数据库----如何将oracle语句转换成mysql语句
目录
- 前言
- 正文
- 简单函数之间的转换
- 具体实例:
- 一、当前时间--(sysdate)
- 二、日期转字符串--(to_char)
- 三、字符串转日期--(to_date)
- 四、判断空值--(nvl)
- 五、转换数字--(to_number)
- 六、条件判断--(decode)
- 七、时间串拼接--(numtodsinterval)
- 八、decimal的转换
- 九、substring的区别
- 十、时间的计算
- 十一、分组排序--(row_number() over)
- 补充知识说明:
- 1.在mysql中如何获取当前周
- 2.mysql实现row number over的原理
- 3.说一下mysql中表的别名问题
- 4.使用mysql实现rownum
- 5.使用mysql执行语句块
- 6.自增ID
- 7.使用mysql实现merge into
- 8.mysql实现connect by
- 9.mysql实现sum over(partition by column)
- 总结
前言
最近由于公司业务上需要,需要将原项目的数据库由oracle转换成mysql,转换的时候我们通常需要先将数据库转成mysql,然后再去为项目添加mysql语句,至于如何将oracle数据库转换成mysql数据库且保证数据库数据的正确性,可以参考我的上一篇文章,这篇文章的主要作用就是来讲一下oracle语句中用到的那些函数,在mysql中应该怎么使用。
文章地址:
将Oracle数据库转换成mysql数据库
正文
首先我们可以先来说一下oracle和mysql的区别,他们的区别就是我们改动的sql的原因。至于其他的区别我就不在这里多说了,主要是讲函数的区别,以及对应情况的处理.
Oracle最大的特点就是sql的灵活性,它具有强大的分组查询功能,而对应的函数在mysql中是没有的,那么我们如果想要实现同样的功能,就需要通过其他的方法来实现同样的功能。
简单函数之间的转换
快速查询:
column表示字段名
| 函数作用 | oracle | mysql |
|---|---|---|
| 日期转字符串 | to_char | date_format |
| 字符串转日期 | to_date | str_to_date |
| 判断空值 | nvl | IFNULL |
| 转换数字 | to_number | cast |
| 条件判断 | decode | case then或if else |
| 时间串拼接 | numtodsinterval | contact |
| decimal的转换 | to_char | cast(column as char) |
| 当前时间 | sysdate | now() |
| substring区别 | 开始位置可以为0 | 开始位置不能为0 |
| 时间的计算 | 可以直接相减(默认单位:天) | 使用 TIMESTAMPDIFF(需指定默认单位) |
| 分组排序 | row number over | 使用变量来实现 |
具体实例:
一、当前时间–(sysdate)
oracle语句:
select sysdate from dual
mysql语句:
select now()
二、日期转字符串–(to_char)
oracle语句:
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual
mysql语句:
select DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i:%s')
三、字符串转日期–(to_date)
oracle语句:
select to_date('2019-01-01 08:00:00', 'yyyy-mm-dd hh24:mi:ss') from dual
mysql语句:
select STR_TO_DATE('2019-01-01 08:00:00',"%Y-%m-%d %H:%i:%s")
四、判断空值–(nvl)
oracle语句:
NVL(a,b)
mysql语句:
IFNULL(a,b)
五、转换数字–(to_number)
oracle语句:
to_number(column)
mysql语句:
转换成整形:
cast(column as unsigned int)
转换成浮点型:
cast(column as decimal(10,2))
六、条件判断–(decode)
oracle语句:
select decode(mod(quantity,7),0,'A',1,'B','C') as qtype from biz_order
mysql语句:
使用case when:
Select case mod(quantity,7) when 0 then 'A'
when 1 then 'B'
else 'C'
end as qtype
from biz_order
使用if else:
不推荐使用if-else,因为我写不出来,建议使用case when,咳咳咳咳咳-----,
七、时间串拼接–(numtodsinterval)
oracle语句:
select a.*,
case when length(ltrim(substr(numtodsinterval(ceil(a.reportperiod), 'second'),2,15),'0')) = 6
then '0天' || substr(numtodsinterval(ceil(a.reportperiod), 'second'),12,8)
when a.reportperiod is null
then ''
else ltrim(substr(numtodsinterval(ceil(a.reportperiod), 'second'),2,9),'0') || '天' ||
substr(numtodsinterval(ceil(a.reportperiod), 'second'),12,8)
end as ReportWaitTime
from biz_dev_fault_repair_result a
mysql语句:
SELECT
a.*,
CONCAT(
FLOOR( a.reportperiod / 86400 ),
'天',
LPAD( FLOOR( a.reportperiod % 86400 / 3600 ), 2, 0 ),
':',
LPAD( FLOOR( a.reportperiod % 86400 % 3600 / 60 ), 2, 0 ),
':',
LPAD( CEIL( a.reportperiod % 86400 % 3600 % 60 ), 2, 0 )
) AS ReportWaitTime
FROM biz_dev_fault_repair_result a
八、decimal的转换
oracle语句:
select to_char(quantity) from biz_order
mysql语句:
需要注意的是,在mysql中转换时不能使用as varchar:
//SELECT cast(quantity as VARCHAR) from biz_order ----这是错误的语法
SELECT cast(quantity as CHAR) from biz_order ----这是正确的语法
九、substring的区别
oracle语句:
select substr('1234567890',0,2) from dual //返回结果12
mysql语句:
select substr('1234567890',1,2) //返回结果12,即相同返回结果
十、时间的计算
oracle语句:
select maintaintime,createtime,maintaintime-createtime t from biz_order
//返回结果以天为单位
mysql语句:
select maintaintime,createtime,TIMESTAMPDIFF(second,maintaintime,createtime) t from biz_order
//返回结果以秒为单位,直接相减默认结果说实话我没看懂是以什么为单位,它是每分钟为100,秒数作为十分位和百分位,逢60就加100
返回结果以秒为单位,直接相减默认结果说实话我没看懂是以什么为单位,它是每分钟为100,秒数作为十分位和百分位,逢60就加100
十一、分组排序–(row_number() over)
oracle语句:
SELECT a.*,
ROW_NUMBER() OVER(partition by a.orderchildId order by a.CheckEndTime desc) as rum_num
FROM biz_qa_check_first a
mysql语句:
select @rownum:=@rownum+1 rownum,a.*,
if(@orderchildId=a.orderchildId,@rank:=@rank+1,@rank:=1) as rum_num,
@orderchildId:=a.orderchildId
from(SELECT * from biz_qa_check_first order by orderchildId,CheckEndTimedesc)a,
(select @rownum:=0,@orderchildId:=null,@rank:=0)b
补充知识说明:
1.在mysql中如何获取当前周
oracle语句:
select to_char(sysdate,'iw') from dual
返回结果:
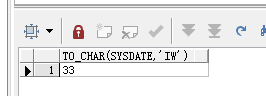
这表示2019-08-18是该年的第33个周
mysql语句:
SELECT DATE_FORMAT(now(),'%u')
//大写U与小写u不一样
返回结果:

下面附上mysql中日期标识符的作用,
%M 月名字(January……December)
%W 星期名字(Sunday……Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。)
%Y 年, 数字, 4 位 www.2cto.com
%y 年, 数字, 2 位
%a 缩写的星期名字(Sun……Sat)
%d 月份中的天数, 数字(00……31)
%e 月份中的天数, 数字(0……31)
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%k 小时(0……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%i 分钟, 数字(00……59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ……6=Saturday )
%U 星期(0……52), 这里星期天是星期的第一天
%u 星期(0……52), 这里星期一是星期的第一天
%% 一个文字“%”。
2.mysql实现row number over的原理
在oracle中,ROW_NUMBER() OVER(partition by col1 order by col2) 表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内是连续且唯一的)。
然后在mysql中没有对应的函数,所以我们选择使用变量来实现,那么具体的实现过程是什么?下面一起来看一下
oracl语句:
SELECT a.*,
ROW_NUMBER() OVER(partition by a.orderchildId order by a.CheckEndTime desc) as rum_num
FROM biz_qa_check_first a
mysql语句:
select @rownum:=@rownum+1 rownum,a.*,
if(@orderchildId=a.orderchildId,@rank:=@rank+1,@rank:=1) as rum_num,
@orderchildId:=a.orderchildId
from(SELECT * from biz_qa_check_first order by orderchildId,CheckEndTimedesc)a,
(select @rownum:=0,@orderchildId:=null,@rank:=0)b
假如我们的数据库对应的数据是下表
| orderchildid |
|---|
| 10 |
| 10 |
| 10 |
| 11 |
| 12 |
mysqlsql运行步骤:
查询第一行,此时的变量值
| @rownum | @orderchildId | @rank |
|---|---|---|
| 0 | null | 0 |
判断条件执行此时orderchilidid不相等,将@rank=1,将@orderchilidid=10
查询第二行,此时的变量值:
| @rownum | @orderchildId | @rank |
|---|---|---|
| 1 | 10 | 1 |
判断条件执行此时orderchilidid相等,将@rank=@rank+1,将@orderchilidid=10
查询第三行,此时的变量值:
| @rownum | @orderchildId | @rank |
|---|---|---|
| 2 | 10 | 2 |
判断条件执行此时orderchilidid相等,将@rank=@rank+1,将@orderchilidid=10
查询第四行,此时的变量值:
| @rownum | @orderchildId | @rank |
|---|---|---|
| 3 | 10 | 3 |
判断条件执行此时orderchilidid不相等,将@rank=1,将@orderchilidid=11
查询第五行,此时的变量值:
| @rownum | @orderchildId | @rank |
|---|---|---|
| 4 | 11 | 1 |
判断条件执行此时orderchilidid不相等,将@rank=1,将@orderchilidid=12
对于以上步骤最终的结果对应的表如下
| orderchildid | @rank |
|---|---|
| 10 | 1 |
| 10 | 2 |
| 10 | 3 |
| 11 | 1 |
| 12 | 1 |
那么在我们做完查询之后,只需要指定查询出@rank=1的就是实现了以orderchildid分组,由于我们设置了别名,所以我们的筛选条件可以写为 where rum_num=1,这样我们就实现了分组,而在分组之前,我们的嵌套查询已经实现了排序功能。
3.说一下mysql中表的别名问题
比如说这条sql吧
select *from (
select distinct a.*,e.name workshopname,f.name rolename,h.name shiftname, m.row_num
from biz_base_person_group a
left join biz_base_person_group_asso b on a.id=b.GroupId
left join biz_base_person_group_dev d on a.id = d.groupid
left join biz_base_workshop e on a.workshopid = e.id
left join sys_role f on a.roleid = f.id
left join biz_base_shift g on a.classcode = g.code
left join v_sys_dict h on g.code = h.code and h.pCode = 'ShiftType' and h.type = 'zh_CN'
left join (select a.id ,if(@id=a.id,@rank:=@rank+1,@rank:=1) as row_num,
@id:=a.id
from (SELECT *from biz_base_person_group order by id) a) m on a.id = m.id
) a
where a.row_num = 1
order by maintaintime desc
首先我们看到,我们将内部的查询结果作为一个表,但是其实我们可以看一下,通常我们写sql的时候,写
select *from table where column=’’
这里我不为表名别名也应该可以,但是在mysql中,不为表名别名会报这个错误,但是在oracle中就可以,这个希望大家以后注意

4.使用mysql实现rownum
首先看一下oracle的语句:
select rownum rn ,a.* from
(
select a.*,b.name typename,c.value from sys_res_i18n a
left join sys_dict b on a.type = b.code and b.pcode = 'I18nType'
left join sys_res_i18n_type c on a.id = c.pid and c.type = 'zh_CN'
order by a.id desc
) a
返回的结果:

我第一次写出的mysql语句,是这样的
select @rownum:=@rownum+1 rn,a.* from
(
select a.*,b.name typename,c.value from sys_res_i18n a
left join sys_dict b on a.type = b.code and b.pcode = 'I18nType'
left join sys_res_i18n_type c on a.id = c.pid and c.type = 'zh_CN'
order by a.id desc
) a,
(SELECT @rownum:=0) b
返回的结果相同,但是使用我们公司框架的时候会出现转换问题,在页面的数据会显示为

这对客户来说就很尴尬,不知道出现这问题的原因是什么,debug之后发现通过反射调用方法之后,返回的就带有.0,最后我将sql语句改了一下,写成下面的形式,完美解决问题.
select cast(@rownum:=@rownum+1 as char) rn,a.* from
(
select a.*,b.name typename,c.value from sys_res_i18n a
left join sys_dict b on a.type = b.code and b.pcode = 'I18nType'
left join sys_res_i18n_type c on a.id = c.pid and c.type = 'zh_CN'
order by a.id desc
) a,
(SELECT @rownum:=0) b
补充: 并不是所有的rownum都需要这么来实现,假如前台不需要rownum的值,你可以看一下具体的业务,很可能他的sql只是想取出第一条数据,在mysql中你可以直接使用limit关键字就能拿到数据。
5.使用mysql执行语句块
在Oracle中执行语句块应该以下面的形式:
begin
insert into sys_sequence(ObjectName, Id, CreateTime)
select '${tableobjname}', 1, sysdate from dual where not exists (
select 1 from sys_sequence where ObjectName = '${tableobjname}') ;
update sys_sequence set id = (select nvl(max(id), 1) from ${tableobjname}) where ObjectName = '${tableobjname}';
end;
在mysql中执行语句块,不需要添加begin和end
insert into sys_sequence(ObjectName, Id, CreateTime)
select '${tableobjname}', 1, sysdate from dual where not exists (
select 1 from sys_sequence where ObjectName = '${tableobjname}') ;
update sys_sequence set id = (select nvl(max(id), 1) from ${tableobjname}) where ObjectName = '${tableobjname}';
6.自增ID
MySQL不存在sequence,所以在进行数据插入时,需要自增的列需要特殊处理。
oracle:
select seq_id.nextval from dual
MySQL:更改表中需要自增的列,如id,更改语句如下:
alter table biz_order modify id int auto_increment primary key
在mysql中执行插入时,就不用列出id。
7.使用mysql实现merge into
oracle语句:
merge into biz_url_request_para a
using (select #{clientid} as clientid, #{url} as url, #{para} as para from dual) b
on (a.clientid = b.clientid and a.url = b.url and a.clientid = #{clientid})
when matched then
update set a.para = b.para, timestamp = to_char(sysdate,'yyyy-mm-dd hh24:mi:ss')
when not matched then
insert values(#{clientid}, #{url}, #{para}, to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'))
mysql
insert into biz_url_request_para
(
clientid,
url,
para,
timestamp
)
values (
#{clientid},
#{url},
#{para},
date_format(now(),'%Y-%m-%d %H:%i:%s')
)
on duplicate key update para = values(para), timestamp = values(timestamp)
8.mysql实现connect by
首先,关于connect by这个用法我也不是很清楚,具体的大家可以参考这篇文章,但是我这里举的例子,因为功能业务的需求,不是像下面文章一样的例子。在mysql中,这里这处业务的实现通过substring_index函数来实现,同样也有一篇推荐文章。下面我会解释我所要讲的内容。
文章地址:
(一)connect by 和level 的用法
(一)字符串截取之substring_index
首先我们先看一下数据。
我们数据库中的数据是这个样子

我需要的结果就是以’,’为分割线,将所有的结果都查询出来,结果就是这个样子的。

我们这里就要使用substring_index函数,但是我们在使用这个函数的时候,需要指定count的值,但是我们不知道数据库中有多少个数据,所以我们不能写一个明确的值,这个时候,我们需要另外一张表来协助,这张表的值是下面的形式
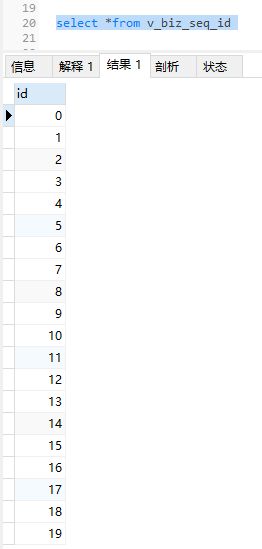
就是从0开始增长,那么我们写出来的sql语句为
SELECT a.id,SUBSTRING_INDEX(SUBSTRING_INDEX(a.exceptiontype,',',b.Id+1),',',-1) as name
from biz_mold_maintain_result a
left join v_biz_seq_id b
on b.Id < (LENGTH(a.exceptiontype)-LENGTH(REPLACE(a.exceptiontype,',',''))+1)
where a.id=1
首先我们来看on条件的意思,前面的length结果是10,后面的length里面嵌套了一个replace,是将字段中的‘,’替换为空,结果是8,那么这是什么意思?通过这个结果,我们可以知道的是该字段中有几个需要切割的值,前面我已经将字段中的值贴出了,我们可以看到,一共有三个值。那么我们这里计算出来的结果也是3,但是由于我们协助表从0开始,所以我们条件选择<3。
这里使用了两次substring_index来切割字符串,第一次的时候,b.id=0,那么内部的substring_index切出来的字符串为‘HMFQ’,外部的从右往左切割拿到的字符串同样是它本身,因为结果只有一个。
第二次执行的时候,内部的substring_index切出来的字符串切出的结果是’HMFQ,XC’,外部的从右往左切,得一个,那么它拿到的就是’XC’。
第二次执行的时候,内部的substring_index切出来的字符串切出的结果是’HMFQ,XC,AS’,外部的从右往左切,得一个,那么它拿到的就是’AS’。
我们就是通过这种方式来实现了递归查询。
9.mysql实现sum over(partition by column)
还是先拿出oracle语句以及查询结果:
select distinct a.scrapreason,
sum(a.scrapcount) over(partition by a.itemid) as scrapcount,
sum(a.scrapcount) over(partition by a.factoryid) as count
from da_qa_scrap_daily a
left join biz_base_workshop b on a.workshop = b.code and a.factoryid = b.factoryid
where 1=1
and a.checktype = 'QaCheckFirst'
查询出的结果:
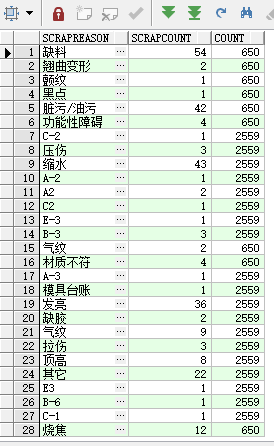
解释一下oracle语句的作用,他是将数据以项目id即itemid分组计算出每个项目的报废产品数量,又以工厂id,即factoryid分组计算出总项目的报废数量,但是却是以itemid分组后的结果来显示数据。在mysql中,我没有想到很好的实现方法,就把两个sum over拆分成了两张表,第一张以itemid分组计算出报废产品数量,第二张以工厂id分组计算出全部产品报废数量,然后通过其中一个字段来进行左连接,因为我们都是从同一张表中拿的数据,一定可以找到这个字段。最后写成的mysql语句如下:
select distinct
a.*,b.count count
from
(
select a.*,b.name workshopname,b.id workshopid ,sum(a.scrapcount) itemscrapcount from
da_qa_scrap_daily a
left join biz_base_workshop b on a.workshop = b.code and a.factoryid = b.factoryid
where 1=1 and a.checktype = 'qacheckfirst'
group by a.itemid
) a
left join
(
select a.*,sum(a.scrapcount) count from da_qa_scrap_daily a
left join biz_base_workshop b on a.workshop = b.code and a.factoryid = b.factoryid
where 1=1 and a.checktype = 'qacheckfirst'
group by a.factoryid
) b on a.factoryid=b.factoryid
如果你有更好的实现方法,欢迎在下面评论留言或者私信我。
由于写的都是在转换过程中遇到的一些函数问题,所以整理了一下,当然也有未解决的问题,比如oracle中的connect by函数的实现,我在网上看的教程就是通过自己创建存储过程来实现同样的效果,这个就涉及到我的知识盲区了,如果我弄懂了之后会在这里补充.
总结
在这里和大家说一下转换之中的感想吧,其实在转换的时候我们大可不必担心,只要自己慢慢来,先明白原先sql的作用的,包括从哪张表的查询,查询了什么字段。在你转换的过程中,一步步的分解,先解决嵌套查询中的转换工作,在看外部查询有没有需要转换的内容,大部分的函数mysql和oracle中还是相同的,比如一些聚合函数的使用,这都不需要你更改。转换时要细致。
如果文章哪里有写的不对的地方,欢迎指出!!!
咸鱼IT技术交流群:89248062,在这里有一群和你一样有爱、有追求、会生活的朋友! 大家在一起互相支持,共同陪伴,让自己每天都活在丰盛和喜乐中!同时还有庞大的小伙伴团体,在你遇到困扰时给予你及时的帮助,让你从自己的坑洞中快速爬出来,元气满满地重新投入到生活中!