Unity 2017 Game Optimization 读书笔记 Dynamic Graphics(2)
Lighting and Shadowing
现代的游戏中,基本没有物体能在一步就完成渲染,这是因为有光照和阴影的关系。光照和阴影的渲染在Fragment Shader中需要额外的pass。
首先要设置场景中的Shadow Casters和Shadow Receivers,Shadow Casters投射阴影,Shadow Receivers接收阴影。之后每一个Shadow Receiver渲染时,GPU就会在灯光的位置和角度渲染Shadow Caster物体,将深度信息存储到一张贴图中。这张贴图就是常说的ShadowMap,它用来实时的渲染阴影。光照渲染和阴影渲染在渲染管线中开销非常大,需要每个顶点都要提供法线信息以及额外的顶点颜色信息等。因为Fragment Shader需要多个passes完成最终的渲染,Backe End在Fill Rate(许许多多的像素都需要绘制,重新绘制和合并)和 Memory BandWidth(额外的texture需要来回获取,比如LightMaps和ShadowMaps)两方面都会压力很大,这也是为什么实时阴影是非常昂贵的,也会给Draw Call带来很大开销。
但是光照渲染和阴影渲染应该是现在游戏中最重要的两部分,的的确确能给游戏带来效果上质的提升,出色的光照和阴影效果能使得平庸的场景摇身一变。有两种渲染管线,Forward Rendering 和 Deferred Rendering,在 Rendering Edit |Project Settings | Player | Other Settings | Rendering 下可以进行设置,接下来介绍下这两部分。
Forward Rendering
同样的Shader多个Pass渲染,一共有多少个pass取决于光源的数量和光源的距离和光源的亮度。在Unity中,前向渲染规则如下:一个场景中多光照情形,按光源的重要程度排序,比如ABCD四盏灯用效果最好的逐像素方式渲染光照,DEFG用逐顶点方式渲染光照,GH则用球谐光照方式计算光照。(关于球谐光的一些知识,可以参考我的这篇文章https://blog.csdn.net/yinfourever/article/details/90205890)
Unity中正向渲染分为一个Base Pass和多个Additional Passes.
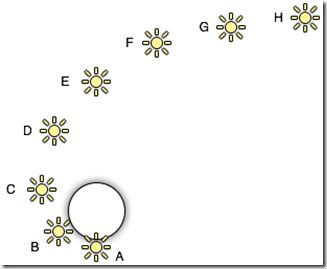
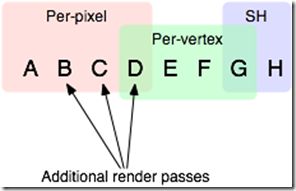
Base Pass: 用逐像素的方式渲染一个directional light, 所有球谐光和逐顶点光。在这个pass里也会计算lightmap等,directional light可以计算阴影,要注意如果使用了lightmap照亮的物体不会被球谐光照亮。
Additional Passes:每个其他需要用逐像素渲染的光源将会用一个Addtional pass渲染,默认情况下这些灯光不会有阴影除非使用了 multi_compile_fwdadd_fullshadows variant shortcut 更详细的信息可以参考Unity官方文档中关于Forward Rendering的介绍https://docs.unity3d.com/2019.2/Documentation/Manual/RenderTech-ForwardRendering.html
可以通过Edit | Project Settings| Quality | Pixel Light Count 设置像素光的数量,但是会被每个Render Mode设置为Important的Lights覆盖。
ForwardRendering当场景中有大量点光源时由于Render States需要不断的设置会产生大量Draw Call,跟场景光源数量正相关。
Deferred Rendering
Deferred Rendering通过G-Buffer工作,是将光照计算延后进行处理的一种渲染方法。
延迟渲染的优点
Deferred Rendering 的最大的优势就是将光源的数目和场景中物体的数目在复杂度层面上完全分开。也就是说场景中不管是一个三角形还是一百万个三角形,最后的复杂度不会随光源数目变化而产生巨大变化。
复杂度仅O(n+m)。
只渲染可见的像素,节省计算量。
用更少的shader。
对后处理支持良好。
在大量光源的场景优势尤其明显。
延迟渲染的缺点
内存开销较大。
读写G-buffer的内存带宽用量是性能瓶颈。
对透明物体的渲染存在问题。在这点上需要结合正向渲染进行渲染。
对多重采样抗锯齿(MultiSampling Anti-Aliasing, MSAA)的支持不友好,主要因为需开启MRT。
由于Deferred Shading的Deferred阶段是在完全基于G-Buffer的屏幕空间进行,这也导致了物体材质信息的缺失,这样在处理多变的渲染风格时就需要额外的操作。
更详细的有关渲染模式的知识请查看我的这篇文章(墙裂建议看)
https://blog.csdn.net/yinfourever/article/details/90263638
Vertex Lit Shading (legacy)
已被遗弃
Global Illumination
全局光,是烘焙光照贴图的一部分。光照贴图是提前烘焙好的,因此可以有足够的时间生成高质量的光照贴图,会节省大量Draw Call。也正是因为提前烘焙好的,所以它不是实时的,所以它对Static物体生效,动态物体需要通过LightProbe才能受到影响。LightProbe并不是像素级精准的(使用球谐光),并且会生成额外的LightProbe Maps,对Memory BandWitdh有开销,但是确实会对渲染效果带来很大的提升。
对于全局光,不仅计算直接光照的影响,还会将物体间反弹的光考虑进去。老版本的GI系统是Enlighten,它不仅提供了静态的GI,还提供了一种Pre-computed Real-time GI,可以用来制造实时渲染的假象,比如昼夜更替系统。目前Unity最新的GI系统是Progressive LightMapper。
关于这部分知识,我写过另一篇文章帮助理解https://blog.csdn.net/yinfourever/article/details/105151596
Multithreaded Rendering
多线程渲染在大多数平台中是被默认开启的,比如PC或者其他CPU支持多核的。对于Android,Edit | Project Settings | Player | Other Settings |Multithreaded Rendering可以进行设置,对于IOS可以在Edit | Project Settings | Player| Other Settings | Graphics API设置。
对于场景中的一个物体,要进行渲染的话有三件事需要处理。决定这个物体是否需要渲染,生成渲染指令,通过相关图形API发送指令到GPU。如果没有Multithreaded Rendering,这些工作都要由CPU主线程承担,开启Multithreaded Rendering,把渲染指令推送给GPU的工作将由render线程承担,其他例如剪裁等工作将由其他一些worker 线程承担。这给CPU主线程大大减压,可以给物理运算以及脚本逻辑运算留出更多空间。
开启Multithreaded Rendering后,关于CPU-Bound会有一些影响,没开启的时候,所有工作都是由CPU主线程做,因此无论那部分性能的优化都会对CPU-Bound带来改善。开启Multithreaded Rendering后,因为工作被分散到各个线程,即使对主线程做出一些优化,对CPU-Bound的减轻程度可能也会变得很小。
是否开启Multithreaded Rendering对GPU没影响,GPU已经总是用多线程渲染。
Low-level rendering APIs
通过CommandBuffer可以使用高级别的API对渲染管线进行一些控制,但是可用的内容和范围还是太少,因此可以用C++代码直接控制图形API,将C++代码打成一个Plugin,hook到Unity的渲染管线中。
当然,现在Unity已经推出了SRP(可编程渲染管线),已经可以完全自定义渲染管线,十分方便,因此这一小节提到的方法可能已经基本不会使用了。关于SRP,可以看我这篇文章https://blog.csdn.net/yinfourever/article/details/89364090
Detecting performance issues
Profiling rendering issues
通过Unity的Profiler 可以快速定位是瓶颈是在CPU和是GPU.
CPU-bound
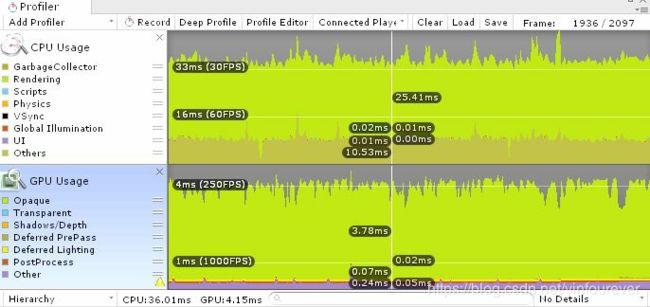
下图是一个CPU瓶颈的例子,这个场景有成千的简单Cube物体,但是没有使用batching并且有阴影的渲染,这导致CPU需要生成大量的Draw Call,但是GPU实际上渲染任务很少。
如何定位问题的呢?下图中CPU平均需要25ms处理一个循环,而GPU只需要4ms以内,这就说明了瓶颈在CPU端,应该想办法使用一些优化CPU端的技术。
GPU-bound
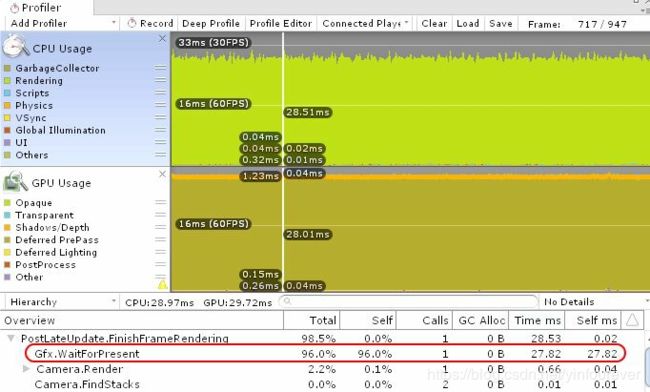
下图的测试条件为很少的Draw Call,但是使用非常复杂的Shader进行渲染。如果想测试是否是GPU端的瓶颈,需要注意的是要关掉V Sync(垂直同步),不然会影响Profiler。
从图中我们可以看到CPU和GPU都消耗29ms左右,但是再深层次查看一下,CPU的时间都花在了 Gfx.WaitForPresent函数上,这是在CPU在等待GPU完成这帧操作而浪费掉的时间,即使开启多线程渲染,CPU也必须是等待渲染管线完成后才能开始下一帧。Gfx.WaitForPresent也同时会被Vertical Sync使用,因此要关掉Vertical Sync来避免干扰。
Brute-force testing
如果从Profiler中没办法定位问题,我们可能就得使用蛮力测试。比如从场景中去除一些物体,看看性能有没有很大改善,如果很小的改动会带来很大提升,那其就定位了问题。
降低屏幕分辩率和降低贴图的分辩率来进行测试是两种定位瓶颈是FillRate还是Memory Bandwidth的好方法。
降低屏幕分辨率可以有效降低Frill Rate的消耗(比如2560 x 1440 降为 800 x 600大概会降低8倍),如果性能有很大的提升,说明Fill Rate有可能是我们应该首要考虑优化的地方。
类似的,如果降低贴图的分辨率后性能提升非常大,则说明Memory BandWidth可能是瓶颈。
GPU的瓶颈通常是FillRate和Memory Bandwidth,很少是Front End的原因,Vertex Shader如果有问题,只能是因为传入了太多几何体需要处理或者使用了很复杂的Geometry Shader。