牛客网SQL刷题问题汇总
目录
1.选取字段为【奇数或偶数问题】
2.【排序问题】
3.MySQL【新建表、修改表】
4.对于表批量【插入数据】,如果数据已经存在,则忽略
5.新建一个表,表中字段内容从另一个表导入
6.【索引】含义、原理、添加索引
强制索引:
7.MySQL【视图View】
8.MySQL【触发器】
9.修改表名
10.用【replace】替换个别数据
11.【DELETE】删除数据
12.创建外键约束
13.取两个表的交集【intersect】(SQL支持,MySQL不支持)
14.获取数据库中所有表名称
15.MySQL字符串截取总结【left, right, substring, substring_index】
16.连接字符串【concat(), group_concat()】
17. where后面不能跟分组函数avg, min, max, count, sum
18. mysql【分页查询】
19.mysql中的 【exists 与 in 】
20. 排列累加问题【sum() over()】
21. 选取表的奇数行、偶数行数据
1.选取字段为【奇数或偶数问题】
mysql判断奇数偶数,并思考效率 https://blog.csdn.net/zhazhagu/article/details/80452473
mysql是可以用mod的,但牛客网的SQLite(应该是)不能用mod函数,只可以用 `字段名`%2 =0或1 进行判断
2.【排序问题】
MySQL实现排名函数RANK,DENSE_RANK和
ROW_NUMBER https://blog.csdn.net/u011726005/article/details/94592866
有三种排序方式,各有两种实现方法:1.变量法 2.函数法
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
emp_no salary rank 10005 94692 1 10009 94409 2 10010 94409 2 10001 88958 3 10007 88070 4 10004 74057 5 10002 72527 6 10003 43311 7 10006 43311 7 10011 25828 8
变量法:如果面试的话,这么写会加分的:
用了两个变量,变量使用时其前面需要加@,这里的:= 是赋值的意思,如果前面有Set关键字,则可以直接用=号来赋值,如果没有,则必须要使用:=来赋值,两个变量rank和pre,其中rank表示当前的排名,pre表示之前的工资,下面代码中的<>表示不等于,如果左右两边不相等,则返回true或1,若相等,则返回false或0。初始化rank为0,pre为-1,然后按降序排列工资,对于工资4来说,pre赋为4,和之前的pre值-1不同,所以rank要加1,那么工资4的rank就为1,下面一个分工资还是4,那么pre赋值为4和之前的4相同,所以rank要加0,所以这个工资4的rank也是1,以此类推就可以计算出所有工资的rank了
---牛客网别人的答案
SELECT emp_no,salary,(@`rank`:= @`rank`+ (@`pre`!= (@`pre`:= salary))) `Rank`
FROM salaries, (SELECT @`rank`:= 0, @`pre`:= -1) INIT
WHERE to_date = '9999-01-01'
group by emp_no
order by salary desc
---或者用CASE WHEN (mysql里要给变量加上反引号)
select emp_no, salary,
(case
when @pres=salary then @`rank`
when @pres:=salary then @`rank`:=@`rank`+1
end) `Rank`
from salaries, (select @`rank`:=0,@pres:=-1) init
where to_date = '9999-01-01'
order by salary desc
---或者用窗口函数
select emp_no, salary, dense_rank() over(order by salary desc) as rank
from salaries
where to_date='9999-01-01'
order by salary desc,emp_no asc
3.MySQL【新建表、修改表】
MYSQL添加、更新、删除数据 https://blog.csdn.net/qq_36734216/article/details/78611439
alter table的适用场景(添加、删除列等) https://www.cnblogs.com/lwcode6/p/11326666.html
alter/update 和 delete/drop的区别 https://www.cnblogs.com/lamian/p/3972562.html
在MySQL里,default CURRENT_TIMESTAMP,但在SQLite里面用的是 datetime('now','localtime')
---MySQL中创建表
CREATE TABLE `table1` (
`id` int(11) NOT NULL,
`createtime` timestamp NULL default CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
---SQLite中创建表
create table actor(
`actor_id` smallint(5) not null,
`first_name` varchar(45) not null,
`last_name` varchar(45) not null,
`last_update` timestamp not null default(datetime('now','localtime')),
primary key (`actor_id`))alter table用法:
-- 对整型类型的字段设置默认值(可以这么设置)
alter table 表名 alter column `字段名` set default 6;
-- 对时间类型的字段设置默认值(少了datetime/timestamp关键字,会无效)
alter table 表名 MODIFY column `字段名` datetime/timestamp default CURRENT_TIMESTAMP;
-- 错误的设置默认时间值语句
alter table 表名 alter column `字段名` set default CURRENT_TIMESTAMP;
4.对于表批量【插入数据】,如果数据已经存在,则忽略
如果不存在则插入,如果存在则忽略
INSERT IGNORE INTO tablename VALUES(...);
如果不存在则插入,如果存在则替换
INSERT REPLACE INTO tablename VALUES(...);
这里指的存在表示的是unique属性的列值存在的情况下,unique表示键值唯一insert into:插入数据,如果主键重复,则报错
insert repalce:插入替换数据,如果存在主键或unique数据则替换数据
insert ignore:如果存在主键或unique数据,则忽略。
如果是在SQLite中,insert后面要加or,insert or replace, insert or ignore.
5.新建一个表,表中字段内容从另一个表导入
---mysql写法
create table actor_name
select `first_name`, `last_name` from actor
---SQLite写法(多了一个AS)
create table actor_name as
select `first_name`, `last_name` from actor
6.【索引】含义、原理、添加索引
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
MySQL索引原理以及查询优化 https://www.cnblogs.com/bypp/p/7755307.html
MySQL索引语法 https://www.runoob.com/mysql/mysql-index.html
1.普通索引
#创建索引
CREATE INDEX indexName ON mytable(`username`(length));
#修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(`columnName`);
#创建表的时候直接指定
CREATE TABLE mytable(
`ID` INT NOT NULL,
`username` VARCHAR(16) NOT NULL,
INDEX [indexName] (`username`(length))
);
#删除索引
DROP INDEX [indexName] ON mytable;
2.唯一索引
#创建索引
CREATE UNIQUE INDEX indexName ON mytable(`username`(length))
#修改表结构(添加索引)
ALTER table mytable ADD UNIQUE [indexName] (`username`(length));
#创建表的时候直接指定
CREATE TABLE mytable(
`ID` INT NOT NULL,
`username` VARCHAR(16) NOT NULL,
UNIQUE [indexName] (`username`(length))
);
#删除索引
DROP INDEX [indexName] ON mytable;
3.使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (`column_list`):
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (`column_list`):
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (`column_list`):
添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (`column_list`):
该语句指定了索引为 FULLTEXT ,用于全文索引。
以下实例为在表中添加索引。
mysql> ALTER TABLE testalter_tbl ADD INDEX (`c`);
你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引:
mysql> ALTER TABLE testalter_tbl DROP INDEX `c`;
4.使用 ALTER 命令添加和删除主键
主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下:
mysql> ALTER TABLE testalter_tbl MODIFY `i` INT NOT NULL;
mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (`i`);
你也可以使用 ALTER 命令删除主键:
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;
删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。
5.显示索引信息
你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。可以通过添加 \G 来格式化输出信息。
尝试以下实例:
mysql> SHOW INDEX FROM table_name; \G强制索引:
SQLite中,使用 INDEXED BY 语句进行强制索引查询,可参考:
http://www.runoob.com/sqlite/sqlite-indexed-by.html
SELECT * FROM salaries INDEXED BY idx_emp_no WHERE emp_no = 10005http://www.jb51.net/article/49807.htm
MySQL中,使用 FORCE INDEX 语句进行强制索引查询,可参考:
SELECT * FROM salaries FORCE INDEX idx_emp_no WHERE emp_no = 10005
7.MySQL【视图View】
MySQL 视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图并不实际存在于数据库中。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的。
数据库中只存放了视图的定义,并没有存放视图中的数据,这些数据都存放在定义视图查询所引用的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。因此,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
视图可以从原有的表上选取对用户有用的信息,那些对用户没用,或者用户没有权限了解的信息,都可以直接屏蔽掉,作用类似于筛选。这样做既使应用简单化,也保证了系统的安全。
视图(View)是一种虚表,允许用户实现以下几点:
-
用户或用户组查找结构数据的方式更自然或直观。
-
限制数据访问,用户只能看到有限的数据,而不是完整的表。
-
汇总各种表中的数据,用于生成报告。
SQLite 视图是只读的,因此可能无法在视图上执行 DELETE、INSERT 或 UPDATE 语句。但是可以在视图上创建一个触发器,当尝试 DELETE、INSERT 或 UPDATE 视图时触发,需要做的动作在触发器内容中定义。
1.创建视图
CREATE VIEW <视图名> AS
在 tb_students_info 表上创建一个名为 v_students_info 的视图,输入的 SQL 语句和执行结果如下所示
CREATE VIEW v_students_info(s_id,s_name,d_id,s_age,s_sex,s_height,s_date)
AS SELECT `id`,`name`,`dept_id`,`age`,`sex`,`height`,`login_date`
FROM tb_students_info;
2.查看视图
select * from tb_students_info; ---查看视图具体数据
show create view tb_students_info ---查看视图
3.删除视图
drop view tb_students_info
8.MySQL【触发器】
触发器就是当达成一定条件时,执行特定语句,可以用于监测事件的发生。
MySQL触发器更新和插入操作 https://blog.csdn.net/Eastmount/article/details/52344036
9.修改表名
题目是sqlite3,必须要加to
alter table titles_test rename to titles_2017如果是mysql,不用加to
alter table titles_test rename titles_2017
10.用【replace】替换个别数据
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
解法:
方法一:全字段更新替换。由于 REPLACE 的新记录中 id=5,与表中的主键 id=5 冲突,故会替换掉表中 id=5 的记录,否则会插入一条新记录(例如新插入的记录 id = 10)。并且要将所有字段的值写出,否则将置为空。可参考:
http://blog.csdn.net/zhangjg_blog/article/details/23267761
REPLACE INTO titles_test VALUES (5, 10005, 'Senior Engineer', '1986-06-26', '9999-01-01')http://www.cnblogs.com/huangtailang/p/5cfbd242cae2bcc929c81c266d0c875b.html
方法二:运用REPLACE(X,Y,Z)函数。其中X是要处理的字符串,Y是X中将要被替换的字符串,Z是用来替换Y的字符串,最终返回替换后的字符串。以下语句用 UPDATE和REPLACE 配合完成,用REPLACE函数替换后的新值复制给 id=5 的 emp_no。REPLACE的参数为整型时也可通过。可参考:
http://sqlite.org/lang_corefunc.html#replace
UPDATE titles_test SET emp_no = REPLACE(emp_no,10001,10005) WHERE id = 5/** 另外可以利用OJ系统的漏洞,不用 REPLACE 实现 **/
UPDATE titles_test SET emp_no = 10005 WHERE id = 5
11.【DELETE】删除数据
删除emp_no重复的记录,只保留最小的id对应的记录。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
MYSQL:
MySQL的UPDATE或DELETE中子查询不能为同一张表,可将查询结果再次SELECT。
详见https://www.cnblogs.com/cuisi/p/7372333.html
DELETE FROM titles_test
WHERE id NOT IN (
SELECT *
FROM(
SELECT MIN(id)
FROM titles_test
GROUP BY emp_no
) AS a);这在OJ中也可执行。
另外,在MySQL中还有一个坑,需要给子查询添加别名,不然会抛出错误:ERROR 1248 (42000): Every derived table must have its own alias,详见:https://blog.csdn.net/cao478208248/article/details/28122113
SQLite可以直接:
DELETE FROM titles_test WHERE id NOT IN
(SELECT MIN(id) FROM titles_test GROUP BY emp_no)
12.创建外键约束
SQLite中不能使用alter table...add foreign key...references...,对已经创建的表只能drop。。。(毫无意义,表都没有了)
drop table audit;
CREATE TABLE audit
(EMP_no INT NOT NULL,
create_date datetime NOT NULL,
FOREIGN KEY(EMP_no) REFERENCES employees_test(ID));MySQL下,可以直接使用如下语句 修改:
alter table audit
add foreign key(emp_no) references employees_test(id)
13.取两个表的交集【intersect】(SQL支持,MySQL不支持)
存在如下的视图:
create view emp_v as select * from employees where emp_no >10005;
如何获取emp_v和employees有相同的数据?
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
select * from emp_v intersect select * from employees
intersect:求交集
或者普通方法,MYSQL就可以用in来实现两个数据集的交集:
select *
from employees e
where e.emp_no in(
select emp_no
from emp_v)
14.获取数据库中所有表名称
针对库中的所有表生成select count(*)对应的SQL语句
输出格式:
cnts select count(*) from employees; select count(*) from departments; select count(*) from dept_emp; select count(*) from dept_manager; select count(*) from salaries; select count(*) from titles; select count(*) from emp_bonus;
sqlite写法(牛客网通过):
| 1 2 3 |
|
mysql写法(牛客网不通过,但是我在自己的mysql上运行通过):
| 1 2 |
|
15.MySQL字符串截取总结【left, right, substring, substring_index】
参考文章 https://www.cnblogs.com/heyonggang/p/8117754.html
16.连接字符串【concat(), group_concat()】
参考文章 浅析MySQL中concat以及group_concat的使用
一、concat()函数
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。

二、concat_ws()函数
1、功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。

三、group_concat()函数
前言:在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中。(有关group by的知识请戳:浅析SQL中Group By的使用)。
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。

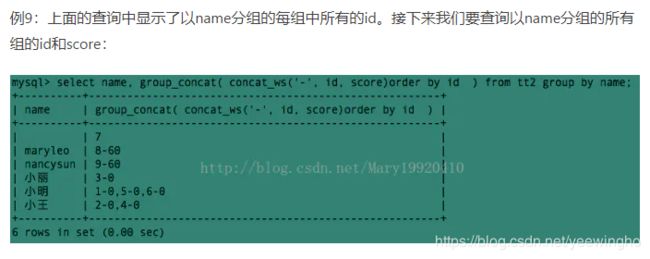
转载 https://blog.csdn.net/Mary19920410/article/details/76545053
按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
输出格式:
dept_no employees d001 10001,10002 d002 10006 d003 10005 d004 10003,10004 d005 10007,10008,10010 d006 10009,10010
解法:
本题要用到SQLite的聚合函数group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与 GROUP BY 配合使用。此题以 dept_no 作为分组,将每个分组中不同的emp_no用逗号连接起来(即可省略Y)。可参考:
http://www.sqlite.org/lang_aggfunc.html#groupconcat http://blog.csdn.net/langzxz/article/details/16807859
| 1 2 |
|
MYSQL的写法:(多一个separator)
select dept_no,group_concat(emp_no SEPARATOR ',') from dept_emp group by dept_no;
17. where后面不能跟分组函数avg, min, max, count, sum
查找排除当前最大、最小salary之后的员工的平均工资avg_salary。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输出格式:
avg_salary 69462.5555555556
错误写法:
select avg(salary) as avg_salary
from salaries
where salary>min(salary) and salary
and to_date='9999-01-01'
错误原因:where 后面不能跟分组函数,因为执行顺序是先执行where 之后才执行分组,还没有分组的时候是无法运行min,max,avg,sum,count这类函数的!
参考文章 为什么sql语句中where后面不能直接跟分组函数?--详解https://blog.csdn.net/liangjiabao5555/article/details/105474876
解决方法:将where后面的分组函数改成子查询!
正确解法:
select avg(salary) as avg_salary
from salaries
where salary>(select min(salary) from salaries) and salary<(SELECT max(salary) from salaries)
and to_date='9999-01-01'
18. mysql【分页查询】
分页查询employees表,每5行一页,返回第2页的数据
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
参考文章 MySQL实现分页查询
语法:select * from table limit (pageNo-1)*pageSize,pageSize;
在数据量较小的时候简单的使用 limit 进行数据分页在性能上面不会有明显的缓慢,但是数据量达到了 万级到百万级 sql语句的性能将会影响数据的返回。这时需要利用主键或者唯一索引进行数据分页;
假设主键或者唯一索引为 good_id
收到客户端{pageNo:5,pagesize:10}
select * from table where good_id > (pageNo-1)*pageSize limit pageSize;
–返回good_id为40到50之间的数据
当需要返回的信息为顺序或者倒序时,对上面的语句基于数据再排序。order by ASC/DESC 顺序或倒序 默认为顺序
select * from table where good_id > (pageNo-1)*pageSize order by good_id limit pageSize;
–返回good_id为40到50之间的数据,数据依据good_id顺序排列
19.mysql中的 【exists 、not exists 与 in 】
使用含有关键字exists查找未分配具体部门的员工的所有信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
思路:在 employees 中挑选出令(SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)不成立的记录
SELECT * FROM employees WHERE NOT EXISTS
(SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)错误写法:
select * from employees
where exists( select emp_no from dept_emp where dept_emp.emp_no != employees.emp_no)那么,Exists都会从外表employees里面逐条比对,如,第一条的emp_no = '10001',那么Exists判断:
select emp_no from dept_emp where dept_emp.emp_no !='10001'因为一定存在dept_emp.emp_no不等于10001的记录。那么上面的查询语句其实也就等效于查询select * from employees
参考文章 浅析MySQL中exists与in的使用 (写的非常好)
另一篇文章教我怎么理解exists和not exists,强烈推介!!exists与not exists的原理讲解
exists筛选结果集为true的数据项,而not exists相反,返回结果集为false的数据项
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select * from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。
相反的
2:
select * from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
20. 排列累加问题【sum() over()】
按照salary的累计和running_total,其中running_total为前两个员工的salary累计和,其他以此类推。 具体结果如下Demo展示。。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输出格式:
emp_no salary running_total 10001 88958 88958 10002 72527 161485 10003 43311 204796 10004 74057 278853 10005 94692 373545 10006 43311 416856 10007 88070 504926 10009 95409 600335 10010 94409 694744 10011 25828 720572
SQLite不能用窗口函数over( ),有一种通用的模板(mysql也可以用):
复用salaries表
select a.emp_no, a.salary, sum(b.salary) as running_total
from salaries a, salaries b
where b.emp_no<=a.emp_no and a.to_date='9999-01-01' and b.to_date='9999-01-01'
group by a.emp_no, a.salary
ORDER BY a.emp_noMySQL里有两种解法:临时变量法和窗口函数
(1)临时变量法
select emp_no, salary, (@`pres`:=@`pres`+salary) running_total
from salaries, (@`pres`:=0) init
where to_date='9999-01-01'
order by emp_no(2)窗口函数 sum() over()
select emp_no, salary, sum(salary) over(order by emp_no asc) as running_total
from salaries
where to_date='9999-01-01'21. 选取表的奇数行、偶数行数据
对于employees表中,给出奇数行的first_name
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
输出格式:
first_name Georgi Chirstian Anneke Tzvetan Saniya Mary
两种方法:普通法和临时变量法
(1)普通法(网友答案):(线下用mysql测试,近50w条数据,查询速度非常慢)
select c.first_name
from
(select a.first_name,
(select count(*)
from employees b
where b.first_name<=a.first_name) rownum
from employees a) c
where c.rownum%2=1
--中间不建临时表的写法
select first_name
from employees e1
where (select count(*) from employees e2 where e2.first_name<=e1.first_name)%2=1思路:首先复用表,先建立新的一列,这一列包含每一行的行数,计算行号的方法 : 有多少个小于等于a.first_name的记录的个数就是a.first_name的行号。例如输入a表第1行进去,此时小于a.first_name的记录数为1;输入a表第二行进去,此时小于a.first_name的记录数共有2个,表示为第2行...下一步是挑选出rownum为奇数的行,即可。
select a.first_name,
(select count(*)
from employees b
where b.first_name<=a.first_name) rownum
from employees a
(2)临时变量法(SQLite无法使用,线下测试通过,查询速度非常快)
select a.first_name
from
(select first_name, (@row:=@row+1) rownum
from employees,(select @row:=0) init) a
where a.rownum%2=1