16、CentOS7 安装Docker之扩展(docker集群管理集群之swram)
docker集群管理之swarm
一、前言
实践中会发现,生产环境中使用单个 Docker 节点是远远不够的,搭建 Docker 集群势在必行。然而,面对 Kubernetes, Mesos 以及 Swarm 等众多容器集群系统,我们该如何选择呢?它们之中,Swarm 是 Docker 原生的,同时也是最简单,最易学,最节省资源的,比较适合中小型公司使用。
Docker Swarm 介绍
Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令。目前,Swarm 是 Docker 社区提供的唯一一个原生支持 Docker 集群管理的工具。它可以把多个 Docker 主机组成的系统转换为单一的虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。
Docker Swarm 是一个为 IT 运维团队提供集群和调度能力的编排工具。用户可以把集群中所有 Docker Engine 整合进一个「虚拟 Engine」的资源池,通过执行命令与单一的主 Swarm 进行沟通,而不必分别和每个 Docker Engine 沟通。在灵活的调度策略下,IT 团队可以更好地管理可用的主机资源,保证应用容器的高效运行。
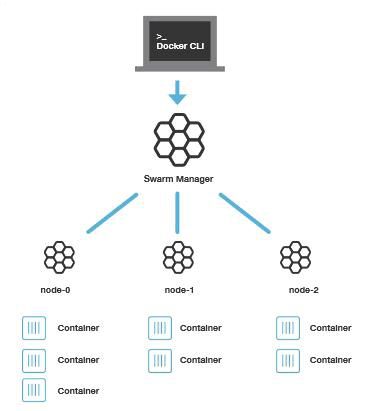
Docker Swarm 优点
任何规模都有高性能表现
对于企业级的 Docker Engine 集群和容器调度而言,可拓展性是关键。任何规模的公司——不论是拥有五个还是上千个服务器——都能在其环境下有效使用 Swarm。 经过测试,Swarm 可拓展性的极限是在 1000 个节点上运行 50000 个部署容器,每个容器的启动时间为亚秒级,同时性能无减损。
灵活的容器调度
Swarm 帮助 IT 运维团队在有限条件下将性能表现和资源利用最优化。Swarm 的内置调度器(scheduler)支持多种过滤器,包括:节点标签,亲和性和多种容器部策略如 binpack、spread、random 等等。
服务的持续可用性
Docker Swarm 由 Swarm Manager 提供高可用性,通过创建多个 Swarm master 节点和制定主 master 节点宕机时的备选策略。如果一个 master 节点宕机,那么一个 slave 节点就会被升格为 master 节点,直到原来的 master 节点恢复正常。 此外,如果某个节点无法加入集群,Swarm 会继续尝试加入,并提供错误警报和日志。在节点出错时,Swarm 现在可以尝试把容器重新调度到正常的节点上去。
和 Docker API 及整合支持的兼容性Swarm 对 Docker API 完全支持,这意味着它能为使用不同 Docker 工具(如 Docker CLI,Compose,Trusted Registry,Hub 和 UCP)的用户提供无缝衔接的使用体验。
Docker Swarm 为 Docker 化应用的核心功能(诸如多主机网络和存储卷管理)提供原生支持。开发的 Compose 文件能(通过 docker-compose up )轻易地部署到测试服务器或 Swarm 集群上。Docker Swarm 还可以从 Docker Trusted Registry 或 Hub 里 pull 并 run 镜像。
综上所述,Docker Swarm 提供了一套高可用 Docker 集群管理的解决方案,完全支持标准的 Docker API,方便管理调度集群 Docker 容器,合理充分利用集群主机资源。
* 并非所有服务都应该部署在Swarm集群内。数据库以及其它有状态服务就不适合部署在Swarm集群内。*
相关概念
节点
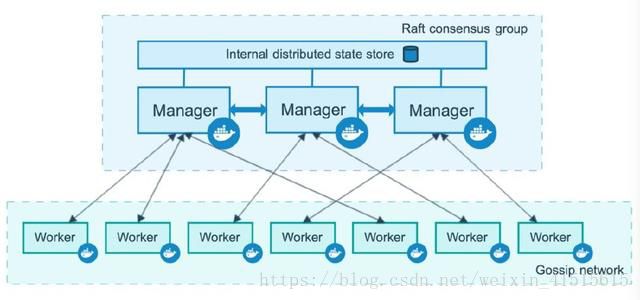
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node) 。节点分为管理 (manager) 节点和工作 (worker) 节点。
管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。你也可以通过配置让服务只运行在管理节点。下图展示了集群中管理节点与工作节点的关系。
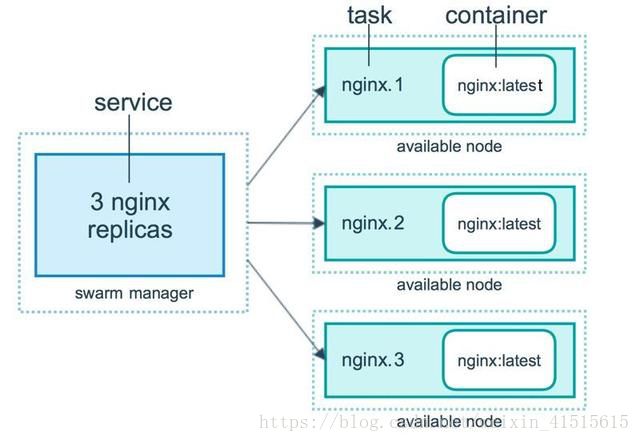
服务和任务
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。 服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
replicated services 按照一定规则在各个工作节点上运行指定个数的任务。global services 每个工作节点上运行一个任务两种模式通过 docker service create 的 --mode 参数指定。下图展示了容器、任务、服务的关系。
创建 Swarm 集群
我们知道 Swarm 集群由管理节点和工作节点组成。我们来创建一个包含一个管理节点和两个工作节点的最小 Swarm 集群。
二、准备环境(CentOS 7下使用 yum 安装):
| 主机名称 |
IP地址 |
操作系统 |
软件 |
| linux-node1.server.com |
192.168.10.101 |
CentOS7.2 |
Docker |
| linux-node2.server.com |
192.168.10.102 |
CentOS7.2 |
Docker |
| linux-node3.server.com |
192.168.10.103 |
CentOS7.2 |
Docker |
将主机名为linux-node1.server.com的机器作为manager节点,也就是管理节点,而linux-node2.server.com和linux-node3.server.com作为工作节点。
Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
1、关闭防火墙\关闭SeLinux\设置时间同步(在node1、node2、node3上操作):
systemctl stop firewalld.service && systemctl disable firewalld.service
sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
setenforce 0
yum -y install wget net-tools ntp ntpdate lrzsz
systemctl restart ntpdate.service ntpd.service && systemctl enable ntpd.service ntpdate.service
2、配置主机映射/etc/hosts(在node1、node2、node3上操作):
echo 192.168.10.101 linux-node1.server.com >> /etc/hosts
echo 192.168.10.102 linux-node2.server.com >> /etc/hosts
echo 192.168.10.103 linux-node3.server.com >> /etc/hosts
hostnamectl --static set-hostname linux-node1.server.com
bash
3、安装 Docker(在node1、node2、node3上操作):
Docker 软件包和依赖包已经包含在默认的 CentOS-Extras 软件源里,安装命令如下:
yum -y install docker-io
yum list installed | grep docker
docker.x86_64 2:1.13.1-68.gitdded712.el7.centos @extras
docker-client.x86_64 2:1.13.1-68.gitdded712.el7.centos @extras
docker-common.x86_64 2:1.13.1-68.gitdded712.el7.centos @extras
4.镜像加速(在node1、node2、node3上操作):
鉴于国内网络问题,后续拉取 Docker 镜像十分缓慢,我们可以需要配置加速器来解决,我使用的是阿里的镜像地址:
在/etc/docker/daemon.json文件中添加如下内容.
{
"registry-mirrors": ["https://wghlmi3i.mirror.aliyuncs.com"]
}
或者使用如下地址
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
5、启动 Docker 后台服务(在node1、node2、node3上操作):
systemctl start docker.service
到此,docker 在 CentOS 系统的安装完成。
三、创建swarm集群:
1、初始化集群(在node1上操作):
[root@linux-node1 ~]# docker swarm init --advertise-addr 192.168.10.101
Swarm initialized: current node (xxkq6mhnilt0lulmhwrwrtfrr) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-1m7l3vepkees60zh321bssfdlqo36vjvoy5b1mlm0mcypcq13e-58azd8nskaixhbxjh1mvcx8jt \
192.168.10.101:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
2、查看集群状态(在node1上操作):
[root@linux-node1 ~]# docker info | grep -i swarm
Swarm: active #激活状态
3、查看端口状态(在node1上操作):
[root@linux-node1 ~]# netstat -tunlp | grep docker (默认监听两个端口,tcp2377端口为集群的管理端口,tcp7946为节点之间的通讯端口)
tcp6 0 0 :::2377 :::* LISTEN 3979/dockerd-curren
tcp6 0 0 :::7946 :::* LISTEN 3979/dockerd-curren
4、查看默认创建网络(在node1上操作):
(默认会创建一个overlay的网络ingress,还会创建一个桥接的网络docker_gwbridge)
[root@linux-node1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
c3f9bacc7a27 bridge bridge local
169aedb818b9 docker_gwbridge bridge local
6488efd3fa8a host host local
squcqnplf4gz ingress overlay swarm
b044056e55bd none null local
5、查看集群节点(在node1上操作):
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Active Leader
6、查看swarm配置文件(在node1上操作):
[root@linux-node1 ~]# ll /var/lib/docker/swarm/
drwxr-xr-x 2 root root 72 Sep 27 09:14 certificates (使用的tls来进行安全通信)
-rw------- 1 root root 112 Sep 27 09:14 docker-state.json(用来记录通信的地址和端口,也会记录本地的地址和端口)
drwx------ 4 root root 53 Sep 27 09:14 raft(raft协议)
-rw------- 1 root root 70 Sep 27 09:14 state.json (manager的ip和端口)
drwxr-xr-x 2 root root 21 Sep 27 09:14 worker (记录工作节点下发的任务信息)
- 将其他节点接入swarm集群(在node2、node3上操作):
[root@linux-node2 ~]# docker swarm join --token SWMTKN-1-1m7l3vepkees60zh321bssfdlqo36vjvoy5b1mlm0mcypcq13e-58azd8nskaixhbxjh1mvcx8jt 192.168.10.101:2377
[root@linux-node3 ~]# docker swarm join --token SWMTKN-1-1m7l3vepkees60zh321bssfdlqo36vjvoy5b1mlm0mcypcq13e-58azd8nskaixhbxjh1mvcx8jt 192.168.10.101:2377
注:当忘记了加入集群的token的时候,可以使用如下的指令找到token,然后在node节点上直接执行,就可以加入worker节点或者是manager节点。
[root@linux-node1 ~]# docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-1m7l3vepkees60zh321bssfdlqo36vjvoy5b1mlm0mcypcq13e-58azd8nskaixhbxjh1mvcx8jt \
192.168.10.101:2377
8、查看集群状态(在node1上操作):
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Ready Active
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Active Leader
9、节点之间的角色可以随时进行切换,使用update(在node1上操作):
[root@linux-node1 ~]# docker node update --role manager linux-node3.server.com
linux-node3.server.com
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Ready Active Reachable
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Active Leader
[root@linux-node1 ~]# docker node update --role worker linux-node3.server.com
linux-node3.server.com
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Ready Active
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Active Leader
四、运行服务(都是在node1上操作):
1、服务为service,也就是一组task的集合,而一个task则表示为一个容器,从基本概念来说,运行一个service,可能有几个task,例如运行几个nginx的服务,从而会拆解为几个nginx的容器在各个节点上进行运行。
[root@linux-node1 ~]# docker service create --name web nginx
sn3lxly6d272l0fgxk7gkuebq
2、创建一个名称问frontweb的服务,模式为global,镜像为nginx:
[root@linux-node1 ~]# docker service create --name web2 --mode global nginx
z4rkquh3byqglxw4wa0p6j9vt
3、查看运行的服务:
[root@linux-node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE
sn3lxly6d272 web replicated 1/1 nginx:latest
z4rkquh3byqg web2 global 3/3 nginx:latest
4、查看运行服务的详细信息,默认情况下manager也可以运行服务:
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running
[root@linux-node1 ~]# docker service ps web2
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
j1crkmli5pr0 web2.xxkq6mhnilt0lulmhwrwrtfrr nginx:latest linux-node1.server.com Running Running about a minute ago
lkxl8b4njuc2 web2.uzvohbfv7ta440px57b4o7bn6 nginx:latest linux-node3.server.com Running Running about a minute ago
qy96s6g9gpq0 web2.ibrkg91oq7ezcqtr9b25e2ook nginx:latest linux-node2.server.com Running Running 3 minutes ago
说明:在创建服务的时候,会经过几个状态,一个是prepared,表示准备,主要是从仓库拉取镜像,然后启动容器,也就是starting,最后会进行验证容器状态,从而最后变成running状态。
在查看服务的时候,会出现一个mode,也就是服务的类型,可以分为两种,一种replicated,表示副本,默认情况下是使用replicated模式,并且默认情况只会创建一个副本,主要使用的目的是为了高可用;另外一种为global,也就是必须在每个机器上运行一个task也就是容器,可以看到在使用global的模式的时候创建了三个容器。
[root@linux-node1 ~]# docker service inspect web2 --pretty
ID: z4rkquh3byqglxw4wa0p6j9vt
Name: web2
Service Mode: Global
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Max failure ratio: 0
ContainerSpec:
Image: nginx:latest@sha256:e8ab8d42e0c34c104ac60b43ba60b19af08e19a0e6d50396bdfd4cef0347ba83
Resources:
Endpoint Mode: vip
五、服务扩容:
在使用服务的时候,由于是集群,那么就必然会涉及到高可用,从而会有服务的扩容和缩容,在swarm中还是很容易的。
1、将扩容web服务为4个(在node1上操作):
[root@linux-node1 ~]# docker service scale web=4
web scaled to 4
2、查看服务(在node1上操作):
[root@linux-node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE
sn3lxly6d272 web replicated 4/4 nginx:latest
z4rkquh3byqg web2 global 3/3 nginx:latest
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 14 minutes ago
3y0qu5gdbvy7 web.2 nginx:latest linux-node1.server.com Running Running about a minute ago
l30ado91q5ue web.3 nginx:latest linux-node3.server.com Running Running about a minute ago
o14b8xwy4tx0 web.4 nginx:latest linux-node3.server.com Running Running about a minute ago
3、服务缩容(在node1上操作):
[root@linux-node1 ~]# docker service scale web=2
web scaled to 2
4、查看服务(在node1上操作):
[root@linux-node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE
sn3lxly6d272 web replicated 2/2 nginx:latest
z4rkquh3byqg web2 global 3/3 nginx:latest
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 17 minutes ago
3y0qu5gdbvy7 web.2 nginx:latest linux-node1.server.com Running Running 4 minutes ago
Manager不运行容器:
注意:当要让swarm的manager节点不运行容器的时候,只要更改节点的状态,从Active变成Drain即可,如果在manager上运行容器,那么当manager宕机的时候,如果不是多节点的manager,会导致此服务无法进行调度。
5、将manager节点的状态修改为drain状态,从而不会执行相关的task任务(在node1上操作):
[root@linux-node1 ~]# docker node update --availability drain linux-node1.server.com
linux-node1.server.com
6、查看节点的状态从active变成drain(在node1上操作):
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Ready Active
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Drain Leader
7、本来运行在docker-ce上的容器会被关闭,然后自动迁移到其他的worker节点上(在node1上操作):
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 24 minutes ago
rnde0zdcpnyl web.2 nginx:latest linux-node3.server.com Running Running about a minute ago
3y0qu5gdbvy7 \_ web.2 nginx:latest linux-node1.server.com Shutdown Shutdown about a minute ago
六、故障自动转移:
在集群中,当有机器发生宕机了咋办,swarm可以做到自动迁移,但是在生产环境中需要考虑的一个问题就是,如果出现了自动的failover,那么其他的机器是否有足够的资源来创建这些容器,所以,在进行运行容器的时候,就要考虑剩余资源的问题,例如cpu和内存。
1、查看服务(在node1上操作):
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 35 minutes ago
shlloll6mog5 web.2 nginx:latest linux-node3.server.com Running Running 2 seconds ago
[root@linux-node1 ~]#
2、关闭node3的docker服务,模拟机器宕机(在node3上操作):
[root@linux-node3 ~]# systemctl stop docker.service
3、查看node信息,发现dockernode3主机标记为down(在node1上操作):
[root@linux-node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Down Active
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Drain Leader
4、查看自动迁移后的服务,会将宕机的服务全部标记为shutdown关闭(在node1上操作):
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 40 minutes ago
zvfgn8bi2mf6 web.2 nginx:latest linux-node2.server.com Running Running 2 minutes ago
shlloll6mog5 \_ web.2 nginx:latest linux-node3.server.com Shutdown Running 2 minutes ago
5、将node3的docker服务上线(在node3上操作):
[root@linux-node3 ~]# systemctl start docker.service
6、查看服务(在node1上操作):
[root@linux-node1 ~]# docker node ls #主机状态变成ready,表示可运行task任务
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
ibrkg91oq7ezcqtr9b25e2ook linux-node2.server.com Ready Active
uzvohbfv7ta440px57b4o7bn6 linux-node3.server.com Ready Active
xxkq6mhnilt0lulmhwrwrtfrr * linux-node1.server.com Ready Drain Leader
7、再次查看服务的分布,服务不会再次进行迁移到不同的机器上,维持原状(在node1上操作):
[root@linux-node1 ~]# docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
gxm5271mckck web.1 nginx:latest linux-node2.server.com Running Running 45 minutes ago
zvfgn8bi2mf6 web.2 nginx:latest linux-node2.server.com Running Running 7 minutes ago
shlloll6mog5 \_ web.2 nginx:latest linux-node3.server.com Shutdown Failed 4 minutes ago "No such container: web.2.shll…"
七、访问服务:
访问服务的时候,主要分为两种,一种是内部访问的服务,也就是不对外开放端口,一种是对外的服务,会向外开放端口,也就是主机映射端口。
1、创建两个副本的http服务(在node1上操作):
[root@linux-node1 ~]# docker service create --name web3 --replicas=2 httpd
hzfom5zyswu5lds4bfi8g3kdo
2、查看运行容器的主机(在node1上操作):
[root@linux-node1 ~]# docker service ps web3
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mtkxm1sy5pc1 web3.1 httpd:latest linux-node2.server.com Running Preparing 28 seconds ago
0rvvrjep52wf web3.2 httpd:latest linux-node3.server.com Running Preparing 28 seconds ago
[root@linux-node1 ~]#
3、登录本地主机,查看运行的容器(在node1上操作):
[root@linux-node1 ~]# docker pull httpd
[root@linux-node1 ~]# docker run -d httpd
[root@linux-node1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
99ad19a1c221 httpd "httpd-foreground" 16 seconds ago Up 15 seconds 80/tcp hardcore_poitras
4、查看运行容器的ip地址(在node1上操作):
[root@linux-node1 ~]# docker exec 99ad19a1c221 ip addr show
1: lo:
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
11: eth0@if12:
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
5、根据ip地址访问,只能在本节点上进行访问,属于内部网络,也就是docker_gwbrige网络(在node1上操作):
[root@linux-node1 ~]# curl 172.17.0.2
It works!
6、添加主机映射端口,从而将服务对外放开,从而外部能访问此服务(在node1上操作):
[root@linux-node1 ~]# docker service update --publish-add 8888:80 web3
web3
7、添加外部能访问后,将原来的容器关闭,重新运行容器(在node1上操作):
[root@linux-node1 ~]# docker service ps web3
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xsa9jv3zz01h web3.1 httpd:latest linux-node2.server.com Running Running 24 seconds ago
mtkxm1sy5pc1 \_ web3.1 httpd:latest linux-node2.server.com Shutdown Shutdown 25 seconds ago
n4rforlcng54 web3.2 httpd:latest linux-node3.server.com Running Running 26 seconds ago
0rvvrjep52wf \_ web3.2 httpd:latest linux-node3.server.com Shutdown Shutdown 27 seconds ago
8、无论是manager节点还是worker节点,均监听了8000端口,均可以访问(在node1、node2、node3上操作):
netstat -tunlp | grep 8888
tcp6 0 0 :::8888 :::* LISTEN 2664/dockerd-curren
[root@linux-node1 ~]# curl 192.168.10.101:8888
It works!
[root@linux-node1 ~]# curl 192.168.10.102:8888
It works!
[root@linux-node1 ~]# curl 192.168.10.103:8888
It works!
说明:在这里主要使用了routing mesh的功能,在swarm内部实现了负载均衡,使用的网络为swarm自动创建的overlay网络。 当使用publish端口的时候,最大的坏处就是对外暴露了端口号,而且在使用的时候,如果进行了故障转移,那么多个服务运行在同一个主机上面,会造成端口占用冲突。
八、服务发现:
在使用集群的时候,如果进行了自动转移,那么ip地址会发生变化,如果指定了ip地址,那么就会影响其他服务的使用,从而需要服务发现的功能,也就是自动将服务进行dns的解析,然后负载到正确的服务中。
1、创建overlay网络,默认的ingress网络未实现服务发现的功能(在node1上操作):
[root@linux-node1 ~]# docker network create --driver overlay yanyb
wkm7had2ydek5wqwg1z04fiv4
2、将服务挂载到自创建的overlay网络中,从而能实现名称解析(在node1上操作):
[root@linux-node1 ~]# docker service create --name web4 --replicas=2 --network=yanyb nginx
rmeba7o211nrufg0rtk6aulh9
3、创建另外一个服务依赖于其他的服务(在node1上操作):
[root@linux-node1 ~]# docker service create --name ds --network=yanyb busybox sleep 100000
95zb5u8ib5e7nolqd3yx5cifz
4、查看运行的服务(在node2、node3上操作):
[root@linux-node2 ~]# docker ps -ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
d682c87e33ba busybox@sha256:cb63aa0641a885f54de20f61d152187419e8f6b159ed11a251a09d115fdff9bd "sleep 100000" 10 minutes ago Up 10 minutes ds.1.194dwa65fv5f2hwms6drc8bos 0 B (virtual 1.16 MB)
5、自动实现了dns的解析功能(在node2上操作):
[root@linux-node2 ~]# docker exec d682c87e33ba ping -c 2 web4
PING web4 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: seq=0 ttl=64 time=0.087 ms
64 bytes from 10.0.0.2: seq=1 ttl=64 time=0.122 msID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
194dwa65fv5f ds.1 busybox:latest linux-node2.server.com Running Running about a minute ago
九、滚动更新rolling update:
当需要进行更新的时候,swarm可以设定相应的策略来进行更新,例如并行更新多少个容器,更新之间的间隔时间等。
1、更新web的镜像(在node1上操作):
[root@linux-node1 ~]# docker service update --image nginx:1.14 web4
web4
2、更新的时候先关闭,然后再更新(在node1上操作):
[root@linux-node1 ~]# docker service ps web4
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
x9jxni508n0a web4.1 nginx:1.14 linux-node2.server.com Running Running 44 seconds ago
jkakusu4cng6 \_ web4.1 nginx:latest linux-node2.server.com Shutdown Shutdown about a minute ago
e828m6j14a2p web4.2 nginx:1.14 linux-node3.server.com Running Running about a minute ago
d858v1gk91t6 \_ web4.2 nginx:latest linux-node3.server.com Shutdown Shutdown about a minute ago
[root@linux-node1 ~]#
3、再次更新(在node1上操作):
[root@linux-node1 ~]# docker service ps web4
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ufh3w4j5v1py web4.1 nginx:1.15 linux-node2.server.com Running Running 11 seconds ago
x9jxni508n0a \_ web4.1 nginx:1.14 linux-node2.server.com Shutdown Shutdown 12 seconds ago
jkakusu4cng6 \_ web4.1 nginx:latest linux-node2.server.com Shutdown Shutdown 2 minutes ago
4vz1kqtmvndu web4.2 nginx:1.15 linux-node3.server.com Running Running 13 seconds ago
e828m6j14a2p \_ web4.2 nginx:1.14 linux-node3.server.com Shutdown Shutdown 14 seconds ago
d858v1gk91t6 \_ web4.2 nginx:latest linux-node3.server.com Shutdown Shutdown 3 minutes ago
4、设定更新的并发数和更新的间隔时间(在node1上操作):
[root@linux-node1 ~]# docker service update --update-parallelism 2 --update-delay 1m web4
web4
5、查看具体的信息,可以看到更新的一些参数配置(在node1上操作):
[root@linux-node1 ~]# docker service inspect web4 --pretty
ID: rmeba7o211nrufg0rtk6aulh9
Name: web4
Service Mode: Replicated
Replicas: 2
Placement:
UpdateConfig:
Parallelism: 2
Delay: 1m0s
On failure: pause
Max failure ratio: 0
ContainerSpec:
Image: nginx:1.15@sha256:e8ab8d42e0c34c104ac60b43ba60b19af08e19a0e6d50396bdfd4cef0347ba83
Resources:
Networks: yanyb
Endpoint Mode: vip
十、label控制service运行的节点:
主要是用来控制每个task运行的节点,从而可以为每个节点设置属性label,然后根据label来指定task运行的位置(生产环境中可能要手动将容器分布在不同的机器上,从而达到高可用的目的)。
1、更新节点的属性,为节点添加标签(在node1上操作):
[root@linux-node1 ~]# docker node update --label-add ncname=linux-node2.server.com linux-node2.server.com
linux-node2.server.com
[root@linux-node1 ~]# docker node update --label-add ncname=linux-node3.server.com linux-node3.server.com
linux-node3.server.com
2、查看设置的属性(在node1上操作):
[root@linux-node1 ~]# docker node inspect linux-node2.server.com --pretty
ID: ibrkg91oq7ezcqtr9b25e2ook
Labels:
- ncname = linux-node2.server.com
Hostname: linux-node2.server.com
Joined at: 2018-09-27 13:36:15.218186671 +0000 utc
Status:
State: Ready
Availability: Active
Address: 192.168.10.102
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 977.9 MiB
Plugins:
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 1.13.1
3、指定机器来运行相关的任务,主要是根据label的值
[root@linux-node1 ~]# docker service create --name web-yanyb --constraint node.labels.ncname==linux-node2.server.com --replicas 2 nginx
q9rejm7v9qnoed4972omitnrd
4、查看运行的容器是否是是我指定的机器上:
[root@linux-node1 ~]# docker service ps web-yanyb
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xm3x1fcsc9e3 web-yanyb.1 nginx:latest linux-node2.server.com Running Running about a minute ago
l0epeh9iuph1 web-yanyb.2 nginx:latest linux-node2.server.com Running Running about a minute ago
5、去掉指定标签:
[root@linux-node1 ~]# docker service update --constraint-rm node.labels.ncname==linux-node2.server.com web-yanyb
web-yanyb
- 将容器迁移到node3主机上:
[root@linux-node1 ~]# docker service update --constraint-add node.labels.ncname==linux-node3.server.com web-yanyb
web-yanyb
- 验证是否迁移成功:
[root@linux-node1 ~]# docker service ps web-yanyb
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
aw00bhqtsvrx web-yanyb.1 nginx:latest linux-node3.server.com Running Running 20 seconds ago
584m1xdhdwaq \_ web-yanyb.1 nginx:latest linux-node3.server.com Shutdown Shutdown 20 seconds ago
xm3x1fcsc9e3 \_ web-yanyb.1 nginx:latest linux-node2.server.com Shutdown Shutdown 2 minutes ago
xdtyqfafn03p web-yanyb.2 nginx:latest linux-node3.server.com Running Running 18 seconds ago
bebj07o7by4p \_ web-yanyb.2 nginx:latest linux-node2.server.com Shutdown Shutdown 19 seconds ago
l0epeh9iuph1 \_ web-yanyb.2 nginx:latest linux-node2.server.com Shutdown Shutdown 2 minutes ago
十一、健康检查:
如何来进行业务层面的健康检查呢,容器的状态是不可以的。在运行服务的时候,也是可以设定相关参数的,具体的参数如下:
--interval=DURATION (default: 30s)
--timeout=DURATION (default: 30s)
--start-period=DURATION (default: 0s)
--retries=N (default: 3)
1、查看容器状态:
[root@linux-node1 ~]# docker service ps web-yanyb
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
aw00bhqtsvrx web-yanyb.1 nginx:latest linux-node3.server.com Running Running 27 minutes ago
584m1xdhdwaq \_ web-yanyb.1 nginx:latest linux-node3.server.com Shutdown Shutdown 27 minutes ago
xm3x1fcsc9e3 \_ web-yanyb.1 nginx:latest linux-node2.server.com Shutdown Shutdown 29 minutes ago
xdtyqfafn03p web-yanyb.2 nginx:latest linux-node3.server.com Running Running 27 minutes ago
bebj07o7by4p \_ web-yanyb.2 nginx:latest linux-node2.server.com Shutdown Shutdown 27 minutes ago
l0epeh9iuph1 \_ web-yanyb.2 nginx:latest linux-node2.server.com Shutdown Shutdown 29 minutes ago
2、查看健康检查的相关日志:
[root@linux-node1 ~]# docker inspect q9rejm7v9qno
[
{
"ID": "q9rejm7v9qnoed4972omitnrd",
"Version": {
"Index": 294
},
"CreatedAt": "2018-09-28T14:29:32.445708731Z",
"UpdatedAt": "2018-09-28T14:35:09.842423763Z",
"Spec": {
"Name": "web-yanyb",
"TaskTemplate": {
"ContainerSpec": {
"Image": "nginx:latest@sha256:e8ab8d42e0c34c104ac60b43ba60b19af08e19a0e6d50396bdfd4cef0347ba83",
"DNSConfig": {}
},
"Resources": {
"Limits": {},
"Reservations": {}
},
"RestartPolicy": {
"Condition": "any",
"MaxAttempts": 0
},
"Placement": {
"Constraints": [
"node.labels.ncname==linux-node3.server.com"
]
},
"ForceUpdate": 0
},
"Mode": {
"Replicated": {
"Replicas": 2
}
},
"UpdateConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"MaxFailureRatio": 0
},
"EndpointSpec": {
"Mode": "vip"
}
},
"PreviousSpec": {
"Name": "web-yanyb",
"TaskTemplate": {
"ContainerSpec": {
"Image": "nginx:latest@sha256:e8ab8d42e0c34c104ac60b43ba60b19af08e19a0e6d50396bdfd4cef0347ba83",
"DNSConfig": {}
},
"Resources": {
"Limits": {},
"Reservations": {}
},
"RestartPolicy": {
"Condition": "any",
"MaxAttempts": 0
},
"Placement": {},
"ForceUpdate": 0
},
"Mode": {
"Replicated": {
"Replicas": 2
}
},
"UpdateConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"MaxFailureRatio": 0
},
"EndpointSpec": {
"Mode": "vip"
}
},
"Endpoint": {
"Spec": {}
},
"UpdateStatus": {
"State": "completed",
"StartedAt": "2018-09-28T14:34:36.332799006Z",
"CompletedAt": "2018-09-28T14:35:09.842405942Z",
"Message": "update completed"
}
}
]