接口有误,下发了过百万数据,结果app崩溃了。无论如何,客户端都不应该保存和处理这么多数据。Android的SQLite虽然只是一款轻型的数据库,但数据库大小支持2TB,百万数据理论上是无问题的。业务上已经避免过多数据,但崩溃的原因是什么呢?是greenDAO的问题还是使用SQLite的姿势不对?下面写个小程序测试一下。
private Runnable runnable = new Runnable() {
@Override
public void run() {
List bookList = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
Book book = new Book();
book.setUuid(UUID.randomUUID().toString());
book.setName("name");
//其他set方法略
bookList.add(book);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
mBookDao.insertOrReplaceInTx(bookList);
Log.d(TAG, "插入book数据:" + bookList.size());
}
};
private void insert() {
Log.d(TAG, "线程池开始");
mBookDao.deleteAll();
long time = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 200; i++) {
executorService.submit(runnable);
}
executorService.shutdown();
for (; ; ) {
if (executorService.isTerminated()) {
break;
}
try {
executorService.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Log.d(TAG, "线程池完成:" + (System.currentTimeMillis() - time) + "ms");
}
runnable任务模拟1秒从网络拉取5000条数据并插入DB,insert方法使用线程池执行runnable任务。
执行时间超过1000秒,查看内存占用超过180M。如果数据量更多,肯定会发生OOM,基本上可以定位是greenDAO的问题。现在需要在两个方面优化,一是寻找内存占用的原因,二是提高数据的插入速度。
查看内存堆
内存的占用随着insert的数据量越多而递增,从中间dump出java堆,得到hprof文件。注意这个文件不是标准格式,只能用AndroidStudio打开。
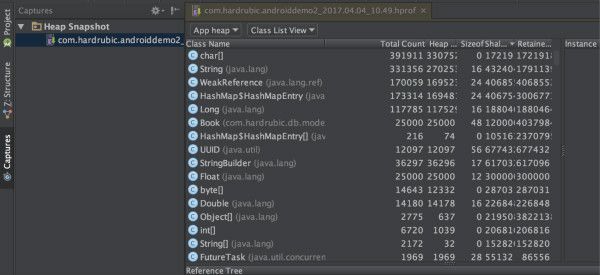
右击文件导出标准的hprof文件,用更加强大的MAT分析。
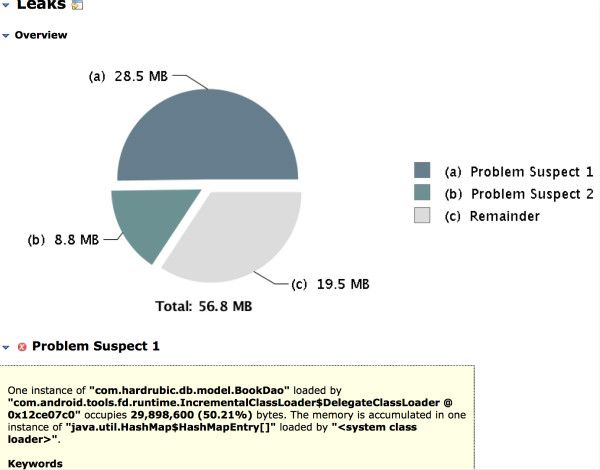
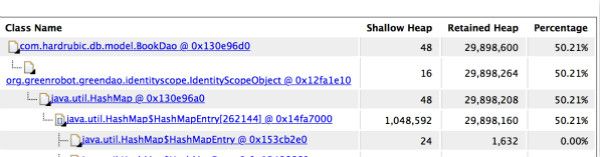
看到IdentityScope占了一半内存,可以确定是greenDAO缓存了插入数据。
mBookDao.insertOrReplaceInTx(bookList);
mBookDao.detachAll();
greenDAO的缓存功能是有用的,没必要关闭,改成在插入数据后,调用一次detachAll,将identityScope清空。
public void detachAll() {
if (identityScope != null) {
identityScope.clear();
}
}
重建索引
对表插入大量数据,如果中间没有涉及到业务,可以先失效索引,待插入完成后重建索引。
String sql = "drop index index_isbn";
mDb.execSQL(sql);
sql = "drop index index_publisherid";
mDb.execSQL(sql);
sql = "drop index index_author";
mDb.execSQL(sql);
插入数据前,drop掉表中的索引。没有见到greenDAO有操作索引的方法,直接执行sql命令。
sql = "create index index_isbn on book(isbn)";
mDb.execSQL(sql);
sql = "create index index_publisherid on book(publisherid)";
mDb.execSQL(sql);
sql = "create index index_author on book(author)";
mDb.execSQL(sql);
插入数据完成后,重建索引。最后执行100w数据插入大约耗时450秒,比什么都不做快了两三倍。
异步操作
上一个步骤的耗时包含了模拟网络和数据库操作的时间,使用多线程将两个环节分离,可以减少总时间。
greenDAO提供了AsyncSession这个异步操作类,使用daoSession.startAsyncSession()获取实例,内部实现使用了线程池和阻塞队列,原理很简单不用多讲。
mAsyncSession.runInTx(new Runnable() {
@Override
public void run() {
mBookDao.insertOrReplaceInTx(bookList);
mBookDao.deleteAll();
}
});
获取数据后,提交给AsyncSession异步插入数据库。要注意在合适地方使用waitForCompletion,等待AsyncSession完成已有任务。如果获取数据速度很快,而操作数据库很慢,会导致过多数据缓存在AsyncSession的内部阻塞队列。
最后测试一下100w数据插入数据库,耗时不到150秒,又快了几倍。
能优化的地方暂时想到这么多,求更好的优化方法。