【论文阅读笔记】Multi-scale context aggregation by dilated convolutions
论文地址:https://arxiv.org/abs/1511.07122
代码地址:https://github.com/ndrplz/dilation-tensorflow
https://github.com/fyu/dilation 作者用caffe写的
introduction
motivation 动机
CNN的池化操作影响语义分割的精度
This prompts new questions motivated by the structural differences between image classification and dense prediction. Which aspects of the repurposed networks are truly necessary and which reduce accuracy when operated densely? Can dedicated modules designed specifically for dense prediction improve accuracy further?
虽然FCN通过改进CNN使原本用于图像分类的CNN在语义分割任务上有了很好的表现,但是由于图像分类和密集预测还是有区别的。
Modern image classification networks integrate multi-scale contextual information via successive pooling and subsampling layers that reduce resolution until a global prediction is obtained.
In contrast, dense prediction calls for multiscale contextual reasoning in combination with full-resolution output.
CNN的池化操作会减少resolution从而失去位置信息,这和语义分割的目标是冲突的。因为dense prediction 要求结合full-resolution全分辨率进行多尺度上下文推理。
前人针对池化操作影响精度这个问题提出的解决办法
通过反卷积操作恢复丢失的分辨率信息
针对这个问题,本文之前也提出了两种方法解决。
One approach involves repeated up-convolutions that aim to recover lost resolution while carrying over the global perspective from downsampled layers (Noh et al., 2015; Fischer et al., 2015).
主要思想就是为了恢复失去的分辨率加了up-convolutions。
《Learning deconvolution network for semantic segmentation.》和
《Learning optical flow with convolutional neural net- works.》都用了这种思想。
《Learning deconvolution network for semantic segmentation.》
https://cloud.tencent.com/developer/article/1008415 具体学习到时候看这篇笔记
This leaves open the question of whether severe intermediate downsampling was truly necessary。
这就引出一个疑问,中间下采样的操作是否是真的有必要的。
《Learning optical flow with convolutional neural net- works.》
提供多尺寸的输入图片,并将这些图片的预测结果进行组合。
Another approach involves providing multiple rescaled versions of the image as input to the network and combining the predictions obtained for these multiple inputs。
主要思想是 提供多尺寸的输入图片,并将这些图片的预测结果进行组合。
《 Learning hierarchical features for scene labeling.》、《Efficient piecewise training of deep structured models for semantic segmentation.》和《Scale-aware semantic image segmentation.》都用到了这种思想。
Again, it is not clear whether separate analysis of rescaled input images is truly necessary.
同样,这里存在一个问题,对不同尺寸输入的图片,是否需要对他们的结果单独进行分析。
所以我们就想用专门用于dense prediction的dedicated modules进一步改善语义分割的精度。
contribution 贡献
In this work, we develop a convolutional network module that aggregates multi-scale contextual information without losing resolution or analyzing rescaled images. The module can be plugged into existing architectures at any resolution. Unlike pyramid-shaped architectures carried over from image classification, the presented context module is designed specifically for dense prediction. It is a rectangular prism of convolutional layers, with no pooling or subsampling. The module is based on dilated convolutions, which support exponential expansion of the receptive field without loss of resolution or coverage.
我们提出了一个卷积网络模块,能够在不损失分辨率的情况下混合多尺度的上下文信息。然后这个模块能够以任意的分辨率被嵌入到现有的结构中(能够任意嵌入的原因就是他的输入和输出都是C个feature maps,即输入输出时相同的形式)。与从图像分类中延续的金字塔形结构不同,所呈现的上下文模块专门用于密集预测。它没有池化和下采样操作。我们的网络是它主要基于空洞卷积,其支持指数级扩展感受野而不损失分辨率或覆盖范围。 【也就是不需要下采样只用空洞卷积就可以获得较大感受野】
空洞卷积 DILATED CONVOLUTIONS
related work
In recent work on convolutional networks for semantic segmentation,
- Long et al. (2015) analyzed filter dilation but chose not to use it. 《Fully convolutional networks for semantic segmenta- tion.》
Long分析了dilation核但没有用 - Chen et al. (2015a) used dilation to simplify the architecture of Long et al. (2015).
《Semantic image segmentation with deep convolutional nets and fully connected CRFs.》
chen用了dilation简化了Long的网络结构。
In contrast, we develop a new convolutional network architecture that systematically uses dilated convolutions for multi-scale context aggregation.
我们研发了一个新的用空洞卷积的用于多尺寸信息融合的卷积网络。
预备知识(此部分不是论文的内容)
感受野
什么是感受野
感受野用来表示网络内部的不同位置的神经元对原图像的感受范围的大小,也就是能看到的输入图像的区域。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。

可以看到在Conv1中的每一个单元所能看到的原始图像范围是3*3,而由于Conv2的每个单元都是由2x2范围的Conv1构成,因此回溯到原始图像,其实是能够看到5x5的原始图像范围的。因此我们说Conv1的感受野是3,Conv2的感受野是5. 输入图像的每个单元的感受野被定义为1,这应该很好理解,因为每个像素只能看到自己。
感受野的计算方式
R F l + 1 = R F l + ( k e r n e l _ s i z e l + 1 − 1 ) ∗ f e a t u r e _ s t r i d e l RF_{l+1} = RF_l+(kernel\_size_{l+1}-1)*feature\_stride_l RFl+1=RFl+(kernel_sizel+1−1)∗feature_stridel
- RF表示特征感受野大小, R F 0 RF_0 RF0=1
- l表示层数 ,l=0表示输入层
- f e a t u r e s t r i d e l = ∏ i = 1 l s t r i d e i feature_stride_l=\prod_{i=1}^lstride_i featurestridel=∏i=1lstridei, f e a t u r e s t r i d e 0 feature_stride_0 featurestride0=1
使用传统卷积的话,感受野的增长是很慢的,需要多层卷积的堆叠。所以传统图像分类网络还引入了池化层,可以直接将感受野倍数扩大。但池化层的使用在增加感受野的同时还进行了下采样,丢失了很多细节信息。
空洞卷积
一句话概括空洞卷积:调整感受野(多尺度信息)的同时控制分辨率的神器。
什么是空洞卷积
空洞卷积其实就是有dilated filter的卷积,相比原来的标准卷积,空洞卷积(dilated convolution) 多了一个hyper-parameter(超参数)称之为dilation rate(扩张率),指的是kernel各点之前的间隔数量。这样在和原来有相同参数和计算量下拥有了更大的感受野。
下图所示为扩张率为2的3x3卷积核进行空洞卷积的动态过程,他和普通的3*3卷积核一样有9个参数,但感受野和5x5的卷积核相同。

空洞卷积的作用
- 扩大感受野:在deep net中为了增加感受野且降低计算量,总要进行降采样(pooling或s2/conv),这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测,分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
- 捕获多尺度上下文信息:空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。多尺度信息在视觉任务中相当重要啊。
dilated convolutions
F i + 1 = F i ∗ 2 i k i F_{i+1}=F_{i}*_{2^i}k_i Fi+1=Fi∗2iki for i = 0 , 1 , . . . , n − 2 i=0,1,...,n-2 i=0,1,...,n−2
公式就是说每个特征图都是由前一个feature map 通过空洞因子为 2 i 2^i 2i的3x3卷积核 k i k_i ki得来的。
计算感受野的两种方式:
①可以算出每一个在 F i + 1 F_{i+1} Fi+1的元素的感受野的大小是: ( 2 i + 2 − 1 ) × ( 2 i + 2 − 1 ) (2^{i+2}-1)\times(2^{i+2}-1) (2i+2−1)×(2i+2−1)
②卷积核大小kxk,dilation factor:n-推出感受野大小为:(k+1)x n - 1
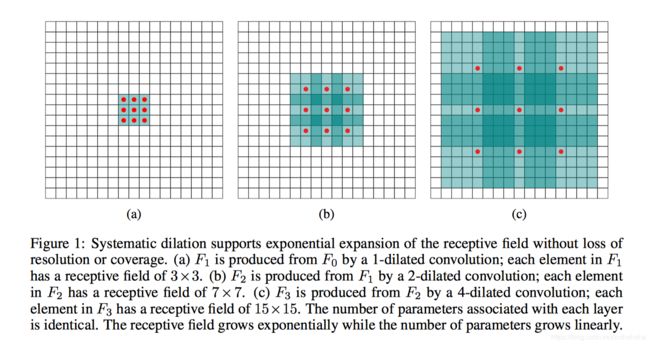
下图是查的别人对此图的解析

- (a)图对应3x3的空洞率为1的卷积,和普通的卷积操作一样,计算量是9个点。对于(a)这个feature map F1而言,F1是由1-dilated convolution 卷积F0得来的,如果不考虑之前层的感受野,那这个卷积核的感受野大小是3x3,也就是F1的每个元素的感受野都是3x3。
- (b)图对应3x3的空洞率为2的卷积,实际的计算量还是9个点。对于(b)这个feature map而言,(b)是对(a)空洞卷积而来的,卷积核覆盖的区域大小为5x5(图中蓝框),但是这个时候感受野大小并不是5x5,因为a中的元素的感受野就已经为3x3了,覆盖的5x5区域要往外多加(3-1)/2=1个像素,如(b)中红框所示。即1-dilated和2-dilated堆叠起来就能达到7x7的感受野,而普通卷积需要三层3x3的卷积层堆叠才能达到7x7的感受野。
- (c)图对应3x3的空洞率为4的卷积,实际的计算量还是9个点。同理,对于©而言,卷积核覆盖的(b)区域大小为9x9(图中蓝框),但是由于(b)中的元素的感受野大小为7x7,因此,在这个9x9的区域大小之外还要扩张出(7-1)/2=3个像素,如©中红框所示。即1-dilated、2-dilated、4-dilated堆叠起来就能达到15x15的感受野。
MULTI-SCALE CONTEXT AGGREGATION多尺寸语义信息融合
本节介绍了用来进行多尺寸信息融合的context Network architecture模型。模型有C通道的输入feature maps输入模型后,输出C通道的feature maps。就是因为输入和输出的通道数一样,我们的模型才能被任意嵌入到已经存在的dense prediction 结构中。
本文介绍了context Network architecture 的basic形式和large形式,large形式就是一个训练了一个更大的context Network,在更深的网络中更多数量的feature maps。
basic context Network architecture
网络结构
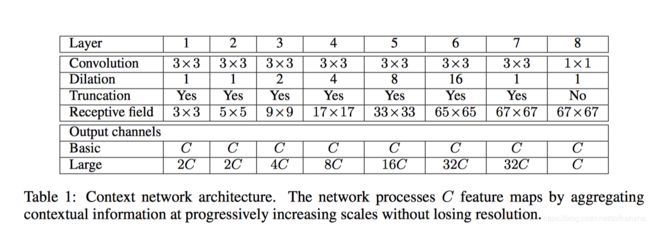
The basic context module has 7 layers that apply 3×3 convolutions with different dilation factors. The dilations are 1, 1, 2, 4, 8, 16, and 1. Each convolution operates on all layers: strictly speaking, these are 3×3×C convolutions with dilation in the first two dimensions. Each of these convolutions is followed by a pointwise truncation max(·, 0). A final layer performs 1×1×C convolutions and produces the output of the module.
下图为context Network architecture的基本结构,包含7层网络,其中使用了不同dilation factor的3x3的卷积。dilations分别为1,1,2,4,8,16,1,每层上都有卷积操作,也就是说在前两个维度都做3×3×C 空洞卷积 。
每层卷积后都接着一个像素级的截断处理,max(,0)。最后一层为1x1xC的卷积,并产生输出。
因为实验的输入为64x64的图片,在第六层的时候感受野已经是 65 × 65 65\times65 65×65了,所以在第六层之后就把dilation因子设为1,因为不需要再增加感受野了。
因为空洞卷积会扩大图像尺寸,所以在前7层进行了边缘剪裁。同时dilation 从小到大,也就是从小区域的感知来获得局部特征到大卷积将特征分配到更多的区域中。
初始化
随机采样分布初始化方式对我们不适用
Our initial attempts to train the context module failed to yield an improvement in prediction accuracy. Experiments revealed that standard initialization procedures do not readily support the training of the module. Convolutional networks are commonly initialized using samples from random distributions.
我们最开始尝试训练我们的context module的时候失败了,我们的实验表明标准的初始化方法不适用我们的空洞卷积。卷积网络一般用samples from random distributions随机采样分布初始化。
本文的初始化方式identity initialization
下式为本文basic模型采用的初始化方式identity initialization
k b ( t , a ) = 1 [ t = 0 ] 1 [ a = b ] k^b(t,a)=1_{[t=0]}1_{[a=b]} kb(t,a)=1[t=0]1[a=b]
其中a是输入feature map的index,b是输出feature map 的index
This initialization sets all filters such that each layer simply passes the input directly to the next.A natural concern is that this initialization could put the network in a mode where backpropagation cannot significantly improve the default behavior of simply passing information through. However, experiments indicate that this is not the case. Backpropagation reliably harvests the contextual information provided by the network to increase the accuracy of the processed maps.
这种identity初始化设置所有滤波器的值,这样每一层都能将前一层的信息直接传递到下一层。直觉上感到不利于反向传播信息的传递。但实验证明这种担心是多余的。
basic 的context module只有64 C 2 C^2 C2个参数,参数的数量非常少,但实验结果已经表现的非常好了
large context Network architecture
large context 有了更多的feature maps 具体数量如下图
![]()
We generalize the initialization scheme to account for the difference in the number of feature maps in different layers.
我们下面这个初始化方案去解决不同层的feature maps数量不同的问题。

其中 c i c_i ci和 c i + 1 c_{i+1} ci+1是分别是两个相邻层的feature maps的数量
Here ε ∼ N ( 0 , σ 2 ) ε ∼ N(0, σ_2) ε∼N(0,σ2)and σ < < C / c i + 1 σ <
随机噪声的使用打破了具有常见前身feature maps之间的联系。
front end 前端
front-end module的结构
我们训练了一个front-end prediction module。
- 输入:3通道的彩色图片
- 输出:21通道的 64 × 64 64\times64 64×64feature map
- 网络结构:基于VGG-16网络的改进,具体做法如下:
- 去除池化层
去掉VGG-16的最后两个池化层和striding layers(卷积网络中池化和子采样是分别实现的,一般所说的池化层其实就包含了这两个操作,因为pooling中一般stride=2)。
对于每一个移除的池化层后接的卷积层用dilation factor为2的空洞卷积。在final layers的卷积跟着所有移除的池化层,所以是被dilation factor为4的卷积。
通过空洞卷积可以利用原始分类网络的参数初始化,同时产生更高分辨率的输出。 - 用reflection padding
the buffer zone is filled by reflecting the image about each edge. - 去除中间feature map的padding
因为中间feature map的padding被用在原始分类网络,在dense prediction 中没必要也不合理。
- 数据集
Pascal VOC 2012 training set - 训练参数
基于SGD优化方法 ,mini-batch 大小是14,学习率是0.001,momentum是0.9。网络训练迭代了60000次。
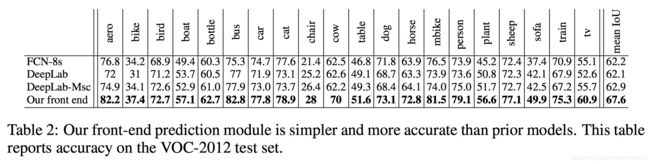
front-end module和其他网络比较的结果
FCN-8s、DeepLab和我们的front-end都是基于VGG-16进行改进的,我们就把这三种在VOC-2012上的表现进行比较。
 下表为在每一类上的精度。
下表为在每一类上的精度。
实验
front-end
训练被分为两个阶段:
- first stage
把VOC-2012和Microsoft COCO的图片放在一起训练。训练基于SGD优化,mini-batch为14,Momentum为0.9。以 1 0 − 3 10^{-3} 10−3的学习率执行100K迭代,以 1 0 − 4 10^{-4} 10−4的学习率执行40K后续迭代。 - second stage
只用VOC-2012的图片对网络进行fine-tuning。fine-tuning用 1 0 − 5 10^{-5} 10−5的学习率迭代50K次。VOC-2012的验证集没有用来进行训练。
只用了front-end 没有加context module精度就已经有了明显提升,这都归功于我们把原始网络中不适用于dense prediction的部分去掉了。
Controlled evaluation of context aggregation.
我们把basic和large context module 分别嵌入到front-end module中。具体就是在context module训练的时候把front-end的feature map作为输入。(因为context module的感受野为 67 × 67 67\times67 67×67,所以我们把输入的feature map进行了buffer宽为33的pad,其中zero padding和reflection padding对实验结果没影响)
Joint training of the context module and the front-end module did not yield a significant improvement in our experiments.
context module和front-end的训练结合在一起对实验结果不会有明显改善。也就是把front-end的训练结果给context module就好了,不用一起训练。
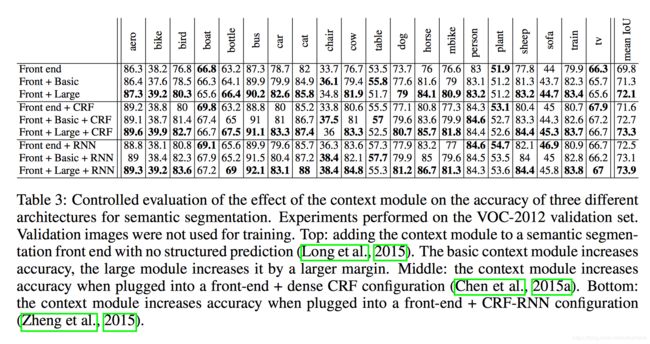
下表为把context module加入到三种不同的语义分割结构的结果,实验结果表明不管front-end后面加不加structured prediction,context module都对精度有明显的改善。

Evaluation on the test set.
下表为我们的模型在VOC-2012测试集进行评估的结果。其中Context指的是把larger context module嵌入到front-end后的模型。

conclusion
本文主要做了两个工作
- 利用空洞卷积设计了一个context module
我们的工作表明空洞卷积操作是适用于语义分割任务的,因为它能在不失去分辨率的情况下扩大感受野。 - 我们用空洞卷积设计的context module,然后将其嵌入到现有网络。
- 去除语义分割网络中用于图像分类的成分 front-end
作为这项工作的一部分,我们还表明,通过去除用于图像分类的多余成分,可以提高现有的用于语义分割的卷积网络的精度。
本文的front-end就是这样得到的。
一句话来讲本文的工作就是,通过去除现有网络的用于图像分类的部分得到front-end,然后利用空洞卷积设计了个context-module,把context-module嵌入到front-end中就是我们的网络结构(具体嵌入方式就是把front-end的feature map作为context module的输出)。
我们认为,本文的工作是朝着不受图像分类前人工作影响的密集预测专用体系结构迈出的一步。随着新的数据源的出现,未来的体系结构可能会得到密集的端到端训练,不再需要对图像分类数据集进行预训练。这可能使分割架构得到简化和统一。
问题
因为空洞卷积使得卷积核不连续,损失了连续性信息
虽然空洞(膨胀)卷积可以获取更大的视野,但是不利于小物体的分割