哈夫曼huffman压缩解压完整代码java实现+多线程
Table of Contents
题记
前言:
github地址:https://github.com/qihe777/huffman
1.什么是huffman编码
2.huffman编码生成:
3.压缩操作
3.1压缩流程
1.第一遍每8位(byte)读取文件统计频率得到huffman编码。
2.将huffman编码格式写入文件头中。
3.第二遍读取文件,匹配到相应的huffman编码,然后将01串每8位转化为1个byte,写入文件得到压缩的文件。
3.2如何实现编码:编码前的注意事项和知识储备。
3.2.1.文件读写是选择nio和普通的阻塞io:
3.2.2.为什么选择每8位来读取和转换:
3.2.3.有压缩就有解压缩,解压缩时需要知道byte和编码的对应关系,所以需要把这些信息写入到文件头。如何定义解压缩需要的文件头?
3.2.4.01编码串用什么来存储,以及如何和byte互相转化:
3.2.5.转化的时候肯定不能一个字节一个字节的写和转换,有没有什么比较高效率的方法?
3.3数据转化方式-位流读写器
3.4代码
4.解压
5.Huffman和7zip效率对比
6.优化手段-多线程
6.1原因
6.2生产者消费者模式。
6.3.效果展示。
6.4分析
7拓展阅读:
题记
最近正是校招的时候,感觉参加面试就跟相亲似的,一直心心念念,生怕被拒绝,很长时间都没消息还安慰自己万一呢。心累,看不下去书。想到之前写的huffman压缩还没总结,还是来写篇博客吧。
前言:
对于文件操作,用c或者c++会方便很多:比如基本数据结构有无符号型和通过指针来操作数组,指针用熟练了真的非常方便,但是因为我比较熟悉的语言是java,只能拿java来使用了。
github地址:https://github.com/qihe777/huffman
1.什么是huffman编码
赫夫曼编码是一种无损数据压缩算法。在计算机数据处理中,赫夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用赫夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。节选自:https://blog.csdn.net/will130/article/details/46425089
霍夫曼编码是一种无前缀编码。解码时不会混淆。
Huffman 编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符号编长码,出现概率小的信源符号编短码,从而使平均码长最小。
为什么说huffman是贪心算法呢:
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。(来自百度百科)
而生成huffman编码的过程中有每次选出两个当前最小的频率的过程,使用到了贪心的思想。
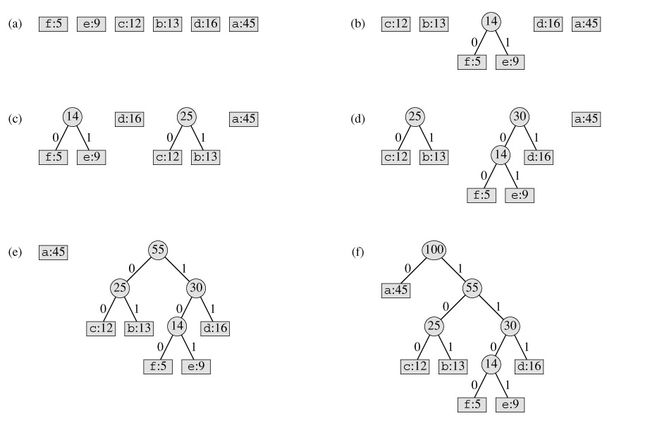
2.huffman编码生成:
2.1算法思路:
1)根据输入的字符串构建赫夫曼树。
2)遍历霍夫曼树并给每个字符分配编码。
建赫夫曼树的步骤:
算法:输入是没有相同元素的字符数组(长度n)以及字符出现的频率,输出是赫夫曼树。
即假设有n个字符,则构造出的赫夫曼树有n个叶子结点。n个字符的权值(频率)分别设为w1,w2,…,wn,则哈夫曼树的构造规则为:
(1)将w1,w2,…,wn看成是有n棵树的森林(每棵树仅有一个结点);
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的赫夫曼树。
节选自https://blog.csdn.net/will130/article/details/46425089
图来自:https://blog.csdn.net/mariofei/article/details/23030597
2.2java代码实现:
1.通过最小堆来构建优先队列,这样可以取出来当前最小值,并可以在生成节点后将和重新加入到优先队列中。
2.通过链表来构建二叉树,收成huffman树。
3.得到huffman树之后利用深度优先遍历算法得到每个叶子节点的编码。
//先生成huffman树,然后生成huffman编码
public static Map getHuffmanCode(Map frequencyMap){
//先生成huffman节点,放入到堆构造的优先队列中
Heap heap=new Heap();
for(Map.Entry entry:frequencyMap.entrySet()){
heap.add(new Node(entry.getKey(),entry.getValue()));
}
//生成huffman树:每次取出来两个最小的,然后放进去node
while (heap.getNum()>1){
Node tmp1=heap.poll(),tmp2=heap.poll();
heap.add(new Node(tmp1.frequency+tmp2.frequency,tmp1,tmp2));
}
//生成huffman编码:遍历所有的叶子节点即可,且设左节点为0右节点为1
Map codeMap=new HashMap<>();
dfs(heap.poll(),0,codeMap);
heap.clear();
return codeMap;
}
static void dfs(Node head, int pos, Map codeMap){
//如果是叶子节点,则将编码保存到map中
if(head.right==null&&head.left==null){
byte[] mycode=new byte[pos];
System.arraycopy(code,0,mycode,0,pos);
codeMap.put(head.myByte,mycode);
return;
}
if(head.left!=null){
code[pos]=0;
dfs(head.left,pos+1,codeMap);
}
if(head.right!=null){
code[pos]=1;
dfs(head.right,pos+1,codeMap);
}
} 3.压缩操作
3.1压缩流程
1.第一遍每8位(byte)读取文件统计频率得到huffman编码。
2.将huffman编码格式写入文件头中。
文件头格式:
文件补零长度,byte类型1个字节
有多少种byte:short类型2个字节
接下来写入每个byte及其编码对应的格式。(加大括号只是为了格式方便查看,并不是写入文件)
{
保存的值为,byte 1个字节
编码位数,byte1个字节
编码补零的长度,byte1个字节
值对应的编码,编码位数个长度。
}
3.第二遍读取文件,匹配到相应的huffman编码,然后将01串每8位转化为1个byte,写入文件得到压缩的文件。
将字节对应的huffman编码放到位流读写器,位流读写器满时则进行刷新操作,写到文件中。
写的时候是数组中每8位生成byte,索引低的位于高位
3.2如何实现编码:编码前的注意事项和知识储备。
实习期间的leader一直跟我强调说代码不是最重要的,那是基本功谁都会,重要的是思想,思路。所以这次写代码前我还是思考了一下。
3.2.1.文件读写是选择nio和普通的阻塞io:
阅读JAVA NIO(六):读取10G的文件其实很容易以及JAVA NIO(五):如何在5秒内写入10G的文本数据。发现nio以及包装流如buffer**putStream对于单一大文件读写速度并无明显提高,我决定仍然选择普通的输入输出流。
注意nio中关于文件的nio操作也是只有阻塞模式。
3.2.2.为什么选择每8位来读取和转换:
以8位读取可以直接转化成byte,比较方便,而且8位读取数据有256(2^8)种,在测试过程中发现对于100m的文件来说读出来只有200种左右的字节,所以没必要以其他位数读取了。而且最低也只能以8位读取。
需要注意的是java8种基本类型,byte为有符号数,范围为-128(-2^7)~127(2^7-1)。但是没关系,有符号也不影响转化。
3.2.3.有压缩就有解压缩,解压缩时需要知道byte和编码的对应关系,所以需要把这些信息写入到文件头。如何定义解压缩需要的文件头?
可以保存huffman树或者直接保存huffman编码。保存树可以参考:https://www.cnblogs.com/mengfanrong/p/4629121.html,保存huffman编码的参考:https://blog.csdn.net/jiangying_emma/article/details/82426810
我选择的是直接保存编码,自己感觉保存编码很方便。
文件第一个字节是补零长度,因为补零长度肯定<8所以一个字节就能占的下,注意补零长度只有在文件转化完成后才能得到,所以需要先将第一个字节随便写入一个数字,最后通过randomAccessFile来用真实值覆盖掉这个数字。
byte种类为1~256,一个byte无法记录,所以需要2个字节short来写入。
因为选择的是每8位转化一次,因此最多有2^8=256个数,对于最长的huffman编码,最长为255位01串(参考huffman树得出)而01串编码需要每8为转化成1个byte,因此用byte1个字节就可以记录下编码的位数。
注意java最多只能以字节为单位读取,所以位数不足8的整数位时需要补0。不仅是byte对应编码需要补零,整个文件压缩后的数据流末尾也需要补零。
3.2.4.01编码串用什么来存储,以及如何和byte互相转化:
01编码串直接用byte数组存储,01字符串每8位转化成byte直接就是二进制转化为10进制。
而byte转化成01串也比较简单:每次移位然后和1相与。因为1对应的二进制是一堆0然后是1,相与的话只剩下最后一位。
for(int m=7;m>=0;m--){
array[rear]=(byte)(b>>>m & 1);
rear = (rear+1)%array.length;
}3.2.5.转化的时候肯定不能一个字节一个字节的写和转换,有没有什么比较高效率的方法?
见下文的位流读写器概念。
3.3数据转化方式-位流读写器
位流读写器不是什么专有名词,是我突然想到之前多媒体老师上课讲到的关于输入输出流转化的一种方式:有兴趣的可以查看我之前写的博客:https://blog.csdn.net/qq_40493277/article/details/82751504老师提供的代码是c语言版本的,具体什么原理我也忘得差不多了,一年前的博客也不知道写的什么,c语言的指针操作也忘完了,看不懂代码,我只能照葫芦画瓢的模仿一个大概。
queueArray类为循环队列数据结构,存储01串,入队01串,出队byte字符。
byteContainer 中缓存转化的数据,其中的cache满了,则写入文件中。
3.4代码
见github地址。
4.解压
解压操作并不复杂:1.读取文件头,读出来数据编码01串,2.继续读取文件,将byte转成01串,放到queuearray中,然后和读取出来的byte对应编码相匹配。
我就不详细展开了,代码中有注释,自己可以对照着看。
5.Huffman和7zip效率对比
zip压缩原理,https://www.cnblogs.com/esingchan/p/3958962.html
一些格式的文件比如jpeg,内部已经使用过huffman压缩过数据了,因此对于这种数据来说基本没有压缩效果,甚至压缩出来的文件更大。因此本次比较直接选用文本文件作为输入样例,因为java不太好写脚本,所以我就直接手动比较一个文件的压缩与解压。而且对于内存占用我是通过任务管理器粗略的进行比较。其实java语言和c的内存占用没有可比性。
对于181MB的文件
huffma压缩,压缩率为64.6%,用时28.7s,解压缩用时65s。内存大概占了80M
7zip来说:压缩率为22%,用时大概30s左右,解压只用了8s(我也不知都为啥解压这么快)。内存大概为是12.4M。
由此可见zip压缩的优越性,而且huffman压缩在生产中一般是中间处理手段和其他的方式组合到一起用(参考最后的推荐阅读)。
6.优化手段-多线程
6.1原因
多线程并不是万能良药,对于基本的cpu密集型作业来说,单线程速度最快。而对于压缩来说涉及到了cou密集和io密集,在io阻塞的时候,我们可以通过多线程来利用cpu资源,这也是多线程可以加快速度的原因。
6.2生产者消费者模式。
对于当前任务需求,没有必要使用线程池。分为三个线程:读取文件线程,写文件线程和压缩线程。生产者为读取文件线程,消费者为压缩部分代码和写线程。而实现生产者消费者模式也很简单,使用javase提供的阻塞队列ArrayBlockingQueue。
注意的是多线程读写单一文件并没有什么明显速度优势,因为速度瓶颈在磁盘。
设立好线程模型后,任务流程和之前的一样,就不再细说。具体看代码。
6.3.效果展示。
同样是使用181MB大小的文件。两者的速度比较:
非多线程压缩:第一次读文件用时(ms)4766,共用时21168 ms
多线程压缩:第一次读文件用时(ms):3228,压缩总用时(ms):20620
6.4分析
可以见到总时间只有大概5%的提升,而第一次读取文件多线程则快了大概35%,可以见到多线程的确可以提高速度,但是后续的压缩阶段增加了写线程,可能是因为三者线程速率不太一致,所以导致上下文切换多了一点,导致时间增多,或者是压缩的时候cpu耗费时间比较多,增加线程来进行读写帮助不太大。可以继续测试找到速率限制点继续优化。
但是有一个问题就是压缩时间总是在20+-10秒的区间波动,因为磁盘也有缓存,所以这也是一个影响点。而且顺着磁盘头的移动方向读写会加快磁盘的读写速度,这也可能是影响原因。
7拓展阅读:
霍夫曼编码现在还有实际运用吗?
java读取大文件,采用多线程处理对提高效率可有帮助:
如果只是单纯的读文件,一个线程足够了,因为一般瓶颈是在磁盘io上,多个线程只会在磁盘io上阻塞。
但是一般是读一小块做一次处理,然后再读下一块,这样只用一个线程磁盘io有空闲的时间,就可以用多线程处理,有的线程在读数据有的线程在处理数据。而且磁盘是有缓存的,一次读48行,可能会缓存后面的1m内容,下n次其他线程来读的时候磁盘可以直接从缓存中取数据。估计线程数不会超过10个,太多线程仍然会阻塞在磁盘io上。但是随机读取文件无法利用缓存机制,而且硬盘不断的重新定位会花费大量的寻道时间,估计效率还比不上多个线程用同一个指针顺序读取文件。理论推测,具体还是得自己写程序跑一下。
java总是倾向于用多线程,很少接触到不同进程的通信,只用过socket通信。