谈笑间学会大数据-Hive查询SQL
Hive查询SQL
目录
Hive查询SQL
使用正则表达式来指定列
算术运算符
使用函数
数学函数
聚合函数
表生产函数
其他内置函数列表如下
什么情况下会避免进行MapReduce
谓词操作符
关于浮点数比较
Like和Rlike
这篇博客呢,不想说太多基础,有些东西像MySQL类似的语法,简单的select...from...这种大家都会的,我就不bb了~
原则上:大多数情况是,MySQL支持的SQL语法,在Hive中也同样适用...
使用正则表达式来指定列
select
age,
`name.*`
from test_stu_3
;可能会报错哦~ 如果报错,请设置参数:set hive.support.quoted.identifiers=none;
SQL执行以后的大致效果

算术运算符
Hive中支持所有典型的算术运算符。下表描述了具体的细节。
| 运算符 | 类型 | 描述 |
| A + B | 数值 | A和B相加 |
| A - B |
数值 | A 减去 B |
| A * B | 数值 | A 乘以 B |
| A / B | 数值 | A 除以 B |
| A % B | 数值 | A 除以 B的余数 |
| A & B | 数值 | A 和 B 按位取与 |
| A | B | 数值 | A 和 B 按位取或 |
| A ^ B | 数值 | A 和 B 按位异或 |
| ~ A | 数值 | A 按位取反 |
算术运算符接受任意的数值类型。不过,如果数据类型不同,那么两种类型中值范围较小的那个数据类型将转换为其他范围更广的数据类型。(范围更广在某种意义上就是指一个类型具有更多的字节从而可以容纳更大范围的值。)例如,对于INT和BIGINT运算,INT会将类型转换提升为BIGINT。对于INT和FLOAT运算,INT将提升为FLOAT。
当进行算术运算时,用户需要注意数据溢出或数据下溢问题。Hive遵循的是底层Java中数据类型的规则,因此当溢出或下溢发生时计算结果不会自动转换为更广泛的数据类型。
乘法和除法最有可能会引发这个问题。用户需要注意所使用的数值数据的数值范围,并确认实际数据是否接近表模式中定义的数据类型所规定的数值范围上限或者下限,还需要确认人们可能对这些数据进行什么类型的计算。
如果用户比较担心溢出和下溢,那么可以考虑在表模式中定义使用范围更广的数据类型。不过这样做的缺点是每个数据值会占用更多额外的内存。用户也可以使用特定的表达式将值转换为范围更广的数据类型。
使用函数
数学函数

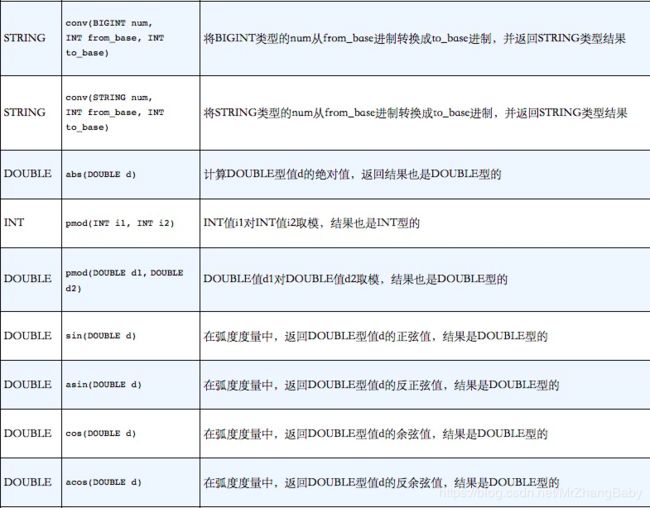

需要注意的是函数floor、round和ceil(“向上取整”)输入的是DOUBLE类型的值,而返回值是BIGINT类型的,也就是将浮点型数转换成整型了。在进行数据类型转换时,这些函数是首选的处理方式,而不是使用前面我们提到过的cast类型转换操作符。
同样地,也存在基于不同的底(例如十六进制)将整数转换为字符串的函数。
聚合函数
聚合函数是一类比较特殊的函数,其可以对多行进行一些计算,然后得到一个结果值。更确切地说,这是用户自定义聚合函数,这类函数中最有名的两个例子就是count和avg。函数count用于计算有多少行数据(或者某列有多少值),而函数avg可以返回指定列的平均值。


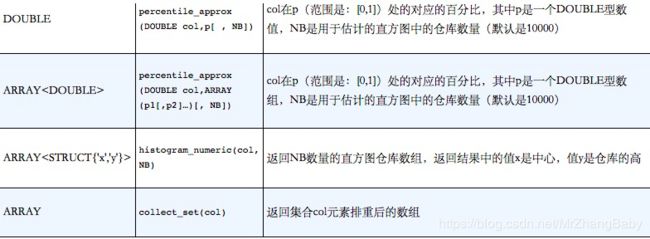
表生产函数
与聚合函数“相反的”一类函数就是所谓的表生成函数,其可以将单列扩展成多列或者多行。然后列举出Hive目前所提供的一些内置表生成函数。


其他内置函数列表如下

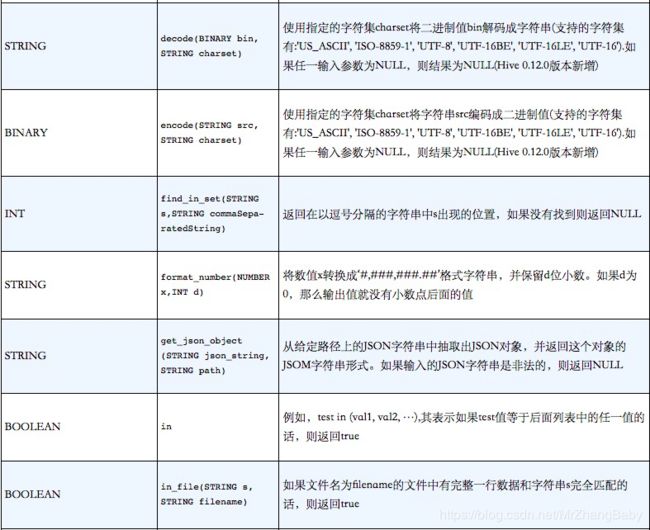






需要注意的是,和时间相关的函数输入的是整型或者字符串类型参数。对于Hivev0.8.0版本,这些函数同样接受TIMESTAMP类型参数,同时为了向后兼容,它们还将继续支持之前的整型和字符串类型参数。
什么情况下会避免进行MapReduce
对于查询,如果用户进行过执行的话,那么可能会注意到大多数情况下查询都会触发一个MapReduce任务(job)。Hive中对某些情况的查询可以不必使用MapReduce,也就是所谓的本地模式,例如:
SELECT * FROM xxx;在这种情况下,Hive可以简单地读取xxx对应的存储目录下的文件,然后输出格式化后的内容到控制台。对于WHERE语句中过滤条件只是分区字段这种情况(无论是否使用LIMIT语句限制输出记录条数),也是无需MapReduce过程的。
SELECT * FROM xxx WHERE country='US' AND state='CA' LIMIT 100 ;此外,如果属性hive.exec.mode.local.auto的值设置为true的话,Hive还会尝试使用本地模式执行其他的操作:
set hive.exec.mode.local.auto=true ;否则,Hive使用MapReduce来执行其他所有的查询。
最好将set hive.exec.mode.local.auto=true;这个设置增加到你的$HOME/.hiverc配置文件中,默认加载~
谓词操作符


关于浮点数比较
浮点数比较的一个常见陷阱出现在不同类型间作比较的时候(也就是FLOAT和DOUBLE比较)。思考下面这个对于员工表的查询语句,该语句将返回员工姓名、工资和联邦税,过滤条件是薪水的减免税款超过0.2(20%):

为什么deductions['FederalTaxes']=0.2的记录也被输出了?
这是个Hive的Bug吗?确实有个issue是关于这个问题的,但是其实际上反映了内部是如何进行浮点数比较的,这个问题几乎影响了在现在数字计算机中所有使用各种各样编程语言编写的软件(请参阅https://issues.apache.org/jira/browse/HIVE2586)。
当用户写一个浮点数时,比如0.2,Hive会将该值保存为DOUBLE型的。我们之前定义deductions这个map的值的类型是FLOAT型的,这意味着Hive将隐式地将税收减免值转换为DOUBLE类型后再进行比较。
这样应该是可以的,对吗?事实上,这样行不通。这里解释下为什么不能。数字0.2不能够使用FLOAT或DOUBLE进行准确表示。(参阅http://docs.oracle.com/cd/E1995701/8063568/ncg_goldberg.html,深入探讨浮点数问题)。在这个例子中,0.2的最近似的精确值应略大于0.2,也就是0.2后面的若干个0后存在非零的数值。
为了简化一点,实际上我们可以说0.2对于FLOAT类型是0.2000001,而对于DOUBLE类型是0.200000000001。这是因为一个8个字节的DOUBLE值具有更多的小数位(也就是小数点后的位数)。当表中的FLOAT值通过Hive转换为DOUBLE值时,其产生的DOUBLE值是0.200000100000,这个值实际要比0.200000000001大。这就是为什么这个查询结果像是使用了>=而不是>了。
这个问题并非仅仅存在于Hive中或Java中(Hive是使用Java实现的)。而是所有使用IEEE标准进行浮点数编码的系统中存在的一个普遍的问题。
然而,Hive中有两种规避这个问题的方法:
- 定义对应的字段类型为DOUBLE而不是FLOAT
- 是显式地指出0.2为FLOAT类型的,通过cast函数(cast( xxx as float))
温馨提醒:
所有和钱相关的都避免使用浮点数。对浮点数进行比较时,需要保持极端谨慎的态度。要避免任何从窄类型隐式转换到更广泛类型的操作。
Like和Rlike
like的使用详解
- 语法规则:格式是A like B,其中A是字符串,B是表达式,表示能否用B去完全匹配A的内容,换句话说能否用B这个表达式去表示A的全部内容,注意这个和rlike是有区别的。返回的结果是True/False. B只能使用简单匹配符号 _和%,”_”表示任意单个字符,字符”%”表示任意数量的字符,like的匹配是按字符逐一匹配的,使用B从A的第一个字符开始匹配,所以即使有一个字符不同都不行。
- 操作类型: strings
- 使用描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B 的正则语法,则为TRUE;否则为FALSE。尤其注意NULL值的匹配,返回的结果不是FALSE和TRUE,而是null,其实除了is null ,is not null,其他的关系运算符只要碰到null值出现,结果都是返回NULL,而不是TRUE/FALSE。
操作样例
hive (default)> select 'abcde' like 'abc';
OK
false
hive (default)> select 'abcde' like 'abc__';
OK
true
hive (default)> select 'abcde' like 'abc%';
OK
true
hive (default)> select 'abcde' like '%abc%';
OK
true
hive (default)> select 'abcde' like 'bc%';
OK
false
hive (default)> select 'abcde' like '_bc%';
OK
true
hive (default)> select 'abcde' like '_b%';
OK
true注意事项:
否定比较时候用NOT A LIKE B(使用A NOT LIIKE B也可以),结果与like的结果时相对的。当然前提要排除出现null问题,null值这个奇葩除外。
RLIKE比较符使用详解
- 1.语法规则:A RLIKE B ,表示B是否在A里面即可。而A LIKE B,则表示B是否是A,B中的表达式可以使用JAVA中全部正则表达式,具体正则规则参考java,或者其他标准正则语法。
- 2.操作类型: strings
- 3.使用描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合JAVA正则表达式B的正则语法,则为TRUE;否则为FALSE。
样例操作
hive (default)> select 'foobar' like 'foo';
OK
false
hive (default)> select 'foobar' like 'foo';
OK
false
hive (default)> select 'foobar' like 'oo%';
OK
false
hive (default)> select 'foobar' rlike 'foo';
OK
true
hive (default)> select 'foobar' rlike '.oo.*';
OK
true参考:Hive编程指南