前言:
纵观近几年的国产电影市场,“开心麻花“似乎已经成为了票房的保证。从《夏洛特烦恼》、《羞羞的铁拳》到最新上映的《西虹市首富》都引爆了票房。本期我们会根据从猫眼电影网爬取到的上万条评论为你解读《西虹市首富》是否值得一看。

01 数据爬取
此次数据爬取我们参考了之前其他文章中对于猫眼数据的爬取方法,调用其接口,每次取出部分数据并进行去重,最终得到上万条评论,代码如下:
数据分析:
我们看一下所得到的数据:

数据中我们可以得到用户的昵称,方便后面进行去重。后面的部分主要围绕评分、城市、评论展开。
首先看一下,评论分布热力图:
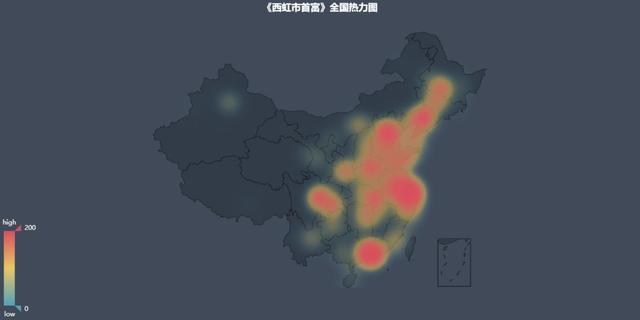
京津翼、江浙沪、珠三角等在各种榜单长期霸榜单的区域,在热力图中,依然占据着重要地位。同时,我们看到东三省和四川、重庆所在区域也有着十分高的热度,这也与沈腾自身东北人&四川女婿的身份不谋而合(以上纯属巧合,切勿较真)
下面我们要看的是主要城市的评论数量与打分情况:

打出最高分4.77分的正是沈腾家乡的省会城市哈尔滨(沈腾出生于黑龙江齐齐哈尔),看来沈腾在黑龙江还是被广大父老乡亲所认可的。最低分和次低分来自于合肥和郑州,今后的开心麻花可以考虑引入加强在中部地区的宣传。
我们按照打分从高到底对城市进行排序:
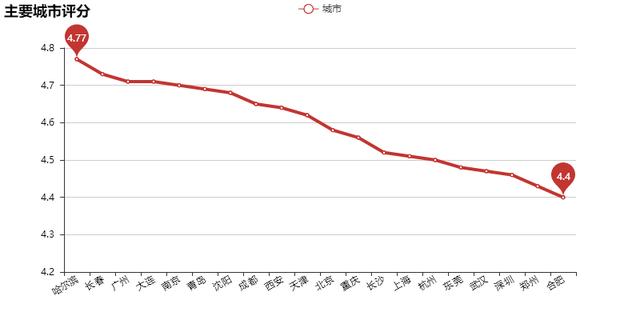
在评论数量最多的二十个城市中,评分前七名的城市中东北独占四席,而分数相对较低的城市中武汉、合肥、郑州都属于中部地区,可见不同地区的观众对影评的认可程度有着一定差异。
我们把城市打分情况投射到地图中:(红色表示打分较高,蓝色表示较低)

进一步,我们把城市划分为评分较高和较低两部分。
较高区域:

较低区域:

可以看到对于“西红柿”,南北方观众的评价存在一定差异,这与每年春晚各个地区收视率似乎有一些吻合知乎。沈腾本身也是春晚的常客,电影中自然会带一些“春晚小品味”,这似乎可以一定程度上解释我们得到的结果。
看过了评分,我们看一下评论生成的词云图,以下分别是原图和据此绘制的词云图:


不知道大家的想法如何,至少在我看到了这样的词云,搞笑、笑点、值得、开心、不错,甚至是哈哈都会激起我强烈的看片欲望。同时,沈腾也被大家反复提起多次,可以预见其在片中有着非常不错的表演,也会一定程度上激发大家看片的欲望。
03 部分代码展示
1. 热力图
tomato_com = pd.read_excel('西虹市首富.xlsx')
grouped=tomato_com.groupby(['city'])
grouped_pct=grouped['score'] #tip_pct列
city_com = grouped_pct.agg(['mean','count'])
city_com.reset_index(inplace=True)
city_com['mean'] = round(city_com['mean'],2)
data=[(city_com['city'][i],city_com['count'][i]) for i in range(0,
city_com.shape[0])]
geo = Geo('《西虹市首富》全国热力图', title_color="#fff",
title_pos="center", width=1200,
height=600, background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, type="heatmap", visual_range=[0, 200],visual_text_color="#fff",
symbol_size=10, is_visualmap=True,is_roam=False)
geo.render('西虹市首富全国热力图.html')
2. 折线图+柱形图组合
city_main = city_com.sort_values('count',ascending=False)[0:20]
attr = city_main['city']
v1=city_main['count']
v2=city_main['mean']
line = Line("主要城市评分")
line.add("城市", attr, v2, is_stack=True,xaxis_rotate=30,yaxis_min=4.2,
mark_point=['min','max'],xaxis_interval =0,line_color='lightblue',
line_width=4,mark_point_textcolor='black',mark_point_color='lightblue',
is_splitline_show=False)
bar = Bar("主要城市评论数")
bar.add("城市", attr, v1, is_stack=True,xaxis_rotate=30,yaxis_min=4.2,
xaxis_interval =0,is_splitline_show=False)
overlap = Overlap()
# 默认不新增 x y 轴,并且 x y 轴的索引都为 0
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
overlap.render('主要城市评论数_平均分.html')
3. 词云
tomato_str = ' '.join(tomato_com['comment'])
words_list = []
word_generator = jieba.cut_for_search(tomato_str)
for word in word_generator:
words_list.append(word)
words_list = [k for k in words_list if len(k)>1]
back_color = imread('西红柿.jpg') # 解析该图片
wc = WordCloud(background_color='white', # 背景颜色
max_words=200, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=300, # 显示字体的最大值
stopwords=STOPWORDS.add('苟利国'), # 使用内置的屏蔽词,再添加'苟利国'
font_path="C:/Windows/Fonts/STFANGSO.ttf",
random_state=42, # 为每个词返回一个PIL颜色
# width=1000, # 图片的宽
# height=860 #图片的长
)
tomato_count = Counter(words_list)
wc.generate_from_frequencies(tomato_count)
# 基于彩色图像生成相应彩色
image_colors = ImageColorGenerator(back_color)
# 绘制词云
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
04 票房预估
最后我们来大胆预估下《西虹市首富》的票房,我们日常在工作中会选取标杆来对一些即将发生的事情进行预估。这次我们选择的标杆就是《羞羞的铁拳》:

基于以下几点我们选择《羞羞的铁拳》作为标杆:
均是开心麻花出品、题材相似
演员阵容重合度高
豆瓣粉丝认可程度相似(评分均为6.9,处于喜剧片中位数水平)
猫眼粉丝认可程度相似(铁拳评分9.1,西红柿评分9.3)
我们看一下两部影片前三天的走势:
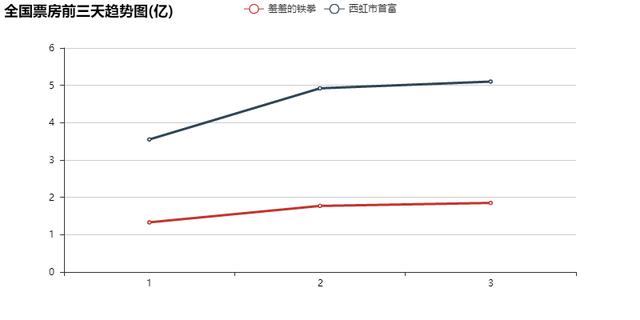
前三天两部片子的票房走势十分相似,基于之前我们的平均,我们可以尝试性(比随机准一点)预测一下“西红柿”最终的票房。“西红柿”票房预测值≈“铁拳”总票房/“铁拳”前三天票房*“西红柿”前三天票房=22.13/5.25*8.62≈36,考虑到铁拳上映是在国庆假期,西红柿的票房预估需要相应的下调。