达观杯文本智能处理(五)——LightGBM理论与实践
达观杯文本智能处理(五)——LightGBM理论与实践
- 一、LightGBM模型
- 1.GBDT存在的几个问题
- 2.引入LightGBM
- 二、优势
- 三、lightGBM调参
- 四、lightGBM模型实践
- 参考文献
一、LightGBM模型
1.GBDT存在的几个问题
如何减少数据量
常用的减少训练数据量的方式是down sample。例如在[5]中,权重小于阈值的数据会被过滤掉,SGB在每一轮迭代中用随机的子集训练弱学习器;在[6]中,采样率会在训练过程中动态调整。但是,所有这些工作除了SGB外都是基于AdaBoost的,并且由于GBDT没有数据实例的权重,所以不能直接运用到GBDT上。虽然SGB可以应用到GBDT,但是它这种做法对acc影响太大了。
如何减少特征
类似的,为了减少特征的数量,需要过滤若特征[22, 23, 7, 24]。这通常用PCA和projection pursuit来做。可是,这些方法高度依赖一个假设,那就是特征包含相当多的冗余的信息。而这个假设在实践中通常不成立(因为通常特征都被设计为具有独特作用的,移除了哪个都可能对训练的acc有影响)
关于稀疏的数据
现实应用中的大规模数据通常是相当稀疏的。使用pre-sorted algorithm的GBDT可以通过忽略值为0的特征来降低训练的开销。而使用histogram-based algorithm的GBDT没有针对稀疏数据的优化方案,因为histogram-based algorithm无论特征值是否为0,都需要检索特征的bin值,所以它能够有效地利用这种稀疏特性。
为了解决上面的这些问题,我们提出了两个新的技术——GOSS和EFB。
2.引入LightGBM
-
LightGBM是微软2017年新提出的,比Xgboost更强大、速度更快的模型,性能上有很大的提升,与传统算法相比具有的优点: *更快的训练效率
*低内存使用 *更高的准确率 *支持并行化学习 *可处理大规模数据 *原生支持类别特征,不需要对类别特征再进行0-1编码这类的 -
LightGBM一大的特点是在传统的GBDT基础上引入了两个 新技术和一个改进:
-
(1)Gradient-based One-Side Sampling(GOSS)技术是去掉了很大一部分梯度很小的数据,只使用剩下的去估计信息增益,避免低梯度长尾部分的影响。由于梯度大的数据在计算信息增益的时候更重要,所以GOSS在小很多的数据上仍然可以取得相当准确的估计值。
-
(2)Exclusive Feature Bundling(EFB)技术是指捆绑互斥的特征(i.e.,他们经常同时取值为0),以减少特征的数量。但对互斥特征寻找最佳的捆绑方式是一个NP难问题,当时贪婪算法可以取得相当好的近似率(因此可以在不显著影响分裂点选择的准确性的情况下,显著地减少特征数量)。
-
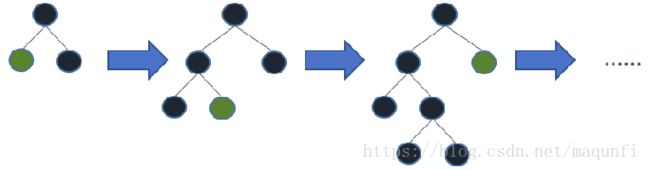
(3)在传统GBDT算法中,最耗时的步骤是找到最优划分点,传统方法是Pre-Sorted方式,其会在排好序的特征值上枚举所有可能的特征点,而LightGBM中会使用histogram算法替换了传统的Pre-Sorted。基本思想是先把连续的浮点特征值离散化成k个整数,同时构造出图8所示的一个宽度为k的直方图。最开始时将离散化后的值作为索引在直方图中累积统计量,当遍历完一次数据后,直方图累积了离散化需要的统计量,之后进行节点分裂时,可以根据直方图上的离散值,从这k个桶中找到最佳的划分点,从而能更快的找到最优的分割点,而且因为直方图算法无需像Pre-Sorted那样存储预排序的结果,而只是保存特征离散过得数值,所以使用直方图的方式可以减少对内存的消耗。
-
Pre-sorted 算法需要 O(data) 次的计算
Histogram 算法只需要计算 O(bins) 次, 并且 bins 远少于data(直方图仍然需要 O(#data) 次来构建直方图, 而这仅仅包含总结操作,只是第一次做data此即可)

二、优势
相比XGboost,其更强大的原因是:
-
histogram算法替换了传统的Pre-Sorted,某种意义上是牺牲了精度换取速度,直方图作差构建叶子直方图更有创造力(直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点[利于计算分割打分]。)。
-
带有深度限制的按叶子生长 (leaf-wise) 算法代替了传统的(level-wise) 决策树生长策略,提升精度,同时避免过拟合危险(不太深了)。
-
内存做了优化,内存中仅仅需要保存直方图数值,而不是之前的所有数据,另外如果直方图比较小的时候,我们还可以使用保存uint8的形式保存来训练数据。
-
额外的优化还有Cache命中率优化、多线程优化。 lightGBM优越性:速度快,代码清晰,占用内存小。lightGBM可以在更小的代价下控制分裂树。有更好的缓存利用,是带有深度限制的按叶子生长的策略,使用了leaf-wise策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后进行分裂,不断的进行循环下去,而lead-wise(智能)算法的缺点是可能生长出比较深的决策树,导致过拟合问题,为了解决过拟合问题,我们会在LightGBM中会对leaf-wise之上增加一个最大深度的限制,在保持高效率的同时防止过拟合。
三、lightGBM调参
所有的参数含义,参考:http://lightgbm.apachecn.org/cn/latest/Parameters.html
调参过程:
(1)num_leaves
LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
大致换算关系:num_leaves = 2^(max_depth)
(2)样本分布非平衡数据集:可以param[‘is_unbalance’]=’true’
(3)Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction
(4)min_data_in_leaf、min_sum_hessian_in_leaf
四、lightGBM模型实践
1.准备数据
##读取数据
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
train_data=pd.read_csv('datalab/14936/train_set.csv',nrows=5000)
##删除‘article’
train_data.drop(columns='article', inplace=True)
##TF-IDF文本处理
tfidf=TfidfVectorizer()
x_train=tfidf.fit_transform(train_data['word_seg'])
##将训练集拆分成训练集和测试集
#x:要划分的样本集 y:要划分的样本结果
#test_size:测试集占比 random_state:随机数的种子
y=train_data['class']
x_train,x_test,y_train,y_test=train_test_split(x_train,y,test_size=0.3,random_state=123)
2.lightgbm模型训练与预测
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print('Start training...')
# 创建模型,训练模型
estimator=lgb.sklearn.LGBMClassifier(num_leaves=31,learning_rate=0.05,n_estimators=20)
estimator.fit(x_train,y_train) #x_train和y_train 是numpy或pandas数据类型即可
print('Start predicting...')
y_pred = estimator.predict(x_test)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
#f1_score
label = []
for i in range(1, 20):
label.append(i)
f1 = f1_score(y_test, y_pred, labels=label, average='micro')
print('lightgbm模型的The F1 Score: ' + str("%.2f" % f1))
结果:

3.lightgbm参数调整
# 网格搜索,参数优化
estimator =lgb.sklearn.LGBMClassifier(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [30, 40]
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
结果:
![]()
4.利用优化参数进行训练
# 用最优参数('learning_rate': 0.1, 'n_estimators': 40)训练模型
estimator=lgb.sklearn.LGBMClassifier(num_leaves=31,learning_rate=0.1,n_estimators=40)
estimator.fit(x_train,y_train) #x_train和y_train 是numpy或pandas数据类型即可
print('Start predicting...')
y_pred = estimator.predict(x_test)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
#f1_score
label = []
for i in range(1, 20):
label.append(i)
f1 = f1_score(y_test, y_pred, labels=label, average='micro')
print('lightgbm模型的The F1 Score: ' + str("%.2f" % f1))
结果:

- 从结果来看,进行参数调优之后该模型f1_score提升了0.05。因为lightgbm的参数比较多,本次实践只选取了两个参数进行调整,效果可能不太明显。若想提升模型效果,可进行其他参数调优,且增加训练数据量。
参考文献
原文:CSDN https://blog.csdn.net/luanpeng825485697/article/details/80236759
原文:CSDN https://blog.csdn.net/maqunfi/article/details/82219999