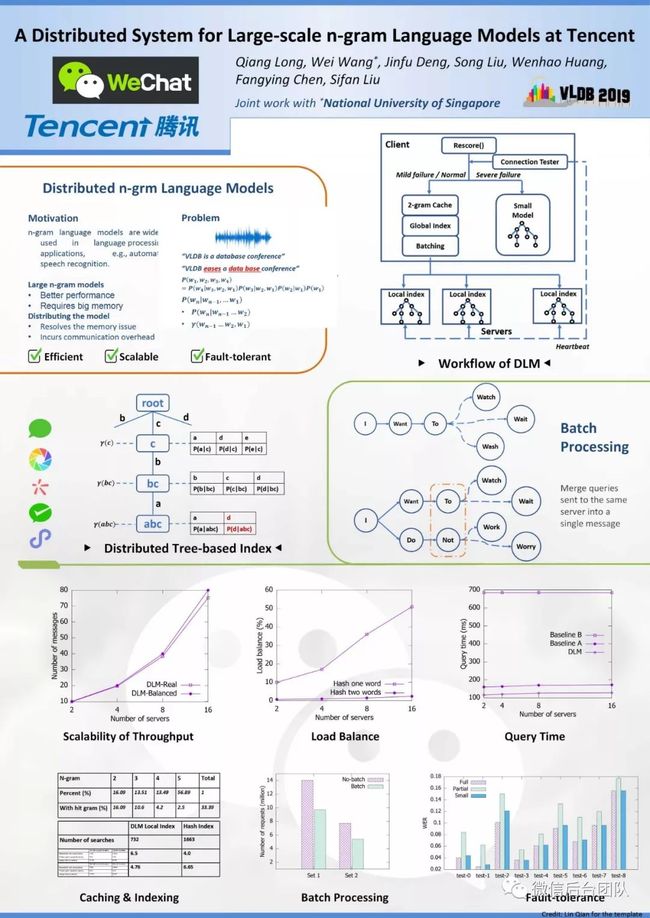
DLM:微信大规模分布式n-gram语言模型系统
来源 | 微信后台团队
Wechat & NUS《A Distributed System for Large-scale n-gram Language Models at Tencent》分布式语言模型,支持大型n-gram LM解码的系统。本文是对原VLDB2019论文的简要翻译。
摘要
n-gram语言模型广泛用于语言处理,例如自动语音识别(ASR)。它可以对从发生器(例如声学模型)产生的候选单词序列进行排序。大型n-gram模型通常可以提供良好的排名结果,但这需要大量的内存空间。将模型分布到多个节点,可以解决内存问题,同时会产生很大的网络通信开销并引入了不同的瓶颈。
本文我们将介绍一套分布式系统,它采用新颖的优化技术来降低网络开销,包括分布式索引、批处理和缓存,可以减少网络请求并加速每个节点上的操作。同时还提出了一种级联容错机制,可根据故障的严重程度自适应地切换到小型n-gram模型。对9种自动语音识别(ASR)数据集的实验研究证实,我们的分布式系统可以高效、有效、稳健地扩展到大型模型。我们已成功将其部署到腾讯的微信ASR系统中,网络流量峰值达到每分钟1亿次查询。
关键字
n-gram语言模型,分布式计算,语音识别,微信
1.介绍
语言模型用于估计单词或标记序列的概率。通常,它们为罕见序列或具有语法错误的序列分配低概率。例如,通过计算机科学文章训练的语言模型可能为s1分配更高的概率 :“VLDB is a database conference” ,而不是s2:“VLDB eases a data base conference”。语言模型广泛用于自然语言处理[15],特别是在生成文本的应用中,包括自动语音识别,机器翻译和信息检索。
通常,语言模型可以用于对生成器生成的候选输出进行排名。例如,在ASR中,生成器是声学模型,其接受音频然后输出候选词序列。对于来自声学模型的若干个类似分数的候选者,例如s1和s2,语言模型对于选择正确的答案至关重要。
n-gram是一种简单且非常有效的语言模型。它基于对序列n-gram的统计(例如频率)来估计单词序列的概率。n-gram是n个单词的子序列。
例如,“VLDB”和“database”是1-gram; “VLDB is”和“VLDB eases”是2-gram。n-gram语言模型为频繁出现的n-gram的序列赋予更高的概率分数。最终概率统计数据是由特定文本语料库计算出来。统计的概率反映了序列从训练文本语料库生成的可能性。对于样本序列s1和s2,3-gram模型会给s1一个更高的概率,因为“VLDB is a”比“VLDB eases a”更常见,同样,“a database conference”比“data base conference”在计算机科学文章中更常见。
使用n-gram语言模型的一个重要问题是其存储成本高。首先为了准确性,n-gram中的n越大越好。例如,1-gram模型会给s2一个比s1更大的分数,因为“data”和“base”比“database”都要出现更频繁。相比之下,2-gram语言模型可能给s1提供比s2更高的概率,因为“database conference”比“data base conference”更常见。
其次,较大的n-gram集合包括更多的n-gram(会有更好的覆盖),因此对相对不常见的n-gram序列也能给出更好的概率估计。例如,如果n-gram集合中不包含“database conference”,则会基于其后缀即“conference”来估计s1的概率。此过程称为回退(参见第2.2节),准确度会有所下降。实验证实,较大的模型确实具有更好的性能。但是,大型模型在单个计算机的内存存储不容易,且快速访问的效率非常低。
通过将统计概率信息分布到多个节点来处理大型n-gram模型,我们称为分布式语言模型。实现分布式n-gram模型的一个挑战是高通信开销。例如,如果文本语料库中不包含n-gram,则会产生O(n)的消息查询(因为需要通过[5]中的“回退”来计算其最终概率)。考虑到每个输入(句子)可能有多达150,000个候选n-gram [5],通信成本变得非常昂贵。实现分布式n-gram模型的另一个挑战与网络故障有关,网络故障经常发生在具有大量网络通信的分布式系统中[23]。如果某些n-gram消息丢失,则该模型将产生对概率的不准确计算。
在本文中,我们提出一种高效,有效和健壮的分布式系统技术,可以支持大规模的n-gram语言模型。
首先,我们在本地节点上缓存短n-gram的统计数据(如1-gram和2-gram)。如此可以消除了低阶n-gram的通信成本。
其次,我们提出适合n-gram检索的两级分布式索引。全局索引将相关n-gram概率的统计信息分发到远端同一节点。因此,每次完整n-gram只发出一次网络消息就能得到完整数据。本地级索引将统计信息存储在后缀树结构中,这有助于快速搜索并节省存储空间。
第三,我们把即将发送到同一服务器的消息优化为单个消息,显著降低了通信成本。
最后,我们提出了一种级联容错机制。两级缓存分别为2-gram大模型子集,4/5-gram小模型。前者使用于网络轻微故障,如偶尔丢包,后者使用于重大网络故障,如节点故障。
本文贡献归纳如下:
-
提出了缓存、索引和批处理优化技术,以减少大规模分布式n-gram语言模型的通信开销和加速概率估计过程。
-
提出了一种级联容错机制,该机制适应于网络故障的严重程度。它在两个局部n-gram模型之间进行切换,给出了健壮的概率估计。
-
实现了一套分布式系统,并以语音识别为应用,对9个数据集进行了广泛的实验。该系统扩展为5-gram模型应用。实验结果证实了较大的n元模型具有较高的计算精度。我们已经将其应用于微信ASR系统,每天有1亿条语音,峰值网络流量为每分钟1亿次查询。
本文的其余部分安排如下:第2节介绍了n-gram语言模型;第3节介绍了系统的细节,包括优化技术和容错机制;第4节对实验结果进行了分析;第5节回顾了相关工作;第6节总结了论文。
2.相关基础
在本节中,我们首先简单介绍如何使用n-gram语言模型估计单词序列的概率,然后简要描述下训练和推理过程。
2.1语言模型
给定m个单词序列,表示为wm =(w1,w2,...,wm),来自词汇表V,语言模型提供该序列的概率,表示为P(w1...m)。
根据概率论,联合概率可以分解如下:
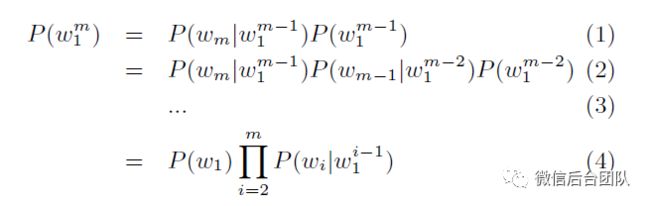
通常,在自然语言处理(NLP)应用中,等式4中的概率与来自序列生成器的得分可以组合,来对候选序列进行排名。例如,ASR系统使用声学模型来生成候选句子。声学得分与来自语言模型的得分(等式4)组合,对候选句子进行排名。具有语法错误或奇怪单词序列的那些将从语言模型得到较小的分数,因此被排在较低的位置。
n-gram语言模型假设序列中的单词仅取决于先前的n-1个单词。形式上表达为
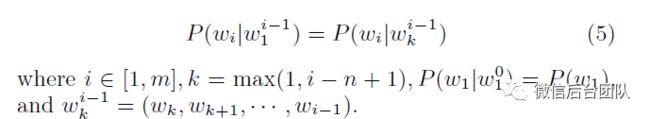
在公式4中应用假设(公式5,称为Markov假设[15]),我们得到了
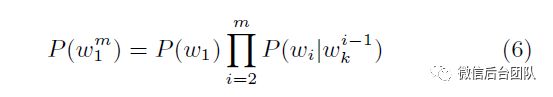
例如,3-gram模型估计4个单词序列的概率,
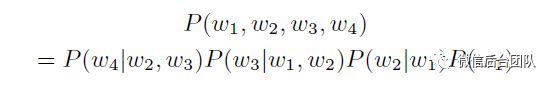
(省略examples)
2.2 平滑技术
基于频率的统计(方程7)有一个问题:当n-gram没有出现在训练语料库中时(例如当训练语料库很小时,频率计数为0),条件概率(公式7)为零,这导致联合概率为0(公式6)。平滑是解决这种“零频率”问题的一种技术。有两种流行的平滑方法,即回退模型和插值模型。一般的想法是将一些概率质量从频率高的n-gram转移一部分到
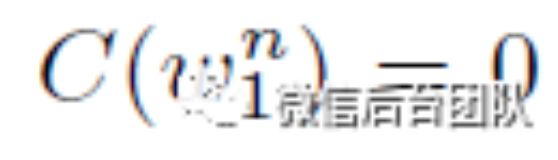 ,
频率低的n-gram,并基于后缀来估计它们的概率。
,
频率低的n-gram,并基于后缀来估计它们的概率。
,
频率低的n-gram,并基于后缀来估计它们的概率。
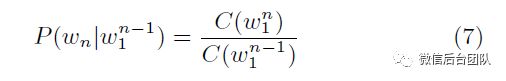
回退平滑模型:
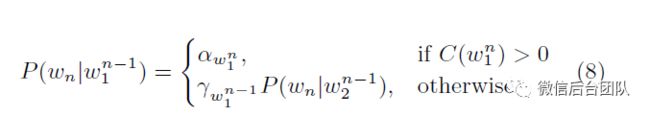
在方程8中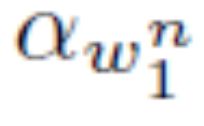 表示(频繁)n-gram的折扣概率。例如,一种流行的平滑技术,称为Kneser-Ney平滑,计算
表示(频繁)n-gram的折扣概率。例如,一种流行的平滑技术,称为Kneser-Ney平滑,计算
表示(频繁)n-gram的折扣概率。例如,一种流行的平滑技术,称为Kneser-Ney平滑,计算
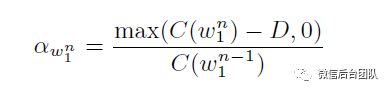
其中D是超参数。
插值Kneser-Ney平滑
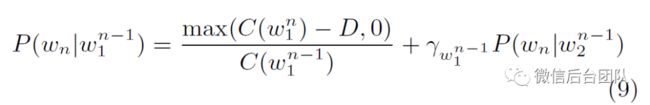
我们应用Kneser-Ney插值平滑,如公式9。通过简单的操作([6]的第2.8节),插值模型(例如公式9)可以转换为相同的公式8,因此两种平滑方法共享相同的推理算法。
在本文的其余部分,我们使用回退模型(公式8)来介绍推理算法。
2.3 训练和推理
n-gram语言模型的训练过程会对训练文本语料库中的频率进行计数,可以得到所有1-gram,2-gram,...,n-gram的所有条件概率(等式4)并计算系数。例如,5-gram模型的统计数据为1-gram至5-gram。
训练语料库中只会出现训练语料库中出现的单词。有两个原因:
a)对于给定的n和一个单词n词汇V,完整的n-gram集,其大小为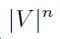
当V很大时会消耗大量的内存。
b)从未使用过一些x-gram记录,例如“is be do”,无需预先计算和存储其统计信息。在本文中,我们关注推理阶段的表现,从而跳过有关培训的细节。
(请注意,对大型文本语料库(如TB级)的训练也非常具有挑战性。与[5]一样,我们使用分布式框架(即Spark)来加速培训过程。)
推理过程接受由其他模块(例如ASR系统的声学模型)生成的n-gram w1...n作为输入,并返回P (wn|wn−1)。如果n-gram出现在训练语料库中,则其训练过程中已经计算出条件概率,可以直接检索;否则,我们使用平滑技术来计算替代的概率(公式8)。
从训练阶段生成的所有概率和系数都保存在磁盘上,并在推理期间加载到内存中。ARPA [27]是n-gram语言模型的通用文件格式。
2.4 本文问题定义
在本文中,我们假设n-gram语言模型已经离线训练好。我们的系统将ARPA文件加载到内存中并进行在线推理,将其用于计算由其他模块生成的单词序列的概率,例如ASR的声学模型。我们提出的技术,可以利用大规模n-gram语言模型的进行高效和稳健的推理。
3.分布式系统
较大的n-gram语言模型在概率估计中更准确。然而,当语言模型具有太多太长的n-gram时,例如,一个具有400 GB存储空间的大型ARPA文件,我们无法将整个文件加载到单个节点的主存储器中。如果我们只将部分ARPA信息加载到主内存中并将其余部分(n-gram)放在磁盘上,则推理过程非常缓慢,因为它必须从磁盘中检索n-gram的统计信息。
我们采用分布式计算的方式来解决这个问题,将ARPA文件分割成多个节点。每个节点的内存足够大,可以存储它的一部分。这样的节点我们称为服务器节点。相应地,对应还有客户端节点。客户端节点如下运行:
首先,它使用其他模块生成单词序列候选(如ASR的声学模型);
其次,它向服务器发送请求消息,从序列中检索每个n-gram的条件概率;一条n-gram就是一条查询。如果查询不存储在服务器上,则使用“回退”来估计概率,如算法1所示。
最后,客户端将概率与公式6结合起来。这个过程叫做解码,这在3.3节中进行了阐述。

在本节中,我们首先介绍我们减少通信开销的优化技术,包括缓存,分布式索引和批处理。在此之后,再描述了针对通信故障的级联容错机制。我们的系统表示为DLM,是分布式语言模型的缩写。
3.1 缓存
缓存广泛应用于数据库系统优化。在DLM中,我们缓存短n-gram的概率数据,具体来说,1-gram和2-gram被缓存在客户端节点上。如果缓存长n-gram,例如3-gram,将进一步降低网络成本。但是,它也会产生大量的内存成本。第4.2.2节详细比较了存储成本和通信减少。通过缓存这些数据,我们不仅可以降低通信成本,还可以改善系统的其他部分。我们实现以下三个目标:
-
减少网络查询的数量。例如对于2gram和1-gram查询,使用本地缓存统计信息估计条件概率。因此,无需向远程服务器发送消息。
-
在算法2(第3.2.1节)中支持超过2-gram的记录,这使得服务器上的数据更加平衡。
-
支持容灾机制,将在3.4节中讨论。
3.2 分布式索引
DLM中的分布式索引由两个级别组成,即客户端节点上的全局索引和服务器节点上的本地索引。
3.2.1 全局索引
通过客户端节点上的本地缓存,客户端可以估计本地1-gram和2-gram查询的概率。对于长n-gram查询,客户端使用全局索引来定位存储计算P(wn | wn-1)的统计信息的服务器(根据算法1),然后向这些服务器发送消息。如果我们可以将所有必需的统计信息放在同一台服务器上,则只会向服务器发送一条消息。构建全局索引(算法2)可以实现该目标。
有两个参数,即来自ARPA文件的n-gram总集合A和服务器B的数量。
对于每个1-gram和2-gram,我们在所有节点都放置其正向概率和回退概率(第3行)。
对于其他n-gram(n≥3),我们基于wn-2 和 wn-1的hash做key,分发正向概率(第5-6行)。基于wn-1和wn(线7-8)的hash做key,分发回退概率。第5行和第7行共享相同的hash函数。

在推理过程中,如果n≤2,我们在本地客户端进行查询而不发送任何消息;否则,我们只需将P(wn | wn-1)的请求消息发送到具有ID Hash(wn-2,wn-1)%B + 1的服务器。运行算法1以使用等式10和14之间的等式之一来获得概率。全局索引保证对于任何n-gram w1..n(n> 2),可以从同一服务器访问算法1中使用的所有数据。(例如,假设 w=“a database”。
根据算法2,以w(第7行和第8行)结尾的所有ngram的回退概率(例如,“is a database”)与所有子gram的正向条件概率都放在同一服务器上(例如,“is a database conference“),其第三个和第二个字是w(第5行和第6行)。另外,公式13(相应的公式14)使用的P(wn | wn-1)和γ(wnn-21)(P(wn)和γ(wn-1))在所有的节点上都有(第3行)。
总之,公式10和14中使用的所有统计数据都可以从同一服务器获得。因此,算法1的任何一个完整的n-gram都可以减少至只有一次网络查询。)
如果我们只缓存1-gram,负载均衡算法1也能工作。然而,缓存1-gram和2-gram的结果可以获得更好的负载平衡。我们解释如下。考虑到某些单词非常流行,如“is”和“the”,基于单个单词的散列分配n-gram可能会导致服务器节点之间的负载不平衡。
例如,存储以'the'结尾的n-gram的服务器将具有更大的分片并从客户端接收更多消息。由于2-gram的分布比1-gram(即单词)的分布更均衡,因此在算法1中基于两个单词(wn-1+wn或wn-2+wn-1)分布n-gram将使查询更加均匀。事实上,我们不建议使用3-gram以上,以使分布更加平衡。这样需要在本地客户端节点上缓存3-gram并在每个服务器节点上备份3-gram信息,这会显着增加存储成本。
3.2.2 本地索引
服务器节点从客户端接收到n-gram查询请求,它就会搜索本地索引来得到统计信息并将它们组合最终计算P(wn | wn-1)。服务器上需要构建本地索引,以便有效地检索概率信息。我们使用后缀树作为索引结构,其中每个边表示来自语音的一个或多个单词,每个节点通过连接边表示一系列单词。如图1所示。
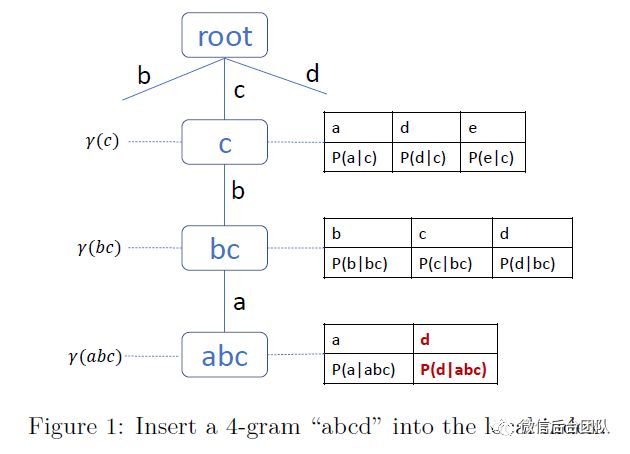
本地索引的构建算法如算法3。每个服务器都有两组从算法2生成的统计数据,即表示为G = {}的回退权重和表示为P = {}。对于P中的每一对,如果它是1-gram,我们只需将它存储在字典U(第8行)中;否则,我们沿着路径wn-遍历树。1,wn-2,...,w1。如果我们在完成路径之前到达叶节点,则创建剩余单词的新边和节点。返回最后一个被访问节点(第5行)。使用wn作为键(第6行)将概率插入到排序数组中,从而启用二分搜索。

对于每一对参数中的g,我们沿着完整n-gram的反向序列路径wn,wn-1,...,w1(第7行)来遍历树结构。遍历期间插入新节点。γ(w1n)被分配给回退的节点(第8行)。注意,每个节点可能具有多个关联概率;但是,它只能有一个回退权重。这是因为共享相同前缀(即wn-1)的所有n-gram语法的概率被插入到同一节点中;而回退权重与对应于完整n-gram的节点相关联,且n-gram是唯一的。图1给出了将4-gram插入索引的一个例子。这个4-gram的条件概率位于右下角。
在推理期间,我们运行算法4来估计条件概率。它针对后缀树3实现算法1.算法4遍历(wn-1,...,w2,w1)(第2行)。当下一个单词没有边缘或达到w1时,它会停止。返回的路径是一组访问过的节点。根节点位于底部,最后一个访问节点位于顶部。然后它逐个弹出节点。所有类型的n-gram都是通过使用公式10和14之间的公式之一来计算概率 。
3.3 Batch 处理
通常,生成器为每个输出位置生成多个候选词。因此,有许多待筛选的句子。当语言模型在生成新的候选者之后立即对新候选词进行排名,它被称为on-the-fly rescoring ;当语言模型被用于在完成所有位置之后对候选句子进行排名时,它被称为multi-pass rescoring。与multi-pass rescoring相比,on-the-fly resocring会产生较小的存储成本,并且通过过滤低分数的单词来维持一小组候选句子,因此效率更高。在DLM中,我们采用on-the-fly recoring。

当前候选句子的尾部,可能产生新的若干个新候选词。为了得到每个新候选词的联合概率,我们需要得到最后一个n-gram的正向条件概率(其它词已经计算了n-gram的概率)。一开始,候选句子很短,只有一个单词“START”代表一个句子的开头。因此,第一组查询n-gram是2-gram,如“START I”。随着句子变得更长,查询n-gram变得更长,例如5-gram。如果我们保持最多K个候选参数并为每个位置生成W个单词,那么我们需要查询KW n-gram,即KW个消息。这个数字可能非常大,如10,000,这会导致非常多的网络查询。为了降低通信消耗,我们尝试将发送到同一服务器的消息批量处理为单个消息。
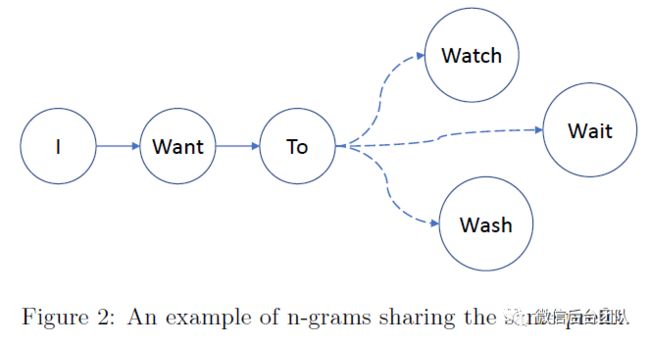
如果两个n-gram共享相同的前缀,根据算法4(和公式10-14),它们可能在本地索引上共享类似的访问模式,以便统计计算条件概率。假设我们使用4-gram模型对图2中的候选词进行排名,即“watch”,“wait”和“wash”。即使使用分布式索引,我们也需要为3个4-gram中的每一个提供一条消息。
由于它们共享相同的前缀“I Want To”,因此根据算法2的第5行将这三条消息发送到同一服务器。将这三条消息合并为一条消息。一旦服务器节点收到消息,算法4就沿着公共前缀“I Want To”的反向遍历,然后遍历返回以分别获得3个n-gram的统计数据。结果将放入单个消息中并发送回客户端。对于此示例,我们将消息数量减少至原来的1/3。换句话说,可以节省2/3的成本。
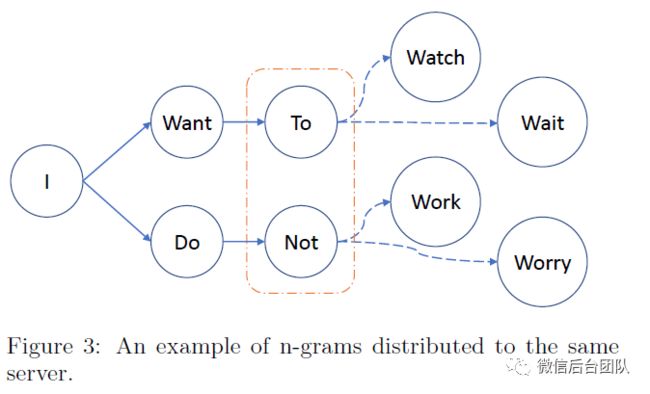
对于不共享相同前缀的n-gram,只要将它们目的地是同一服务器,我们仍然可以合并它们的请求消息。假设“Want To”和“Do Not”具有相同的散列值,则在图3中,根据算法1的第5行,可以将所有4-gram的消息合并(批处理)为单个消息。在服务器端,共享相同前缀的n-gram由算法4一起处理。两种批处理方法是正交的,因此可以组合在一起。
3.4 容错(容灾)
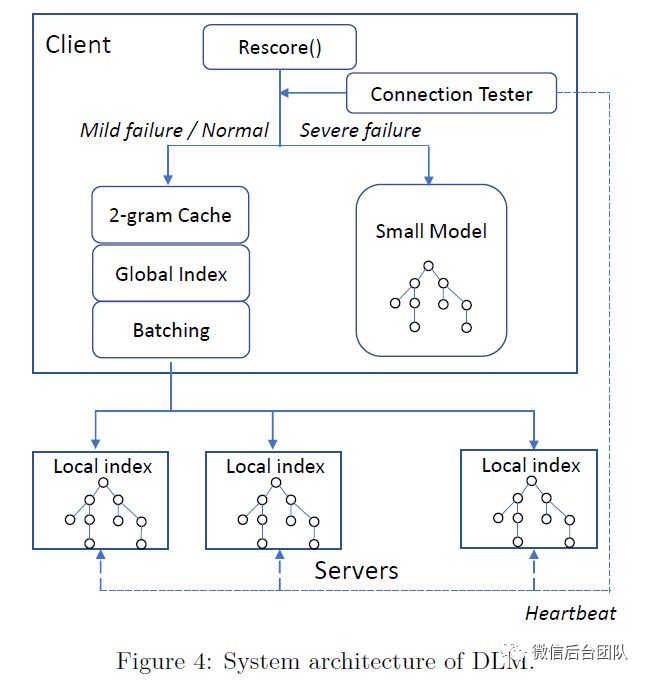
容错对于分布式系统至关重要。根据网络故障的严重程度,我们提供级联容错机制。图4显示了我们系统的架构。连接测试程序不断向服务器发送心跳。当故障率很高时,例如,超过0.1%的消息超时或网络延迟加倍,我们将所有查询重定向到本地小语言模型。
在我们的实验中,我们使用一个50 GB统计的小型(5-gram)模型,通过基于熵的裁剪从完整的模型中裁剪得到[25]。当故障率处于非常低的水平,我们正常去远端查询大模型概率,如果查询失败,我们将使用本地2-gram子集模型的分数。(注意,这个子集模型和50G小模型是不一样的,两者独立分开训练)。因此,我们不能混合他们的统计数据来估计句子概率(方程6)。
4.0 实验
在本节中,我们将基于多个数据集的来评估ASR的DLM技术。结果表明,我们的分布式语言模型DLM,可以有效地扩展到大型模型(例如,具有400 GB ARPA),并且通信开销很小。具体来说,当输入音频增加一秒时,DLM的开销仅增加0.1秒,这对于微信中的实时系统来说足够小。
4.1实验设置
4.1.1 硬件
我们通过每个节点上具有Intel(R)Xeon(R)CPU E5-2670 V3(2.30GHz)和128 Giga Bytes(GB)内存的集群进行实验。节点通过10 Gbps网卡连接。我们使用开源消息传递库(Github:phxrpc)
4.1.2 数据
我们收集一个大的文本语料库(3.2TB)来训练使用插值Kneser-Ney平滑的5-gram语言模型。经过训练,我们得到一个500 GB的ARPA文件,进一步修剪,生成50GB,100GB,200GB和400GB的实验模型。如果没有明确的描述,则实验将在200GB模型上进行,该模型是当前部署的模型。为了评估语言模型的性能,我们使用ASR作为我们的应用程序。收集9个数据集作为测试数据。我们将这9个数据集命名为test-1到test-9,详细信息如表1所示。我们可以看到测试数据是在不同的环境下记录的,并且在长度方面有所不同。mix 表示音频具有阅读和自发语音。noise 意味着音频被记录在实际应用场景的公共场所。
4.1.3评估指标
我们评估DLM在支持ASR方面的有效性,效率和存储成本。为了有效性,我们使用单词错误率(WER),这是ASR的常用度量。为了计算WER,我们从测试数据集中手动生成每个音轨的参考单词序列(即标准答案)。给定输入音轨,我们将模型生成的单词序列与参考单词序列对齐,然后应用公式15计算WER。
在公式15中,D; S和I是删除,替换和插入操作的数量,分别涉及在Levenshtein距离之后对齐两个序列.N是参考序列中的词的总数。例如,转换图5中的预测词序列对于参考序列,我们需要D = 1删除操作,S = 2替换操作,I = 1插入操作。相应的WER是(1 + 2 + 1)/5 = 0.8

为了提高效率,我们测量每秒语言模型输入音频所花费的平均处理时间。分布式n-gram模型会产生通信开销。我们还测量网络消息的数量,这是通信开销的主要原因。
4.2可伸缩性和效率评价
我们首先研究DLM的整体效率和可扩展性。之后,我们对每种优化技术的性能进行细分分析。
4.2.1可扩展性测试
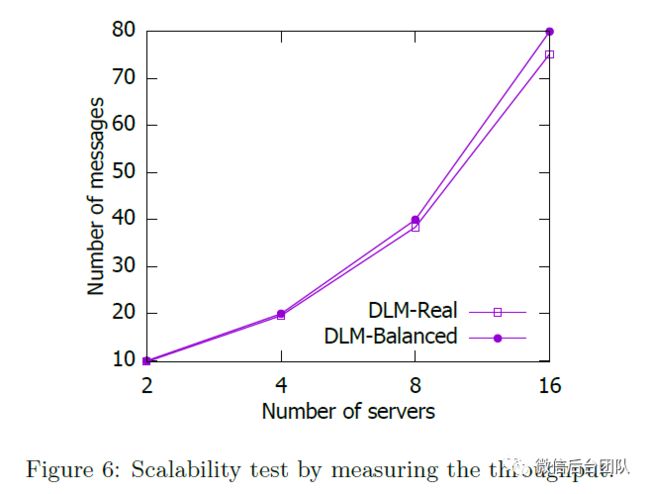
我们根据吞吐量测试DLM的可扩展性,即每秒服务器处理的消息数量。我们使用具有400GB数据的大型模型,并测量DLM处理的每分钟消息数。通过控制从客户端到服务器的消息速率,所有服务器上的最大CPU利用率保持在75%。
我们运行两组工作负载:a)实际工作负载,表示为DLM-Real,其消息由解码器生成,无需任何调节; b)平衡工作负载,表示为DLM-Balanced,其消息在DLM的所有服务器之间手动平衡。对于DLM-Real,向服务器分发消息是不平衡的。因此,一些服务器将接收更少的消息,并且整体吞吐量受到影响。图6中的结果显示DLM-Balanced和DLM-Real很好扩展,差异很小。良好的可扩展性是得益于本文提出的技术,将在以下小节中详细分析。
可扩展的系统应该最小化服务器增多时产生的开销。在图7中,我们通过在服务器数量增加时查询时间和每秒音频生成的消息数量的变化来衡量开销。我们将DLM与两种基线方法进行比较,表示为基线A [5]和基线B [20]。
基线A基于每个n-gram的最后两个字的散列来分配回退权重和概率。文中简要提到了批处理,省略了细节。我们对基线A使用相同的DLM批量处理方法。基线B根据n-gram中所有单词的散列分配概率和回退权重;另外,它在本地缓存短的ngram。我们遵循与DLM相同的缓存机制实现Baseline B,即缓存1-gram和2-gram。
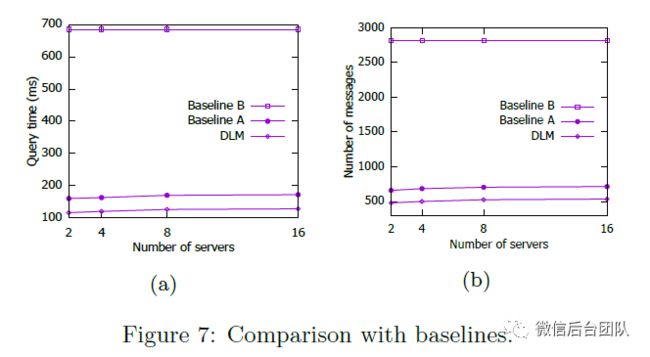
DLM和基线的每秒输入音频的处理时间如图7a所示。我们可以看到,当服务器数量增加时,DLM和Baseline A在查询时间方面的开销(或变化)很小。基线B的查询时间仍然很长,并且对于不同数量的服务器几乎相同。这可以通过从客户端到服务器每秒音频的消息数来解释(图7b)。注意,图7b的y轴与图6中的y轴不同,图6表示服务器每秒处理的消息。算法A和DLM比算法B产生的消息少,主要是因为批量处理。对于Baseline A和DLM,当服务器数量增加时,发送到同一服务器的两条消息的机会减少。
因此,消息数量和处理时间增加。此外,DLM的分布式索引保证一个n-gram的所有统计信息都在一台服务器上。基线A它只能保证在n-gram的回退过程中使用的所有概率被分配到同一服务器(因为等式8中的后缀gram共享相同的最后两个字),而回退权重可以被分发到不同的服务器。因此,DLM生成的消息比算法A少。
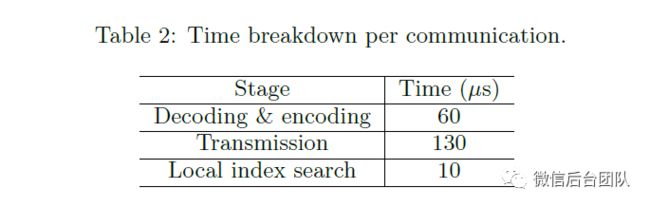
为了了解时间的消耗,我们在表2中测量单个网络通信的每个阶段所花费的时间。我们可以看到,使用优化的本地索引,大部分时间花在消息传输,编码和解码上,这需要优化消息传递库。在本文中,我们专注于减少消息的数量。接下来,我们研究了我们提出的优化技术在通信减少方面的有效性。
4.2.2 Caching
DLM在客户端缓存2-gram和1-gram。因此,1-gram和2-gram查询在本地回答,而不向服务器节点发送消息。从表3中,我们可以看到可以直接发出16.09%的2-gram查询。因此,我们通过在本地缓存2-gram查询来减少16.09%的消息(不考虑批处理)。只有一个1-gram的查询,即“START”,它对性能没有影响。
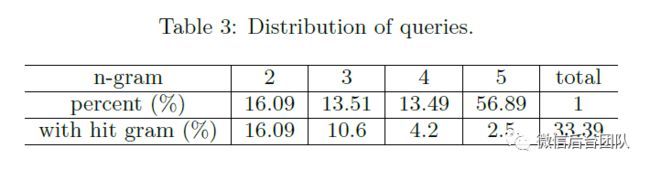
我们不会缓存3-gram和4-gram,因为它们非常大,如表4所示。此外,只有一小部分3-gram和4-gram查询可以直接回答而无需回退。其余的3-gram和4-gram查询必须由远程服务器计算。换句话说,缓存3-gram和4-gram会降低通信成本。5-gram的大小并不大,因为训练算法修剪了许多5-gram,可以使用4-gram或3-gram精确估算,以节省存储空间。我们不缓存5-gram,因为只有2.5%的5-gram查询(表3)可以使用ARPA文件中的5-gram来应答;其他5-gram查询需要回退,这会导致网络通信。
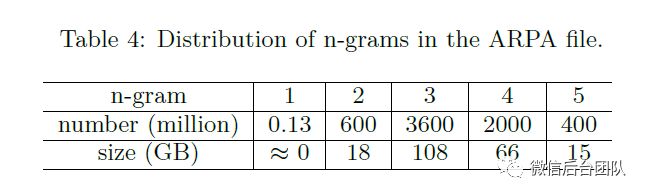
4.2.3 分布式索引
我们进行了一项消融实验,以分别评估全局和本地 DLM 索引(第3.2节)的表现。我们不考虑此实验的批处理和缓存优化。DLM的全局索引将用于估计n-gram概率的所有数据放在同一服务器节点中,从而将消息数量减少到每个n-gram 1次。为了评估这种减少的效果,我们在表3中列出了查询分布。只有一个1-gram查询,即“START”。因此,我们不会在表格中列出它。
我们可以看到所有查询中有33.39%已命中。换句话说,这些33.39%的查询不需要回退,每个查询只会产生一条消息。其余查询至少需要一次回退,这至少会再产生一次消息。使用全局索引,我们始终为每个查询发出一条消息,这至少可以节省(1-33.39%)= 66.61%的成本。
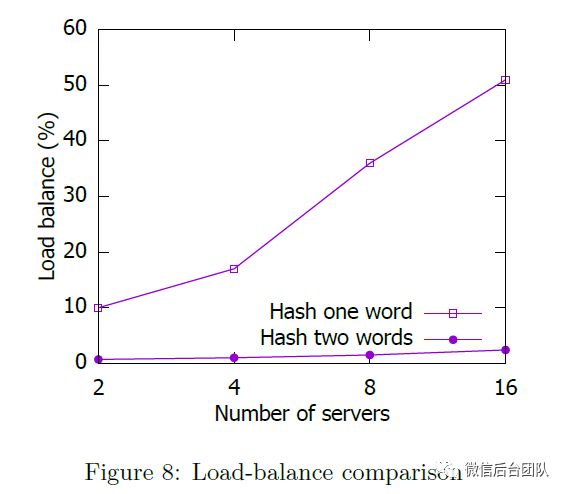
全局索引将ARPA文件中的数据分区到多个服务器上。我们评估服务器之间的负载平衡。负载平衡如下计算:
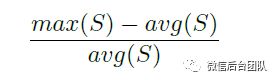
其中S表示所有服务器节点上的本地索引大小集,max(avg)计算最大(相应的平均值)索引大小。图8通过对单个单词和两个单词进行散列来比较全局索引的负载平衡。我们可以看到,当对两个单词进行散列时,服务器之间的数据分布更加平衡。
为了评估DLM的本地索引(即后缀树)的性能,我们创建了一个n-gram查询集,并使用我们的本地索引与使用存储条件概率和回退权重的基线索引来比较搜索时间。两个单独的Hash函数都以整个n-gram为关键字。表5显示DLM的本地索引比哈希索引快得多(参见总时间)。这主要是因为本地索引通过减少搜索次数来节省时间。具体而言,平均而言,每个n-gram需要2.27倍的回退才能达到获得最终数据。DLM每n-gram搜索一次本地索引(后缀树),然后遍历以获取回退过程所需的所有信息。
相反,基线方法在回退过程(算法1)期间重复调用哈希索引以获得回退权重和概率。尽管每次搜索的哈希索引的速度很快,但总体效率差距主要取决于搜索次数的巨大差异。请注意,表5中每次搜索的时间小于表2中的时间。这是因为在表2中,我们测量每条消息的时间,其中包括一批n-gram。这些n-gram中的一些可以共享相同的前缀(参见第3.3节),因此一起处理。因此,搜索时间更长。表5中的时间仅适用于单个n-gram。
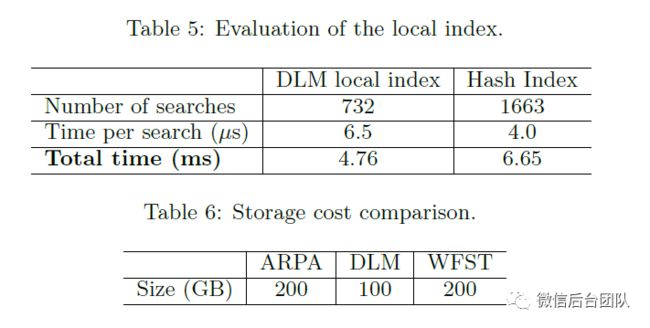
本地索引还能节省存储,因为后缀树仅在共享该前缀的所有n-gram中存储前缀一次。图6比较了ARPA文件,DLM(即本地索引)和另一种用于存储语言模型的流行数据结构(即WFST [22])的存储成本。我们可以看到DLM节省了近一半的空间。
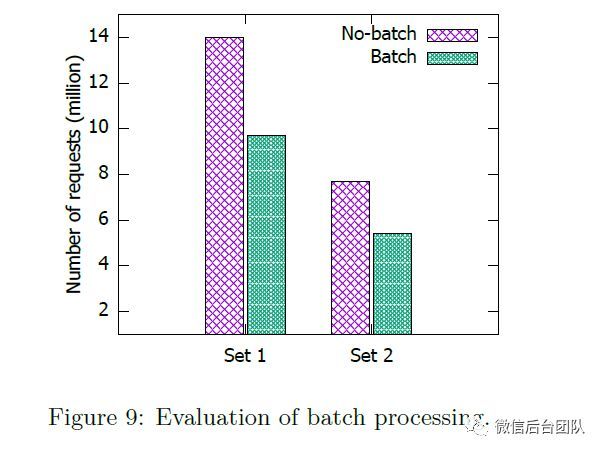
4.2.4 batch处理
3.3节中提出的批处理将发送到同一服务器的消息合并为单个消息,以减少开销。图9比较了DLM与批处理和没有批处理的DLM两组n-gram查询。y轴是每个查询集的消息总数。我们可以看到批处理显着减少了网络消息的数量。实际上,几乎一半的消息都被消除了。因此,它节省了很多时间。图7中DLM和Baseline B之间的巨大差距也主要是由于批处理。
4.3 容错(容灾)评估
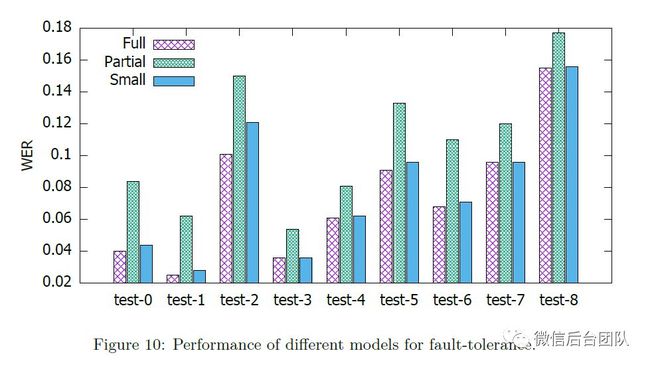
我们的分布式系统具有两个用于容错的备用模型,这有助于使系统对网络故障具有鲁棒性。但是,由于我们使用的是部分或小型语言模型,因此识别性能可能会降低。为了比较这些模型的准确性,我们独立地在9个测试数据集上运行每个模型。图10显示了小模型,部分和完整模型的WER。完整模型的ARPA文件具有200 GB数据。部分模型包括完整模型的所有1-gram和2-gram。小模型是在文本语料库的子集上训练的5-gram语言模型。ARPA文件大小为50 GB。
我们可以看到完整模型具有最小的WER,这证实了我们的假设,即较大的模型具有更好的性能。此外,小模型优于部分模型,并且在某些测试数据集上与完整模型可以竞争。这是因为小型模型通过复杂的修剪策略从完整模型中修剪[25],而部分模型只需通过移除3-gram,4-gram和5-gram得到。
请注意,轻度网络故障时调用部分模型,这对运行时的整体WER影响非常有限。尽管小型模型在多个测试数据集(环境)上具有与完整模型类似的性能,但仍然值得使用完整模型,因为完整模型在不同环境中更加健壮,包括具有多个扬声器的嘈杂环境,这对于商业部署非常重要。
总结
n-gram语言模型在NLP应用非常广泛。分布式计算使我们能够以更高的准确度运行更大的n-gram语言模型。由于通信成本和网络故障,使系统可扩展是一项挑战。面对挑战,我们提出了一个分布式系统来支持大规模的n-gram语言模型。为了减少通信开销,我们提出了三种优化技术。
首先,我们在客户端节点上缓存低阶n-gram以在本地提供一些请求。其次,我们提出了一个分布式索引来处理其余的请求。索引将每个n-gram查询所需的统计信息分配到同一服务器节点上,这将每n-gram的消息数量减少到只有一个。此外,它在每个服务器上构建后缀树索引,以便快速检索和估计概率。第三,我们将发送到同一服务器节点的所有消息批量处理为单个消息。除了效率优化之外,我们还提出了一种级联容错机制,它可以自适应地切换到本地小语言模型。实验结果证实,我们的系统可以高效,有效,稳健地扩展到大型n-gram模型。
参考文献
[1] C. Allauzen, M. Riley, and B. Roark. Distributed representation and estimation of wfst-based n-gram models. In Proceedings of the ACL Workshop on Statistical NLP and Weighted Automata (StatFSM), pages 32-41, 2016.
[2] D. Amodei, R. Anubhai, E. Battenberg, C. Case,J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski,A. Coates, G. Diamos,E. Elsen, J. Engel, L. Fan,C. Fougner, T. Han, A. Y. Hannun, B. Jun, P. LeGresley, L. Lin, S. Narang, A. Y. Ng, S. Ozair, R. Prenger, J. Raiman, S. Satheesh, D. Seetapun,S. Sengupta, Y. Wang, Z. Wang, C. Wang, B. Xiao,D. Yogatama, J.Zhan, and Z. Zhu. Deep speech 2:End-to-end speech recognition in english and mandarin. CoRR, abs/1512.02595, 2015.
[3] P. Bailis, E. Gan, S. Madden, D. Narayanan, K. Rong, and S. Suri. Macrobase: Prioritizing attention in fast data. In SIGMOD, pages 541-556, 2017.
[4] Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin. A neural probabilistic language model. J. Mach. Learn. Res., 3:1137-1155, Mar. 2003.
[5] T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean. Large language models in machine translation. In EMNLP-CoNLL, pages 858-867, Prague, Czech Republic, June 2007.
[6] S. F. Chen and J. Goodman. An empirical study of smoothing techniques for language modeling. Computer Speech & Language, 13(4):359-394, 1999.
[7] D. Crankshaw, X. Wang, G. Zhou, M. J. Franklin, J. E. Gonzalez, and I. Stoica. Clipper: A low-latency online prediction serving system. In NSDI, pages 613-627, Boston, MA, 2017. USENIX Association.
[8] A. Emami, K. Papineni, and J. Sorensen. Large-scale distributed language modeling. In ICASSP, volume 4, pages IV-37-V-40, April 2007.
[9] A. Graves and N. Jaitly. Towards end-to-end speech recognition with recurrent neural networks. In ICML - Volume 32, ICML'14, pages II-1764-II-1772. JMLR.org, 2014.
[10] A. Graves, A. Mohamed, and G. E. Hinton. Speech recognition with deep recurrent neural networks. CoRR, abs/1303.5778, 2013.
[11] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine, 29(6):82-97, Nov 2012.
[12] S. Ji, S. V. N. Vishwanathan, N. Satish, M. J. Anderson, and P. Dubey. Blackout: Speeding up recurrent neural network language models with very large vocabularies. CoRR, abs/1511.06909, 2015.
[13] J. Jiang, F. Fu, T. Yang, and B. Cui. Sketchml: Accelerating distributed machine learning with data sketches. In SIGMOD, SIGMOD '18, pages 1269-1284, New York, NY, USA, 2018. ACM.
[14] R. Jozefowicz, O. Vinyals, M. Schuster, N. Shazeer, and Y. Wu. Exploring the limits of language modeling. CoRR, abs/1602.02410, 2016.
[15] D. Jurafsky and J. H. Martin. Speech and Language Processing (2nd Edition). Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 2009.
[16] D. Kang, J. Emmons, F. Abuzaid, P. Bailis, and M. Zaharia. Noscope: Optimizing neural network queries over video at scale. PVLDB, 10(11):1586-1597, 2017.
[17] R. Kneser and H. Ney. Improved backing-o for m-gram language modeling. In ICASSP, volume 1,pages 181-184 vol.1, May 1995.
[18] Y. Lu, A. Chowdhery, S. Kandula, and S. Chaudhuri. Accelerating machine learning inference with probabilistic predicates. In SIGMOD, SIGMOD '18, pages 1493-1508, New York, NY, USA, 2018. ACM.
[19] A. L. Maas, A. Y. Hannun, D. Jurafsky, and A. Y. Ng. First-pass large vocabulary continuous speech recognition using bi directional recurrent dnns. CoRR, abs/1408.2873, 2014.
[20] C. Mandery. Distributed n-gram language models : Application of large models to automatic speech recognition. 2011.
[21] T. Mikolov, S. Kombrink, L. Burget, J. Cernocky, and S. Khudanpur. Extensions of recurrent neural network language model. pages 5528 - 5531, 06 2011.
[22] M. Mohri, F. Pereira, and M. Riley. Weighted nite-state transducers in speech recognition. Comput. Speech Lang., 16(1):69-88, Jan. 2002.
[23] Y. Shen, G. Chen, H. V. Jagadish, W. Lu, B. C. Ooi, and B. M. Tudor. Fast failure recovery in distributed graph processing systems. PVLDB, 8(4):437-448, 2014.
[24] D. Shi. A study on neural network language modeling. CoRR, abs/1708.07252, 2017.
[25] A. Stolcke. Entropy-based pruning of backo language models. CoRR, cs.CL/0006025, 2000.
[26] W. Williams, N. Prasad, D. Mrva, T. Ash, and T. Robinson. Scaling recurrent neural network language models. In ICASSP, pages 5391-5395, April 2015.
[27] S. Young, G. Evermann, M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey, V. Valtchev, and P. Woodland. The HTK book. 01 2002.
[28] Y. Zhang, A. S. Hildebrand, and S. Vogel. Distributed language modeling for n-best list re-ranking. In EMNLP, EMNLP '06, pages 216-223, Stroudsburg, PA, USA, 2006.
PS:本文首先用微信翻译引擎完成了全文的翻译,然后再由人工对部分影响阅读的句子做了修改。
(*本文为AI科技大本营转载文章,转载请联系作者)
推荐阅读
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
AI ProCon圆满落幕,五大技术专场精彩瞬间不容错过
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
我的一年AI算法工程师成长记
开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍
如何打造高质量的机器学习数据集?
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句

你点的每个“在看”,我都认真当成了喜欢