hadoop安装过程
hadoop适合海量大文件 海量小文件作用不大
centos通过华为镜像下载,阿里云用时有点问题
VMware 用的work Pro15 网盘上下载
虚拟机配置centos过程中问题:
子网:192.168.2.1 Windows:vmnet8 192.168.2.2 centos:192.168.2.3
配置方式1:网络中的编辑
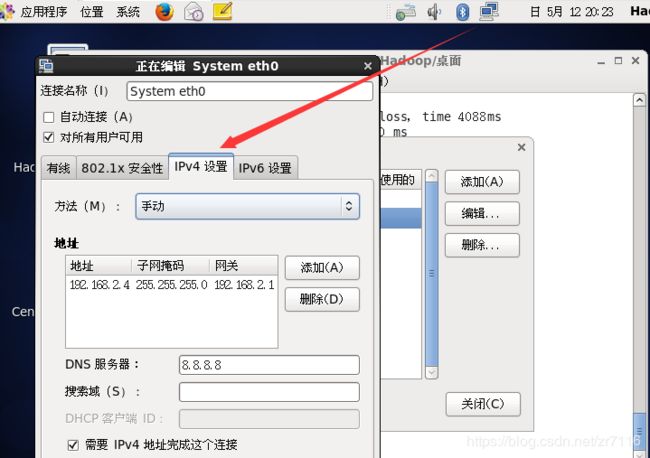
配置方式2:通过命令行
ifconfig:查看配置 setup:进入启动界面 有网络设置 防火墙设置 192.168.2.1尝试可以联网
通过Windows中的cmd ping:192.168.2.3尝试物理主机是否可以连接上的centos虚拟机
Windows可以ping通虚拟机就不需要图形界面了 因为节点一多机器内存吃不消 所以关闭图形界面 :
通过命令 init 3 使以后启动用字符界面 不用图形界面
1.通过secureCRT远程控制centos虚拟机 装Hadoop时用普通用户装 常用sudo更改系统配置 su命令切换到root 不会自己变回来除非用exit sudo :只有那一条指令用root身份执行后到用户身份 用于修改系统配置
在CRT中用的名字是这个是不是root 也不是centos 登录界面的那个名字
2.通过 vi /etc/inittab 文件更改启东时 是否用图形界面
3.第一次运行sudo 会有问题 因为没把他加入 /etc/sudoers
su =>vi /etc/sudoers 在 root all=(all) 下面加上Hadoop all=(all) all 使Hadoop中的sudo 具有权限
具有权限后运行 sudo vi /etc/inittab 中启动级别5项启动时图形界面改为 第3项启动时字符界面
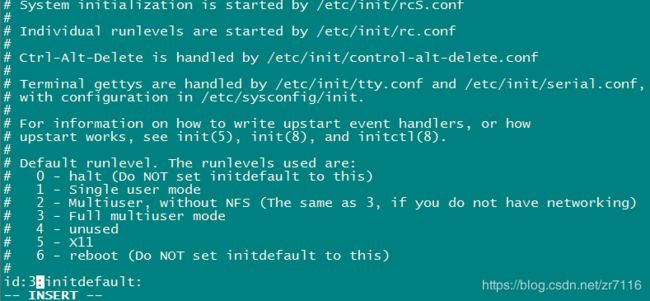 5图形界面改成3
5图形界面改成3
三。改主机名 现在主机名叫localhost 真实集群中要根据业务情况命名
通过 sudo vi /etc/sysconfig/network 更改主机名 =》sudo hostname weenend110 立即生效 =》exit 重新登录即改变主机名称
但weekend110对应哪个IP地址不知道 所以通过主机名不能直接访问机器
集群中有很多机器 我们最好能通过主机名进行访问 (通过域名解析器可以 也可以通过在本地一个配置文件中做解析 在本地将IP地址与主机名建立映射关系) 主机主机之间是通过主机名访问 因此映射文件集群中主机都应该有一份
sudo vi /etc/hosts =>ping wenkend110 ==ping 192.168.2.4 都可以ping通
通过fileZilla 上传文件 通过Alt+pi=》进入sftp执行命令行也可以实现 ==》 put 路径/文件名
ll 可以看文件列表
四。为了安装方便建立一个Hadoop的软件文件夹
mkdir app 将Hadoop相关的文件放入app
注: Linux mkdir 建立一个新的文件夹 rm命令用于删除一个文件或者目录。
rm -rf 要删除的文件名或目录 删除当前目录下的所有文件及目录,并且是直接删除,无需逐一确认命令行为
rm -rf p* d* Music/ Video/ Templates/ 删除了Hadoop下的p d 开头文件 以及Music video Templates
tar -zxvf 文件名 -c app/ 注:tar:解压缩文件指令 -z(采用哪种解压编码.gz) x(解压) v(打印进度) f(解压哪个文件) 后面是解压到的位置
把Java 放到系统环境变量中:sudo vi /etc/profile
在文件最后添加 export JAVA_HOME=/home/Hadoop/app/jdk1.8.0_25 (可以通过pwd print work Directory)
export PATH=$PATH:$JAVA_HOME/bin
刷新配置 source /etc/profile (原理是把文件当做shell脚本执行以下 所以export里面的文件生效)
五。Hadoop的安装 tab键可以补全目录
cd 可以切回主目录
Hadoop目录组成:
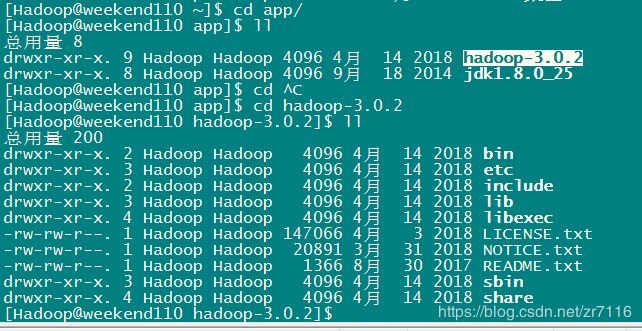
bin(binary 可执行脚本) sbin(系统相关的可执行脚本 Hadoop服务启动 停止相关的脚本) etc(配置文件)
lib (Java架包 Linux本地库) include(与本地库相关文件) share(大量Java架包)
share文件夹:架包分了好几个工程 comment hdfs mapreduce yarn ....
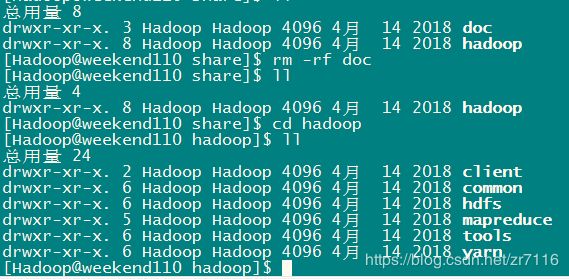
comment组件:hadoop 公共组件模块
hdfs组件:存储
MapReduce:运算模型
tools:工具类
yarn:资源调度工具
httpfs:2.4版本目录中有 通过HTTP协议访问hdfs的API
六.配置Hadoop解压文件下的 cd etc Hadoop/
1.hadoop-env.sh (cmd)是win的 :因为是Hadoop不用sudo直接: vi hadoop-env.sh 其中的JAVA_HOME变量 路径写死${java_home}=>/home/Hadoop/app/jdk1.8.0_25
2.hadoop启动时要涉及的文件 core-site.xml hdfs-site.xml httpfs.site.xml mapred.site.xml yarn.site.xml
3.配置参数 core-site.xml
Hadoop默认采用的文件系统 :
Hadoop的工作目录 Hadoop进程运行过程中产生的数据放到某个目录下存:
hdfs有两种节点:namenode datenode namenode 管理源数据
DataNode进程:把文件切块放到某个DataNode中 datanode就会把文件块管理起来 管理起来就是要存在Linux主机上面=》要有一个本地公共目录 可以单独指定也可以笼统指定一个=》上面就是配置Hadoop的公共目录
namenode管理源数据也是要存在本地 DataNode配一个目录 namenode配一个目录 =》目录应该是一个单独的磁盘挂载点=》方便挂在更多的磁盘 扩展容量
4.hdfs-site.xml 可以定文件切几块 块大小 vi hdfs-site.xml
大部分有默认值,
hdfs中有个replication =》副本数 客户端将数据存到hdfs =》hdfs会给我们村多个副本=这里指定副本数一般3 =》
上面两个文件写好以后hdfs就可以运行了
下面在陪下 yarn和MapReduce
MapReduce: