京东对于强化学习感觉非常执着啊,咱们在之前已经介绍过三篇京东公开出来的强化学习文章了。今天咱们再来介绍一篇,这一篇中,重点介绍了如何使用GAN搭建一个强化学习的仿真环境。一起来看下吧。
论文名称:《Toward Simulating Environments in Reinforcement Learning Based Recommendations》
论文下载地址:https://arxiv.org/abs/1906.11462
1、背景
在电商领域呢,使用强化学习做推荐,可以带来两方面的好处:
1)通过用户状态的改变,可以不断地实时调整推荐策略
2)可以优化用户的长期收益,例如整个session的收益,而非推荐单个物品的收益
但是,使用强化学习也有一定的限制,主要有:
1)我们通常使用用户对推荐结果的实时反馈来训练强化学习推荐模型,最为有效的方法是使用线上的A/Btest来产生有效的数据,但是使用A/B来收集数据通常需要几周的时间,同时部署一个新的方法也需要工程上耗费更多的资源和精力。
2)同时,如果一个推荐系统没有被充分训练好的话,A/B实验往往会对用户的体验造成一定的损害。
3)在电商领域,商品数量和用户数量都是数目巨大的,导致整个的状态空间和动作空间十分巨大,因此需要极大规模的数据量来保证模型的鲁棒性。尽管日志数据数量非常多,但是对于每个用户来说,数量是极少的。
因此,为了克服上述挑战,解决数据量问题以及线下充分训练问题,这里我们提出了一个基于GAN的强化学习仿真环境。一起来看一下吧。
2、问题陈述
作为强化学习的问题陈述,当然少不了四大基本元素:状态空间、动作空间、奖励、状态转移概率。当然有时候还有折扣系数等等,这里不做介绍。
状态空间S:这里我们定义的用户状态s={i1,i2,...,iN},是用户近期浏览过的N个商品,以及对应的反馈。
动作空间A:动作空间就是可以推荐的物品集合,这里一次动作a只推荐一个商品。
奖励R:当系统基于用户状态s作出动作a时,用户会对推荐的物品作出反馈,这里的反馈包括跳过、点击或者购买该商品,而不同的反馈对应的奖励r(s,a)也是不同的。
状态转移概率P:这里的状态转移概率是确定的,当s={i1,i2,...,iN},动作为a时,转移到的状态s'={i2,...,iN,ia},这里感觉论文写的不太准确,因为状态不仅包括推荐了那个商品,还包括用户的反馈,所以这里可能稍微和论文有点出入。
3、基于GAN的仿真环境概述
基于上述的问题定义,本文提出的基于GAN的仿真系统框架如下图所示:
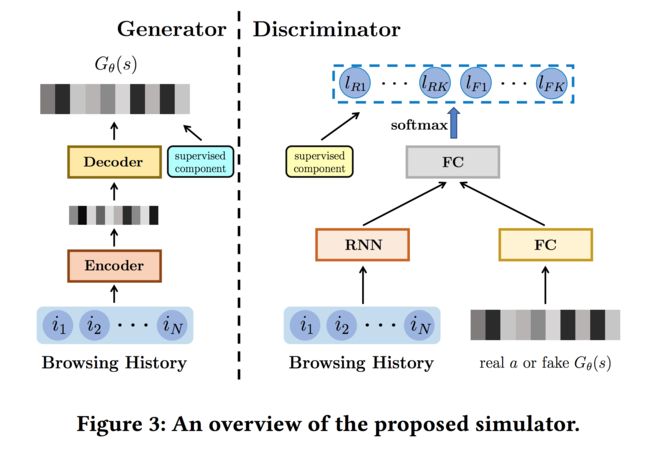
3.1 Generator
Generator的整体结构如下:

Generator是一个encoder-decoder结构,输入的话是用户的浏览序列,即当前的状态,包含N个商品以及用户对商品的反馈。每一时刻的输入包含两部分:
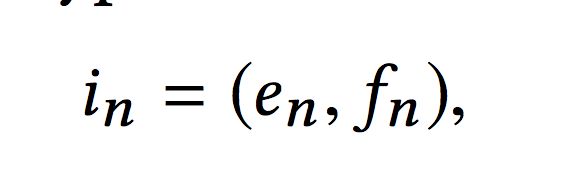
其中en是in对应的商品的embedding,这里的embedding论文中提到说是经过预训练得到的(感觉按照论文的意思,这块不会随着模型训练进行fine-tuning)。fn是一个反馈类型展开后的one-hot向量。接下来,反馈类型也将转换为对应的embedding:
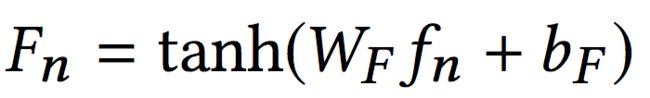
这里使用tanh进行激活的原因是en中每个元素的取值范围是(-1,1),那么经过转换后,输入变为:

接下来是一个GRU层,经过GRU层之后,得到最终的hidden state输出为hn,将其视为用户当前的偏好表示:

Deocder阶段的目标是预测下一个要推荐给用户的商品,将用户当前的偏好表示pE作为输入,经过多层全连接神经网络后得到向量输出,Gθ(s)。这里是得到的一个向量,要想得到一个具体的商品,可以跟所有商品的embedding计算相似度,并选择一个相似度最高的商品。
好了,到目前为止,我们已经介绍了Generator的结构,关于如何训练Generator将在3.3节介绍。接下来先介绍Discriminator的结构。
3.2 Discriminator
Discriminator的整体结构如下:
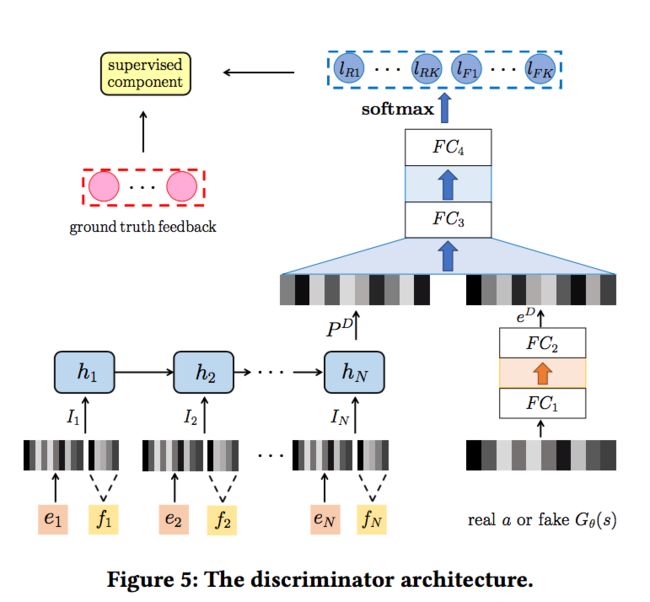
可以看到,Discriminator左下角的输入部分与Generator是一样的结构,但是与Generator的参数并不相同。GRU部分最后的输出计作pD。
而右下角的部分则把真实的action对应的item的embedding或者Generator生成的Gθ(s)作为输入,经过两层的全连接层得到输出eD。
将pD和eD进行连接之后,再经过两层全连接层,得到Discriminator的输出,长度为2 * K。其中K代表用户反馈类型的种类:

输出的结果是经过softmax之后的结果:
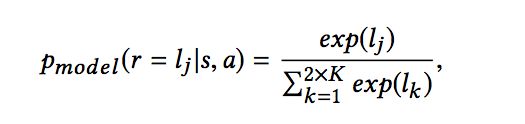
输出中的前K维表示,如果这个输入是真实的商品(这里的真实商品即用户在当前状态下,下一个实际浏览的商品)的话,用户的每种反馈的概率,后K维表示,如果这个输入是Generator产生的话,用户的每种反馈的概率。
接下来,咱们介绍如何对Generator以及Discriminator进行训练。
3.3 模型训练
对于Discriminator来说,咱们这里共有两个目标,判断这个输入是真实的商品还是Generator产生的,同时,判断用户可能作出的反馈。因此,损失函数也包含两部分。
第一部分的损失函数,我们首先要计算Discriminator把输入判作真实或虚假概率。判作真实的概率计作:

即输出的前K项的和,而判作虚假的概率是:
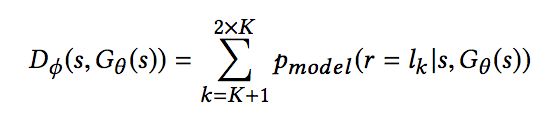
即输出的后K项的和。有了两部分的概率,可以使用logloss来计算损失:
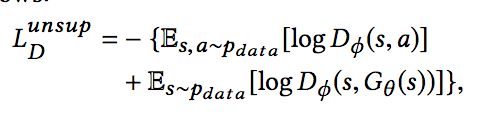
而为了估计用户每种反馈的概率,第二部分的损失函数设计如下:

第二部分的损失函数又包含两个小部分,这两个小部分都是交叉熵损失,代表用户真实的反馈和Discriminator得到的用户反馈类型分布的差距。如果输入是一个真实的商品a的话,那么会对应一个用户真实的反馈,可以依此来指导模型的训练,如果模型输入是Generator的输出的话,同样会使用用户在下一个商品上的真实反馈指导模型训练,这样相当于进行了一定的数据增强,增加了Discriminator的判别能力,进而提升了Generator的生成能力,不过这部分的贡献需要乘上一个打折系数。
这里为什么说在一定程度上进行了数据增强呢?暂时还没有想明白,欢迎大家在下方留言,一起交流讨论。
进而,Discriminator总的损失计算如下:
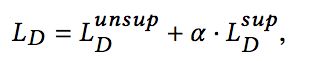
对于Generator来说,同样有两部分的损失,一是希望能尽可能骗过Discriminator,使得Discriminator将Generator产生的判别为假的概率越低越好:
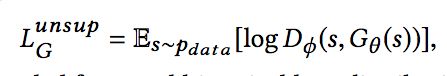
二是希望产生的向量Gθ(s),与真实序列中下一个商品的向量距离越近越好,这里距离使用欧氏距离计算:

因此,总的损失计算结果如下:
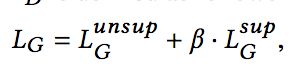
好了,模型就介绍到这里了,后面的实验部分咱们就略过了,感兴趣的同学可以看一下。
4、仿真环境使用(猜测)
那么得到一个仿真环境之后,该怎么利用呢?论文这一块没有明确的说明,但可以知道的是,既然是一个仿真环境,那么是为了产生更多的训练数据,来使得真正的强化学习推荐模型训练得更加充分,那么可能的做法就是在G和D都训练充分之后,通过G产生一个推荐的item(这个item可能是与Generator产生的向量最为接近的item),然后通过D的前K维输出来得到用户最可能的反馈,并将其作为一条训练数据来训练真正的强化学习模型。这一块也仅是猜测,同样欢迎大家留言讨论!