1)
solver.test_nets[0].blobs['clip'].reshape(2,1)
solver.test_nets[0].reshape()
solver.test_nets[0].blobs['clip'].data[...] = 1
preds = np.zeros(len(d))
for i in range(len(d)):
solver.test_nets[0].blobs['clip'].data[0] = i > 0
preds[i] = solver.test_nets[0].forward()['ip1'][0][0]
plt.plot(np.arange(len(d)), preds)
plt.plot(np.arange(len(d)), d)
plt.show()
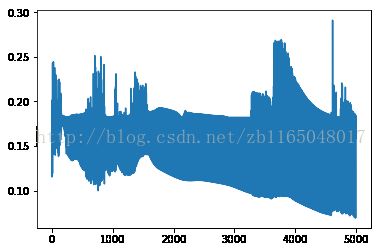
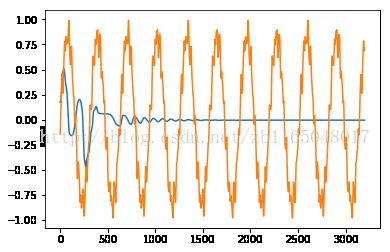
难道是作者博文写错了?这个以后再探讨。
总结:
通过这两个关于LSTM的博客发现,不同的人对LSTM的改编都有所不同,根据不同的任务,可以对LSTM做相应的改动,使用方法也不尽相同。
但是语法结构应该是相似的,对比一下两篇博文中关于LSTM层的写法可能就会有不同的收获