Transferable Joint Attribute-Identity Deep Learning for Unsupervised Person Re-Identification
1.引入
行人重识别中无监督学习:从源域有标签数据中学习到关于行人视图不变信息的特征表示,然后将模型转移、并且使之适用到无标签数据的目标域中。
大多数现有的人员重新识别(re-id)方法都需要从每个摄像机对的一大套成对标记的训练数据的单独大集合中进行监督模型学习。 由于需要跨许多摄像机视图执行重新识别,这极大地限制了它们在现实世界大规模部署中的可扩展性和可用性。 为了解决此可伸缩性(scalability)问题,作者提出了一种新颖的深度学习方法,将现有数据集的标记信息转移到一个新的看不见(未标记)的目标上,来进行人员重新识别,而无需在目标域中进行任何监督学习。 具体来说,引入了**可转移的联合属性身份深度学习(TJ-AIDL)**方法,用于同时学习可转移到任何新(未知)目标域的属性语义和身份识别特征表示空间,而无需从从目标域中添加新的标签训练数据。
2 介绍
这篇文章主要有三个贡献:(1)提出了一种新的思想,即关于属性和身份识别异构多任务联合深度学习(heterogeneous multi-task joint deep learning),用于无监督的人重新识别。这是第一次尝试辅助属性和身份标签的联合深入学习,以解决无监督的行人重识别问题跨域。 (2)采用可转让联合属性-身份深度学习(Transferable Joint Attribute-Identity Deep Learning—TJ-AIDL)通过身份推断属性(Identity Inferred Attribute-IIA)同时从标记的源域人图像中学习全局身份和局部属性信息最大化身份和属性之间联合学习有效性的步伐。 这个IIA是专门为解决臭名昭著的异方差挑战而设计的,公共空间多任务联合学习经常遭受这种挑战。 重要的是,IIA与属性和身份学习任务相互依赖地同时交互,而不破坏端到端的模型学习 进程。 (3)介绍了一种在未标记目标数据上进行TJ-AIDL模型无监督自适应的属性一致性方案,进一步增强了它对即将到来的每个目标域re-id任务的区分兼容性。
问题定义:对于基于属性(语义)的无监督域自适应行人重识别,有一个有标记的源数据 { ( I i s , y i s , a i s ) } i = 1 N s \{(I_{i}^s,y_{i}^s,a_{i}^s)\}^{N_s}_{i=1} {(Iis,yis,ais)}i=1Ns,其中包括 N s N^s Ns个行人边界框图像 I s I^s Is,相应的身份 y s ∈ { 1 , … … N i d s } y^s\in\{1,……N_{id}^s\} ys∈{1,……Nids},(即,总共有 N i d s N_{id}^s Nids个不同行人),并且身份级二进制属性标签 a s ∈ R m × 1 a_s\in R^{m×1} as∈Rm×1(即一个人总共有m个不同属性),同时假设了 N t Nt Nt未标记的目标训练数据的一组 { I i t } i = 1 N t \{I_{i}^t\}_{i=1}^{N^t} {Iit}i=1Nt ,可用于模型域自适应。目标是发展一个无监督的领域适应方法,通过将源域的有监督身份和属性知识传递给目标域中的人员re-id,其中目标域仅使用完全不同身份类别池的未标记数据,从而来学习最佳的特征表示。注意点:(1)由于一个人同时有m个属性类别,属性标签是多标签识别问题(2)属性是图像区域局部问题,而人的身份是整体图像而言。所以这是一项不平凡的学习任务,因为这不仅是一个多标签(multi-label)学习问题—相互关联的属性标签的联合学习,而且是一个异构的多任务(heterogeneous multi-task)联合学习问题—通过整体身份和局部属性监督相互依赖地学习一个人的re-id表示空间 。
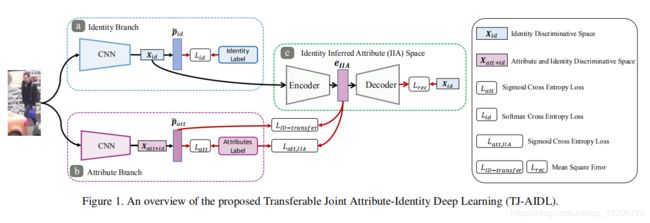
模型概览:如上图是TJ-AIDL(Transferable Joint Attribute-Identity Deep Learning)方法的概览,作者将身份和属性分为两个独立的分支来同时学习,更重要地,作者设计一个渐进的知识融合机制,即在身份分支后设计了一个IIA(Identity Inferred Attribute)正则化空间来将全局身份信息更加平滑地迁移到局部属性特征表示空间中。也正是IIA允许在没有身份和属性标签可用的情况下,将学习的模型适应目标领域。因此,在更具挑战性的跨域环境中,提出的TJ-AIDL在很大程度上解决了共享表示空间中异构身份和属性标签信息源的联合学习挑战。下面看一下各个模块的细节。
身份属性分支(Identity and Attribute Branches):作者选择了轻量级的MobileNet作为身份和属性分支中CNN架构。
对于身份分支的损失函数,采用的是softmax 交叉熵损失函数:

其中 p i d ( I i s , y i s ) p_{id}(I_i^s,y_i^s) pid(Iis,yis)指 I i s I_i^s Iis的标注好的真实类别 y i s y_i^s yis的预测概率, n b s n_{bs} nbs表示批次的大小。
对于属性分支,由于是一个多标签学习任务,要考虑所有m种属性类别,所以这里采用了sigmoid交叉熵损失函数:

其中, a i , j a_{i,j} ai,j和 p a t t ( I i , j ) p_{att}(I_i,j) patt(Ii,j)分别表示关于训练图像 I i I_i Ii的第j个属性的真实标签和预测概率。也就是说, a i = [ a i , 1 , … , a i , m ] a_i=[a_{i,1},…,a_{i,m}] ai=[ai,1,…,ai,m], p a t t , i = [ p a t t ( I i , 1 ) , … , p a t t ( I i , m ) ] p_{att,i}=[p_{att}(I_i,1),…,p_{att}(I_i,m)] patt,i=[patt(Ii,1),…,patt(Ii,m)]。
可以看到,两个分支是独立地优化其各自的功能,而没有利用其互补效应来最大化兼容性(这种情况下,可能会遭受异方差问题的影响,最终导致结果不是最佳的)。
身份推测属性空间(Identity Inferred Attribute Space):IIA空间是与两个分支共同学习的,同时被利用来同时执行从身份分支到属性分支的信息传输和融合。在整个训练过程中该方案利于一致和累积的知识融合。如图1所见, 在编解码(自动编码器 auto-encoder)框架中构建IIA空间, 由于:(1)它具有很强的能力,能够通过简洁的特征向量表示捕获给定目标任务(由输入数据表示)的最重要信息;(2)更重要的是,一个简洁的功能表示有助于任务间信息传递,同时仍为每个单独的学习任务保留足够的更新自由空间。作者称之为子模型IIA编码器-解码器( sub-model IIA encoder-decoder)。
如图1(a) (c )所示,将身份特征 x i d x_{id} xid作为编码器的输入,同时作为解码器的真实数值,一旦给予输入, 该模型本身可以基于重建损失(均方误差(MSE)来学习)):
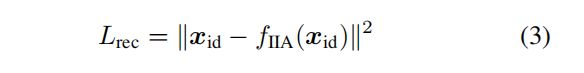
其中, x i d x_{id} xid是指训练图像的输入特征, f I I A ( ) f_{IIA}() fIIA()是IIA编解码的特征映射,通过这一个无监督行为,获得潜在特征嵌入 e I I A e_{IIA} eIIA,考虑到跨分支传递身份信息,作者这里将IIA的嵌入 e I I A e_{IIA} eIIA与所有m个属性类的预测分布对齐, 也就是将m设置为 e I I A e_{IIA} eIIA的维度,以方便对齐和跨分支知识转移,而不需要额外的转换。同样地采取MSE进行身份转移损失:

其中 p ~ a t t \widetilde{p}_{att} p att是来自属性分支的logits(网上的解释:知识蒸馏的paper,里面定义的是(the input of the final softmax))。 考虑到 e I I A e_{IIA} eIIA是以一种无监督的方式导出的,这可能超出了属性预测对应的范围,从而导致更困难的对齐任务。对此,作者通过利用 e I I A e_{IIA} eIIA作为伪属性的预测,在 e I I A e_{IIA} eIIA的学习中添加了一个sigmoid交叉熵损失函数:

其中, p I I A ( I i , j ) p_{IIA}(I_{i},j) pIIA(Ii,j)基于 e I I A e_{IIA} eIIA的sigmoid函数预测的概率。
最后,总体的IIA损失函数是通过加权求和,将上述分量进行合并:
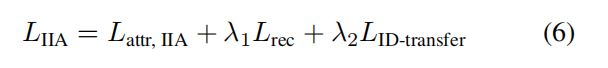
其中λ1和λ2是规模归一化参数,以确保所有三个损失量的价值是相似的规模。
由于IIA是基于身份特征建立的,因此对该分支的学习没有施加任何变化。然而,对于属性分支,为身份知识转移创建了一个额外的学习约束。 因此,通过合并Eq.4重新制定了它的监督学习损失函数:

总的来看,模型联合训练中的主要信息流:(1)身份分支学习提取身份鉴别信息; (2)然后,IIA组件将身份信息传输到attribute分支; (3) 属性分支学习提取属性鉴别知识,同时合并/融合身份敏感信息。 但是,由于在实际部署场景中不可避免地存在域移位,因此在标记的源数据上学习的TJ-AIDL模型对于通常在未标记的目标域中的re-id仍然不是最佳的,这就导致了模型无监督域自适应的必要性。

无监督的目标域适应( Unsupervised Target Domain Adaptation):调整学习的TJ-AIDL模型以适合未标记的目标域数据。作者观察到,即一个拟合良好的TJ-AIDL模型应该在两个不同的属性视角(将属性分支的预测和IIA组件的嵌入视为来自不同领域的不同属性视角)之间具有很小的差异(图2(a)),基于此,作者提出了属性一致性原理。换句话说,它们的一致性程度表明模型对给定域的适应程度。 这也部分地体现了循环一致性机制的精神。
进而作者设计以下自适应算法:(1)将在源域上学习的TJ-AIDL模型部署到未标记的目标人物图像上,以从属性分支获得属性预测值 p a t t , t p_{att,t} patt,t。 (2)然后,我们利用软标签 p a t t , t p_{att,t} patt,t作为伪标注数据来更新属性分支和IIA组件,以减少域之间的属性差异(图2(b))。 直观上,此软属性标签是必需的,因为我们需要通过保持从源域获得的最具属性的判别能力来防止模型过度漂移。 (3)我们根据目标训练数据调整模型,直到收敛为止。
该模型的具体算法如下:
