学习笔记——CDH
这几天学习了ApacheHadoop的大数据平台Cloudera Manager,不同于我之前使用的华为的大数据平台FusionInsight Manger,华为的大数据平台更加倾向于国企、政府公安还有一些大型公司,它的特点如下:1、可使用性高,华为研发人员已经把大数据平台封装好再去投入生产。2、后期售后质量高,当集群出现故障的时候,会有专门的运维人员进行维护。3、大数据平台性能高、稳定性好,一般华为的大数据平台都会搭配自己所研发的鲲鹏服务器,两者有着完美的契合度,使得在跑一些 MR任务上使得比同类的平台快点的道理。
但是华为大数据平台的价格昂贵,这点小微企业恐怕无法接受,接下来就是这次所讲的重点,ApacheHadoop的开源免费的大数据平台Cloudera Manager,只需要拥有三台服务器,就能搭建一个性能不错的大数据平台,并且是完全免费的,不需要投入过多的人力去维护它。
一、 CDH的介绍
Cloudera 的CDH和Apache原生的Hadoop的区别如下:
- CDH对版本的划分非常清晰,CDH共有5个版本,前三个版本已经不再更新,目前更新的两个版本为CDH4和CDH5,CDH4基于Hadoop2.0,CDH5基于Hadoop2.2-2.6,而原生的Apache Hadoop版本比较多,CDH相比原生Apache Hadoop做到版本统一管理。
- CDH相比原生Hadoop 在兼容性、安全性、稳定性上有较大改善,对Hadoop一些bug进行了修复,支持Kerberos安全认证,更新速度快且CDH文档完善清晰。
- CDH支持yum包,rpm包,tar包,Cloudera Manager几种方式安装,原生的Apache Hadoop只支持tar包安装。
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在短时间内部署好集群。
- 运维简单,提供了管理、监控、诊断、配置修改工具,管理配置方便,定位问题快速,准确,使运维工作简单高效。
CDH架构
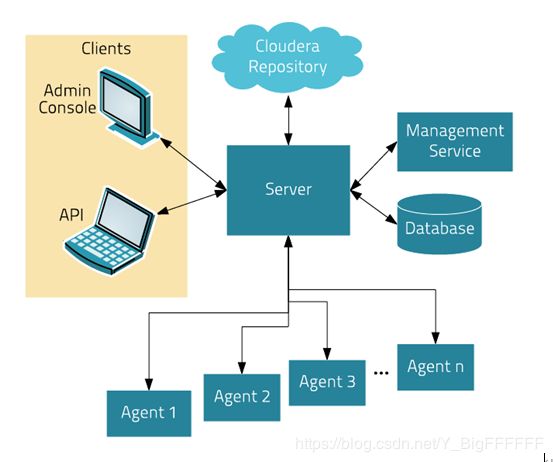
Server:Cloudera Manager 的核心是Cloudera Manager Server ,Server 管理控制台服务和托管应用程序逻辑,负责软件的安装、配置、服务的启动与关闭及管理集群。
Agent:安装在每台主机上。Agent负责进程的启动和停止,解压配置,触发安装及监控主机。
Management Service:由一组角色组成的服务,这些角色执行各种监视,警报和报告功能。
DataBase:存储配置及监控信息。
ClouderaRepository:Cloudera Manager 分发软件的存储库。
Clients:与Server交互的接口,有两部分,Admin Console :管理员web界面版。Api:用于开发者创建Cloudera Manager程序。
二、CDH的安装
安装CDH节点推荐内存为64G,大部分内存被Cloudera Management Service 占用,因为做了大量的数据分析和整合。
如果实际的物理机器内存为32G,推荐cm Server内存为16G,cm Agent内存分别为4G。
如果实际的物理机器内存为16G,推荐cm Server内存为10G,cm Agent内存分别为2G。
如果实际的物理机器内存为12G,推荐cm Server内存为8G,cm Agent内存分别为2G。
如果实际的物理机器内存为8G,推荐cm Server内存为6G,cm Agent内存分别为2G。
这是针对目前个人pc机学习CDH使用来划分的,实际机器内存不足,需要在VM虚拟机中设置允许交换内存,这样就可以借用在VM虚拟机节点中的磁盘空间。
Cloudera Manager的安装主要是 系统环境的准备和 Cloudera Manager的安装,这边安装过程过于复杂而且是搬运的工作,大家如果有需要我这会有详细的文档和视频并且会有一些资料包。
在安装完Cloudera Manager之后可以根据自己的需求安装大数据组件 hive spark之类的,当然,也要根据电脑的性能配置去选择性的安装,毕竟它是一个会一直在跑的程序,十分吃资源。
下面我会介绍三种比较常用的 hue、impala和oozie。
三、Hue
hue的介绍
HUE是一个开源的Apache Hadoop UI系统,早期由Cloudera开发,它是基于Python Web框架Django实现,后来贡献给开源社区。通过使用Hue我们可以通过浏览器方式操纵Hadoop集群,查看修改hdfs的文件,管理hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。
hue操作hive中的数据
登录hue之后,点击“Query Editors”->“Hive”,编写sql创建Hive表:

创建完成后,点击hive数据库刷新,可以看到刚才创建的Hive表:
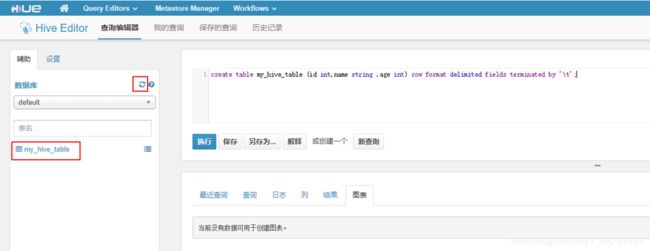
创建表完成之后,可以点击“Metastore Manager”,点击刚才创建的表名,可以导入数据,选择的数据可以是HDFS中也可以是本地中的文件数据:
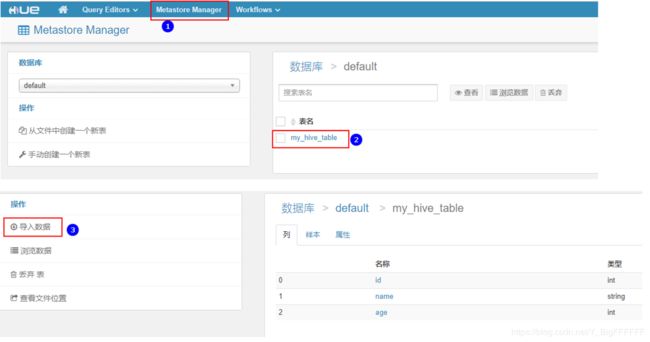
上传完数据之后,选择上传的数据,导入到表中。
点击浏览表中的数据如下:
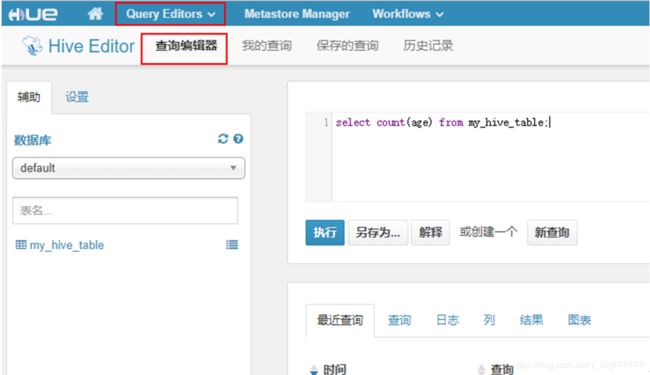
点击“Query Editors”,在查询编辑器中执行查询sql语句:
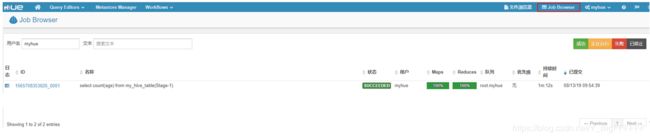
之后sql语句之后,hql转换成MR作业,可以点击“Job Browser”查看任务:
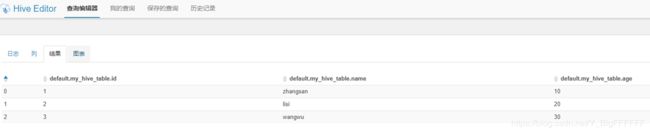
点击点击“Query Editors”->“Hive”->“查看结果”,可以看到任务执行的结果:

hue操作hdfs文件
可以创建新的文件,也可以修改,最好HDFS中大文件不要在hue中操作。hue中的用户默认是进入当前用户的主目录进行操作。
有了CDH大数据平台最好的这平台上操作,而不要在linux上操作,CDH会把操作修改的配置文件下发到所在的节点之中,并且具有稳定性
四、Impala
impala介绍
impala由Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。是CDH平台首选的PB级大数据实时查询分析引擎。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点就是基于内存处理数据,查询速度快。

impala架构
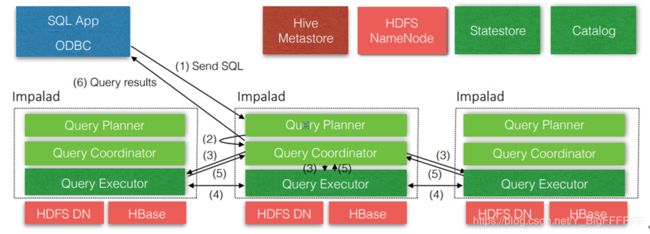
Impala主要有Impalad、State Store 、Catlog和CLI组成:
impalad
与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求,读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。
State Store
负责Quary的调度及跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后,因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据。
Catlog
当Impala集群启动后,负责从Hive MetaStore中获取元数据信息,放到impala自己的catalog中。
CLI
命令行客户端,提供给用户查询使用的命令行工具。
impala的优势
- 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
不需要把中间结果写入磁盘,省掉了大量的I/O开销(大数据的高可靠主要问题就是I/O)。最大限度的使用内存,中间结果不写磁盘,Impalad之间通过网络以stream的方式传递数据。 - 无需转换为MR,直接读取HDFS数据。
省掉了MR作业启动的开销,Impala直接通过相应的服务进程来进行作业调度,速度快。 - 兼容HiveSQL,可对Hive数据直接分析。
- 支持Data Local.
Impala支持Data Locality的I/O调度机制,尽可能的将数据和计算分配在同一台机器上执行,减少网络开销。 - 支持列式存储。
- 支持JDBC/ODBC远程访问(兼容性高)。
impala的劣势
- 存的依赖大,要求高(内存要求最好在64G以上)。
- 完全依赖Hive,不支持Hive的UDF和UDAF函数,不支持查询期的容错。
- 稳定性不如hive(毕竟在内存中直接跑)。
impala和hive的异同
相同点
impla与Hive使用相同的元数据,都支持将数据存储在HDFS和Hbase中,都是对SQL进行词法分析生成执行计划。
不同点
- 执行计划:
Hive:依赖与MapReduce执行框架,执行计划分为map->shuffle->reduce->map->shuffle->reduce…由于中间有很多次shuffle,SQL执行时间长。
Impala:执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad中执行查询,而不需要转换成MapReduce模式处理,保证impala有更好的并发性和避免不必要的中间sort和shuffle。 - 内存使用
Hive:在执行过程中如果内存放不下数据,则会使用磁盘,保证SQL能顺序执行完成,每一轮Map-Reduce执行结束后,中间结果也会落地磁盘。
Impala:在遇到内存放不下数据时,就会报错。这使impala处理数据有一定的局限性,最好与Hive配合使用。Impala在多个阶段之间利用网略传输数据,在执行过程中不会有写磁盘操作(insert除外)。 - 容错
Hive:依赖于Hadoop的容错能力(高可靠)。
Impala:整体来看,Impala容错一般,用户可以向任意一台impalad提交SQL查询。如果一个Impalad失效,在当前Impala上执行的所有SQL查询将失败,但是用户可以重新提交查询由其他的Impalad代替执行,不影响服务。在查询过程中,没有容错逻辑,如果执行过程中发生故障,则直接返回错误。对于Impala中的State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能在更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致SQL执行失败。 - 适用方面(应用场景的不同)
Hive:复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,对处理复杂的问题分析有局限性,与Hive配合使用,对Hive的结果数据集进行实时分析。
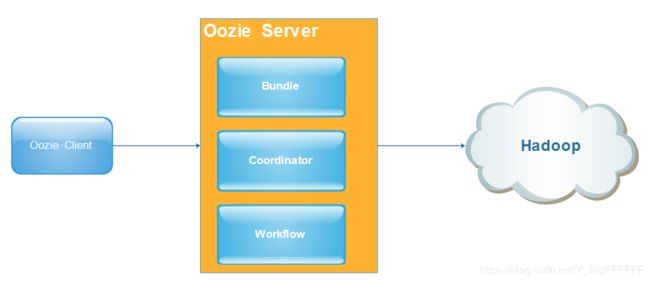
五、ooize
ooize的介绍
Oozie是用于 Hadoop 平台的开源的工作流调度引擎。 用来管理Hadoop作业。 属于web应用程序,由Oozie client和Oozie Server两个组件构成。 Oozie Server是运行于Java Servlet容器(Tomcat)中的web程序。相当于一个web ui。
ooize作为一个web端的控制台,对非程序员来说使用起来是非常简单的,其中原理稍加理解便可,更重要的还是去多使用。