SpringBoot2.x系列教程42--整合使用JPA
SpringBoot2.x系列教程42--整合使用JPA
作者:一一哥
一. JPA简介
1. JPA概念
JPA是Sun官方提出的Java持久化规范,是Java Persistence API的简称,中文名‘Java持久层API’,它本质上是一种ORM规范。
JPA通过 JDK 5.0 的 注解或XML 两种形式来描述 ‘对象--关系表’ 的映射关系,并将运行期的实体对象持久化到数据库中。
2. JPA出现的原因
Sun引入 JPA 规范是出于两个原因:
- 1. 简化现有Java EE和Java SE的开发工作;
- 2. Sun希望整合ORM技术,实现天下归一。
也就是说,Sun提出JPA规范的目的就是想以官方身份来统一各种ORM框架的规范,包括著名的Hibernate、TopLink等。这样就可以避免开发者为了使用Hibernate,要学习一套ORM框架;为了使用TopLink框架,又要再学习一套ORM框架,免去了重复学习的过程!
3. JPA涵盖的技术
JPA的总体思想和现有的Hibernate、TopLink、JDO、Mybatis等ORM框架大体一致。
总的来说,JPA包括以下3方面的技术:
(1).ORM映射元数据
JPA支持XML和JDK 5.0中的注解两种形式,通过元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
(2).JPA的API
用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。
(3).查询语言
通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
4. JPA与其他ORM框架的关系
JPA的本质是一种ORM规范(不是ORM框架,因为JPA并未提供ORM实现,只是制定了规范),而非实现。
它只提供了一些相关的接口,但是这些接口并不能直接使用,JPA的底层需要某种JPA实现,而Hibernate等框架则是对JPA的一种具体实现。
也就是说JPA仅仅是一套规范,不是一套产品, Hibernate, TopLink等都是实现了JPA规范的一套产品。
Hibernate 从3.2开始,就开始兼容JPA。Hibernate3.2获得了Sun TCK的 JPA(Java Persistence API)兼容认证。
所以JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现,他们之间并不是对标的关系,下图可以表明他们之间的关系。 

Hibernate属于遵循JPA规范的一种实现,但是Hibernate还有其他要实现的规范。所以它们的关系更类似于是:
JPA是一种做面条的标准规范,而Hibernate是一种遵循做面条规范的具体的汤面;它不仅遵循了做面条的规范,同时也会遵循做汤和调料的其他规范。
5. JPA中的注解

二. Spring Boot整合JPA实现过程
1. 创建web程序
我们按照之前的经验,创建一个web程序,并将之改造成Spring Boot项目,具体过程略。
2. 添加依赖包
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
com.alibaba
druid
1.1.10
3. 添加配置文件
创建application.yml配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/db4?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: syc
driver-class-name: com.mysql.jdbc.Driver #驱动
jpa:
hibernate:
ddl-auto: update #自动更新
show-sql: true #日志中显示sql语句
jpa.hibernate.ddl-auto是hibernate的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。
该参数的几种配置如下:
-
·create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
-
·create-drop:每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
-
·update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会。
-
·validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
4. 创建实体类
package com.yyg.boot.domain;
import lombok.Data;
import lombok.ToString;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/30
* @Description Description
*/
@Data
@ToString
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
@Column
private String birthday;
@Column
private String sex;
@Column
private String address;
}
5. 创建DataSource配置类
package com.yyg.boot.config;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/30
* @Description 第二种配置数据源的方式
*/
@Data
@ComponentScan
@Configuration
@ConfigurationProperties(prefix="spring.datasource")
public class DbConfig {
private String url;
private String username;
private String password;
@Bean
public DataSource getDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
return dataSource;
}
}
6. 创建JPA实体仓库
package com.yyg.boot.repository;
import com.yyg.boot.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
public interface UserRepository extends JpaRepository {
}
7. 创建Controller测试接口
package com.yyg.boot.web;
import com.yyg.boot.domain.User;
import com.yyg.boot.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserRepository userRepository;
@GetMapping("")
public List findUsers() {
return userRepository.findAll();
}
/**
* 注意:记得添加@RequestBody注解,否则前端传递来的json数据无法被封装到User中!
*/
@PostMapping("")
public User addUser(@RequestBody User user) {
return userRepository.save(user);
}
@DeleteMapping(path = "/{id}")
public String deleteById(@PathVariable("id") Long id) {
userRepository.deleteById(id);
return "success";
}
}
8. 创建Application启动类
package com.yyg.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
@SpringBootApplication
public class JpaApplication {
public static void main(String[] args) {
SpringApplication.run(JpaApplication.class, args);
}
}
完整项目结构:
9. 测试接口
在浏览器中进行get查询:
在postman中执行添加操作: 

在postman中执行删除操作: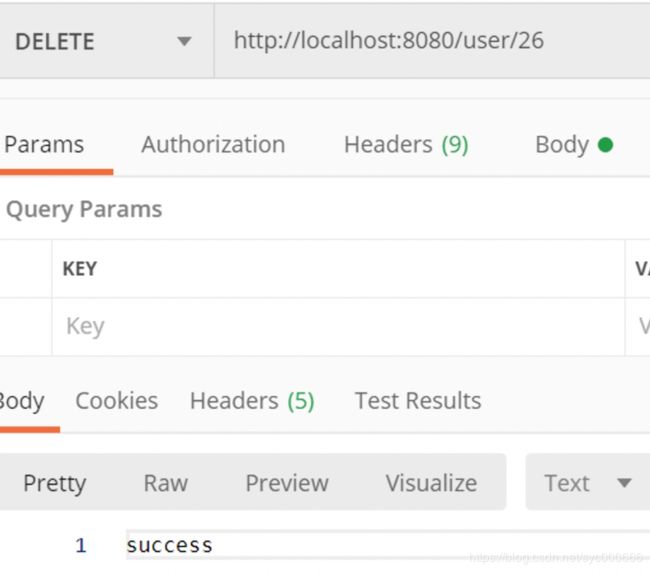
10. JPA实现原理
JPA会根据方法名来生成sql查询语句,它遵循的是Convention over configuration(约定大约配置)的原则,遵循Spring 以及JPQL定义的方法命名。
Spring提供了一套可以通过命名规则进行查询构建的机制,这套机制会把方法名首先过滤一些关键字,比如 find…By, read…By, query…By, count…By 和 get…By...
然后系统会根据关键字将命名解析成2个子语句,第一个 By 是区分这两个子语句的关键词。这个 By 之前的子语句是查询子语句(指明返回要查询的对象),后面的部分是条件子语句。
如果直接就是 findBy… 返回的就是定义Respository时指定的领域对象集合,同时JPQL中也定义了丰富的关键字:and、or、Between等等,下面我们来看一下JPQL中有哪些关键字: