python文本挖掘(二)——实例1(TF-IDF算法)
分析小说《玩偶之家》
参考链接:
文本可视化[一]——《今生今世》词云生成与小说分析
实验过程
提取关键词
1.除了jieba本身的内置词库之外,自己人工添加在剧本《玩偶之家》中出现的较为特殊的人名、地名、机构名等。
以准确提取剧本中的关键词(人名、地名等)
如下是自己添加的词典内容dict_doll_house.txt:
海尔茂 10 nr
托伐 10 nr
娜拉 10 nr
爱伦 9 nr
安娜 9 nr
阮克 9 nr
林丹 9 nr
克立斯替纳 9 nr
柯洛克斯泰 9 nr
伊娃 6 nr
爱密 5 nr
巴布 5 nr
尼尔 5 nr
斯丹保家 4 ns
2.导入停用词词库
参考链接:
停用词库汇总、去重版
最全中文停用词表整理(1893个)
3.analyse.extract_tags采用TF-IDF算法进行关键词的提取
TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)算法。
参考链接:TF-IDF原理及使用
是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
一个词语在一篇文章中出现次数越多(TF), 同时在所有文档中出现次数越少(IDF), 越能够代表该文章。即:某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF = 在某一类中词条w出现的次数/该类中所有的词条数目
IDF = log(语料库的文档总数/(包含词条w的文档数+1))
TF−IDF=TF∗IDF
生成词云
参考链接:
Python数据可视化之Wordcloud
github
1.初始化WordCloud
WordCloud介绍
python非常优秀的词云展示第三方库。词云以词语为基本单位更加直观和艺术的展示文本。
2.生成词云
参考链接:
WordCloud词云自定义背景图片
wordcloud:自定义背景图片,生成词云
(1)一定要选择二值化图片(0和225),否则最终图片展示情况会很奇怪
生成的词会填充图的黑色部分
图像二值化(Image Binarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
(2)font_path=font_path
设置字体,若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字
(3)生成词云的两种方式
from text 文本生成
from frequencies 频率生成(本文所采用的方式)
调试问题集合
IndentationError: unindent does not match any outer indentation level
【已解决】Python脚本运行出现语法错误:IndentationError: unindent does not match any outer indentation level
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xb6 in position 14: illegal multibyte sequence
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xb7 in position 2069解决方法
NameError: name ‘unicode’ is not defined
Python NameError: name ‘unicode’ is not defined
python2中的unicode()函数在python3中会报错:
OSError: cannot open resource
还是字体文件路径问题,将\全部改为/
Python OSError: cannot open resource错误+解决方案
F:\python35\lib\site-packages\wordcloud\wordcloud.py:721: UserWarning: mask image should be unsigned byte between 0 and 255(掩码图像应为0到255之间的无符号字节). Got a float array warnings.warn("mask image should be unsigned byte between 0"
在此警告下(背景图片是自己生成的二值化图片)生成的词云:
(文件路径还是\时)
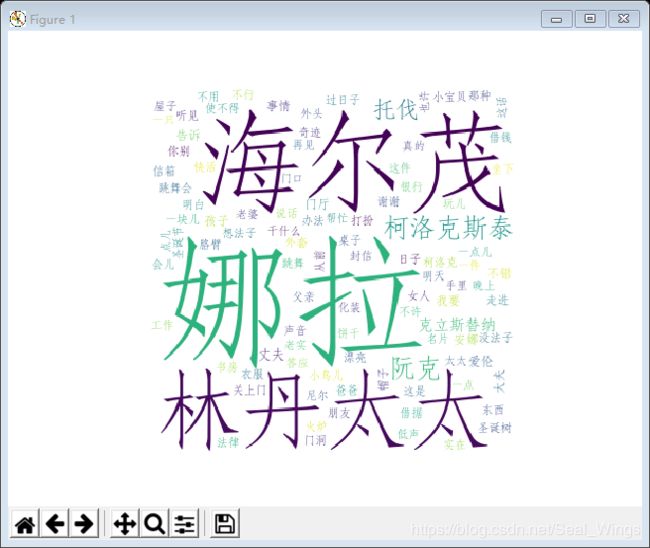
此处是我自己摸索出的解决方案:
将背景图片的路径替换为原图路径即可。
下面是词云效果图:

背景图片是自己生成的灰度图片
UserWarning: mask image should be unsigned byte between 0 and 255. Got a float array
warnings.warn(“mask image should be unsigned byte between 0”
实验结果
最终代码呈现
# -*- coding: utf-8 -*-
#textmining_2.py
from __future__ import print_function
#import os
#from os import path
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud
jieba.load_userdict("F:\python35\Lib\site-packages\jieba\dict_doll_house.txt")#通过再读剧本导入自己添加的词典
# 设置相关的文件路径
bg_image_path = "F:/geany_python_codes/analysis_py/binary_image/test_gray.png" # 二值化图片,决定生成词云时的图形形状
text_path = 'F:/geany_python_codes/analysis_py/textminingprojects/doll_house.txt' # 《玩偶之家》文本
font_path = 'F:/geany_python_codes/analysis_py/textminingprojects/example.ttf' # 字体
stopwords_path = 'F:/geany_python_codes/analysis_py/textminingprojects/stopword.txt'#停用词路径
def clean_using_stopword(text):
"""
去除停顿词,利用常见停顿词表+自建词库
:param text:
:return:
"""
mywordlist = []
# 用精确模式来分词
seg_list = jieba.cut(text,cut_all=False)
liststr = "/ ".join(seg_list)
with open(stopwords_path) as f_stop:
f_stop_text = f_stop.read()
f_stop_text = str(f_stop_text)
f_stop_seg_list = f_stop_text.split('\n')
for myword in liststr.split('/'): # 去除停顿词,生成新文档
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ''.join(mywordlist)
# sep’.join(seq)以sep作为分隔符,将seq所有的元素合并成一个新的字符串
def preprocessing():
"""
文本预处理
:return:
直接调用上面定义的函数
内容包括分词和去除停用词
"""
with open(text_path,'r',encoding='UTF-8') as f:
content = f.read()
return clean_using_stopword(content)
return content
def extract_keywords():
"""
利用jieba来进行中文分词。
analyse.extract_tags采用TF-IDF算法进行关键词的提取。
:return:
"""
'''
jieba.analyse.extract_tags()方法就是用来提取关键词的
参数依次为(文本,抽取关键词的数量,返回结果是否带权重,提取关键词的词性)
词云是需要根据权重来生成的因此withWeight为true
这里的权重就是tf-idf。
'''
# 抽取1000个关键词,带权重,后面需要根据权重来生成词云
allow_pos = ('nr',) # 词性
'''
allowPOS=allow_pos可以提取指定词性的关键词
“nr”为人物名词,“ns”为地点名词。
这样就可以生成散文集的人名词云和地点词云了。
'''
tags = jieba.analyse.extract_tags(preprocessing(), 100, withWeight=True)
keywords = dict()
for i in tags:
print("%s---%f" % (i[0], i[1]))
keywords[i[0]] = i[1]
return keywords
def draw_wordcloud():
"""
生成词云。
1.配置WordCloud。2.plt进行显示
:return:
"""
back_coloring = plt.imread(bg_image_path) # 设置背景图片
# 设置词云属性
'''
背景图片的画布一定要设置为白色(#FFFFFF)
然后显示的形状为不是白色的其他颜色。
可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
'''
wc = WordCloud(font_path=font_path, # 设置字体,若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字
background_color="white", # 背景颜色
max_words=2000, # 词云显示的最大词数
mask=back_coloring, # 设置背景图片
random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案
width=1000, #输出的画布宽度
height=500, #输出的画布高度
)
# 根据频率生成词云
wc.generate_from_frequencies(extract_keywords())
# 显示图片
plt.figure()
plt.imshow(wc)# 显示词云图
plt.axis("off")#off参数代表:Turn off axis lines and labels. Same as False.
'''
.axis是用来设置具体某一个坐标轴的属性的
.axes和subplot是差不多的,四个参数的话,前两个指的是相对于坐标原点的位置,后两个指的是坐标轴的长/宽度
'''
plt.show()#打开matplotlib查看器,并显示绘制的图形
# 保存到本地
wc.to_file("F:/geany_python_codes/analysis_py/textminingprojects/wordcloud.jpg")
if __name__ == '__main__':
draw_wordcloud()
结果呈现
1.词频截图展示

2.词云展示
